ZeroSpeech TTS without T
1.0.0
git clone [email protected]:andi611/ZeroSpeech-TTS-without-T.gitcd ZeroSpeech-TTS-without-TPython 3をインストールします。
プラットフォームに応じて、 Pytorchの最新バージョンをインストールします。パフォーマンスを向上させるには、実行可能な場合はGPUサポート(CUDA)でインストールします。このコードは、Pytorch 0.4以降で動作します。
Zerospeechデータセットをダウンロードします。
wget https://download.zerospeech.com/2019/english.tgz
tar xvfz english.tgz -C data
rm -f english.tgz
wget https://download.zerospeech.com/2019/surprise.zip
# Go to https://download.zerospeech.com and accept the licence agreement
# to get the password protecting the archive
unzip surprise.zip -d data
rm -f surprise.zip
データセットを~/ZeroSpeech-TTS-without-T/dataに解凍した後、データツリーは次のようになります。
|- ZeroSpeech-TTS-without-T
|- data
|- english
|- train
|- unit
|- voice
|- test
|- surprise
|- train
|- unit
|- voice
|- test
データセットとサンプルモデル対応のインデックスファイルを事前に処理します。
python3 main.py --preprocess —-remake
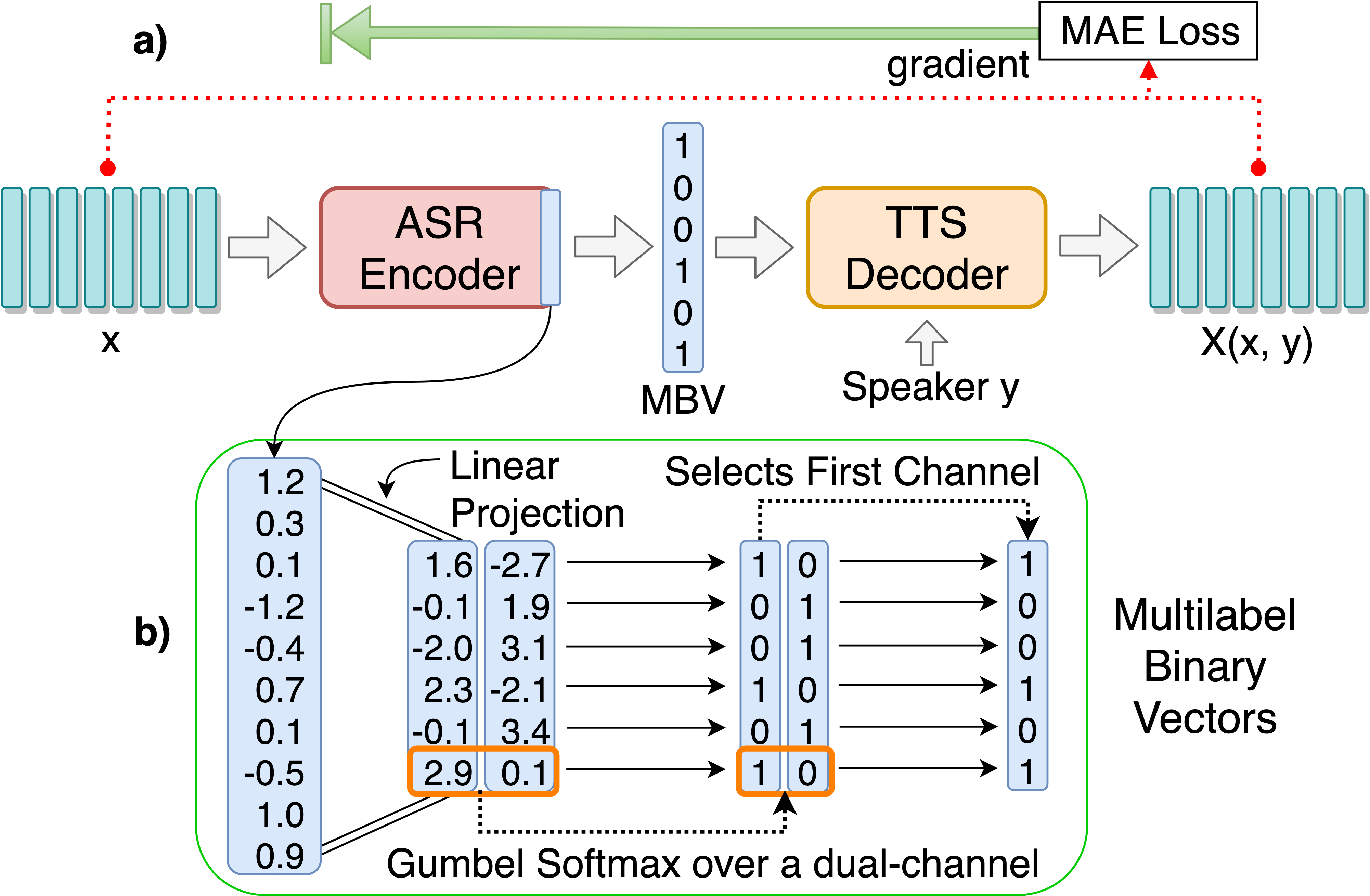
離散言語ユニットの発見のためのASR-TTSオートエンコーダーモデルをトレーニングします。
python3 main.py --train_ae
調整可能なハイパーパラメーターは、HPS/Zerospeech.jsonにあります。これらのパラメーターと設定を調整して、ファイルを編集することで、このプロジェクトにはデフォルトのハイパーパラメーターが推奨されます。
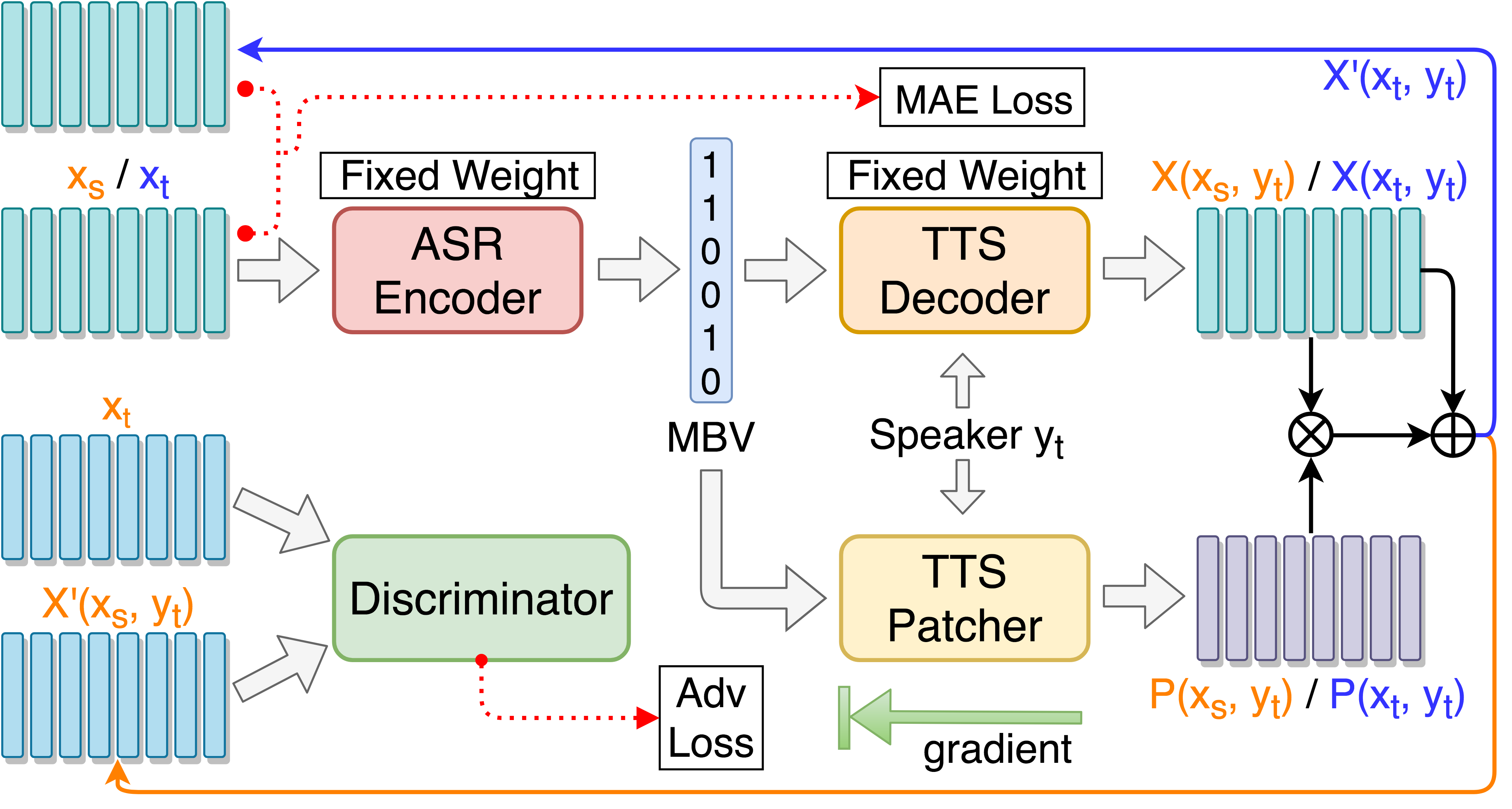
音声変換パフォーマンスのためのTTSパッチターをトレーニングする:
python3 main.py --train_p --load_model --load_train_model_name=model.pth-ae-400000
ターゲットガイド付き敵対的トレーニングを備えたTTSパッチターをトレーニング:
python3 main.py --train_tgat --load_model --load_train_model_name=model.pth-ae-400000
テンソルボードで監視する(オプション)
tensorboard --logdir='path to log dir'
or
python3 -m tensorboard.main --logdir='path to log dir'
単一のスピーチでテスト::
python3 main.py --test_single --load_test_model_name=model.pth-ae-200000
「Synthesis.txt」でテストし、再同定されたオーディオファイルを生成します::
python3 main.py --test --load_test_model_name=model.pth-ae-200000
test/およびエンコードファイルを生成するすべてのテスト::
python3 main.py --test_encode --load_test_model_name=model.pth-ae-200000
ASR-TTSオートエンコーダーのみでテストする場合、 --enc_onlyを追加:
python3 main.py --test_single --load_test_model_name=model.pth-ae-200000 --enc_only
python3 main.py --test --load_test_model_name=model.pth-ae-200000 --enc_only
python3 main.py --test_encode --load_test_model_name=model.pth-ae-200000 --enc_only
--dataset=surpriseを使用してデフォルトの代替セットに切り替えるには、データツリー構造が提案されている場合、すべてのパスが自動的に処理されます。例えば: python3 main.py --train_ae --dataset=surprise
--load_train_model_name=model.pth-ae-400000-128-multi-1024-english
--ckpt_dir=./ckpt_englishまたは--ckpt_dir=./ckpt_surpriseデフォルトで)。 --load_test_model_name=model.pth-ae-400000-128-multi-1024-english (by name)
--ckpt_pth=ckpt/model.pth-ae-400000-128-multi-1024-english (direct path)
128-multi-1024モデルがロードされている場合、 seg_lenとenc_sizeそれぞれ128と1024に設定する必要があります。 aeモデルがロードされている場合、 main.py実行するときに引数--enc_onlyを使用する必要があります(テストセクションで4を参照)。 @article{Liu_2019,
title={Unsupervised End-to-End Learning of Discrete Linguistic Units for Voice Conversion},
url={http://dx.doi.org/10.21437/interspeech.2019-2048},
DOI={10.21437/interspeech.2019-2048},
journal={Interspeech 2019},
publisher={ISCA},
author={Liu, Andy T. and Hsu, Po-chun and Lee, Hung-Yi},
year={2019},
month={Sep}
}


