ZeroSpeech TTS without T
1.0.0
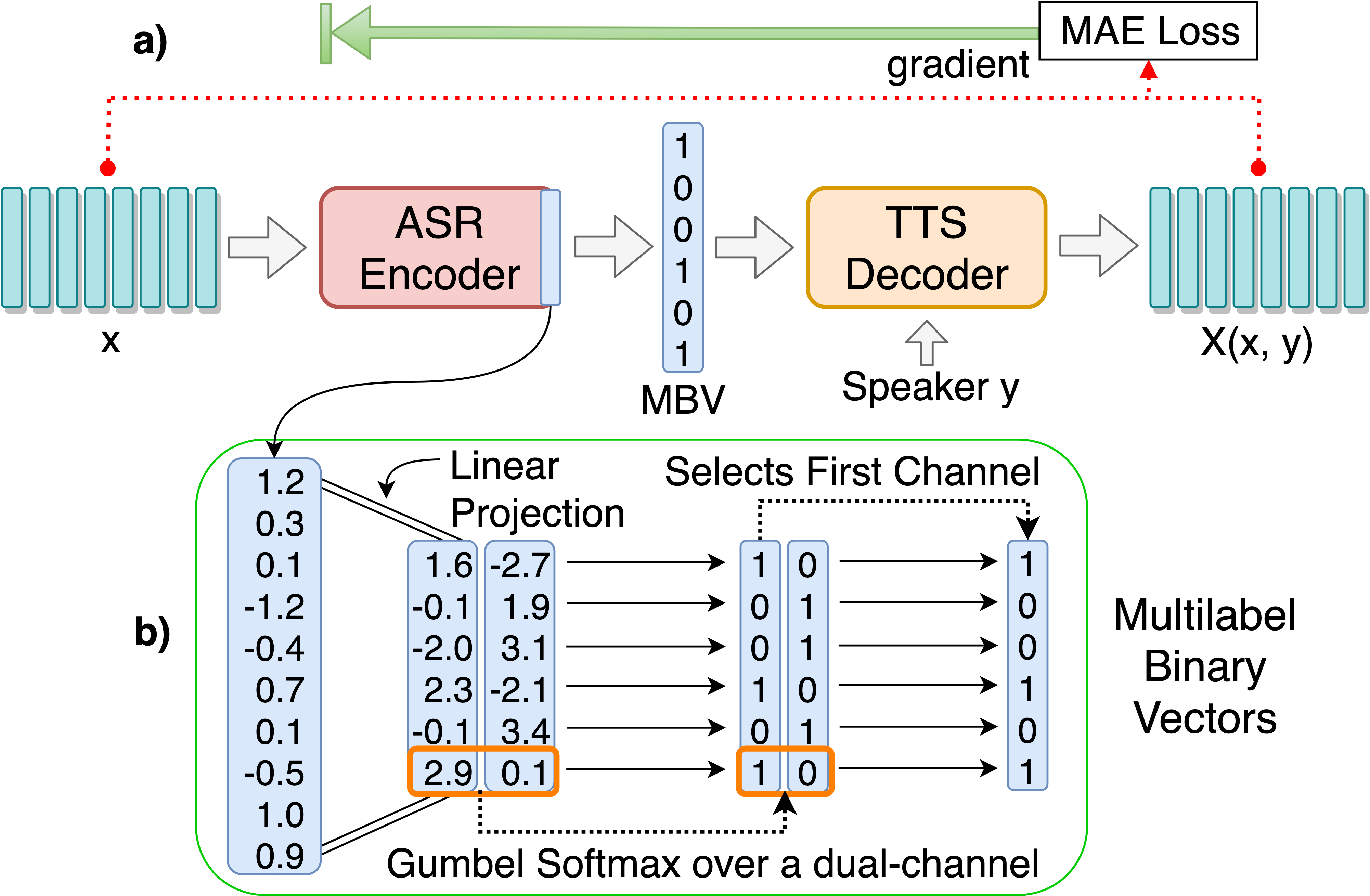
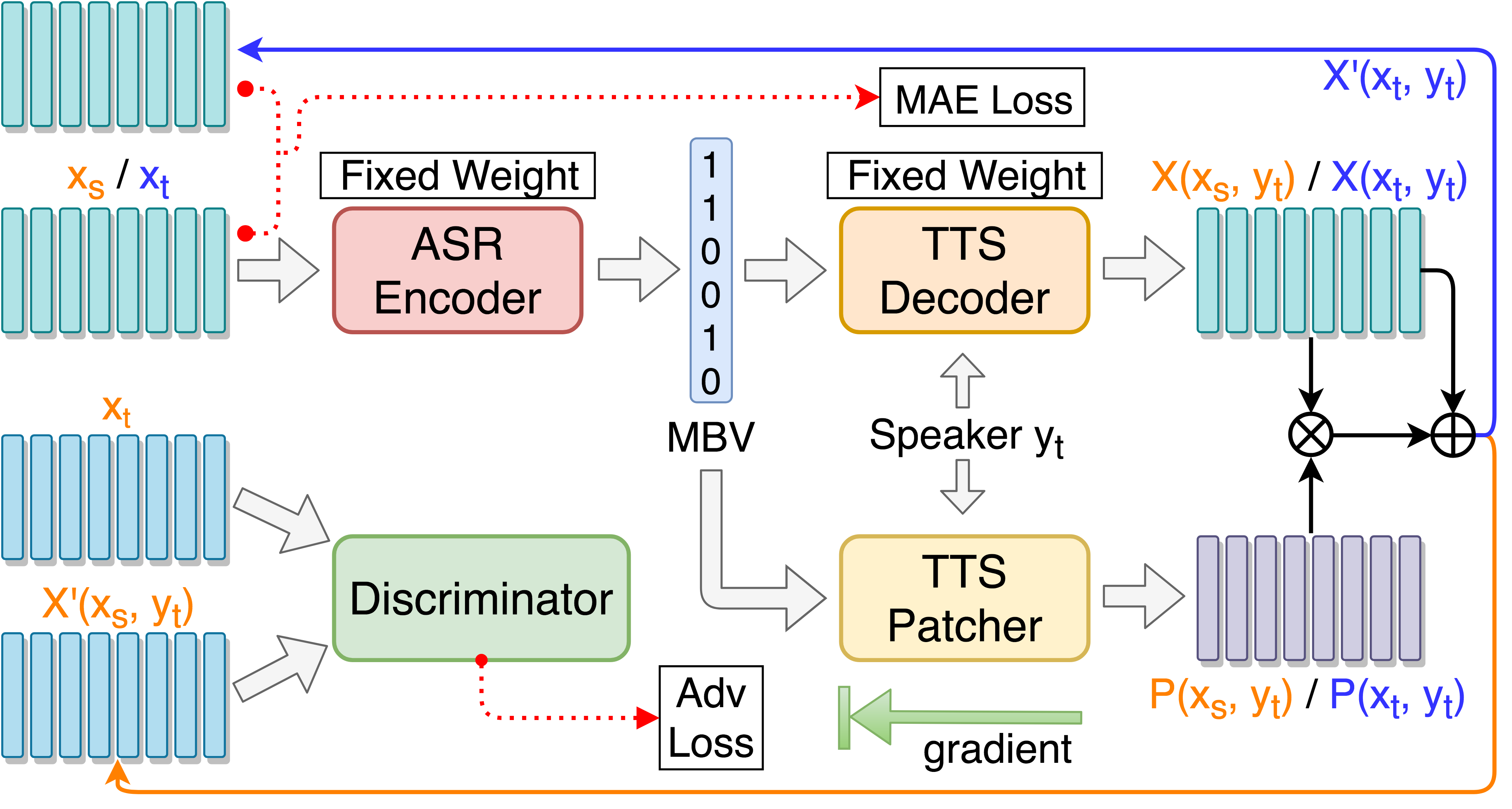
git clone [email protected]:andi611/ZeroSpeech-TTS-without-T.gitcd ZeroSpeech-TTS-without-TPasang Python 3.
Instal versi terbaru Pytorch sesuai dengan platform Anda. Untuk kinerja yang lebih baik, instal dengan dukungan GPU (CUDA) jika layak. Kode ini berfungsi dengan Pytorch 0.4 dan yang lebih baru.
Unduh dataset Zerospeech.
wget https://download.zerospeech.com/2019/english.tgz
tar xvfz english.tgz -C data
rm -f english.tgz
wget https://download.zerospeech.com/2019/surprise.zip
# Go to https://download.zerospeech.com and accept the licence agreement
# to get the password protecting the archive
unzip surprise.zip -d data
rm -f surprise.zip
Setelah membongkar dataset menjadi ~/ZeroSpeech-TTS-without-T/data , pohon data akan terlihat seperti ini:
|- ZeroSpeech-TTS-without-T
|- data
|- english
|- train
|- unit
|- voice
|- test
|- surprise
|- train
|- unit
|- voice
|- test
Preprocess Dataset dan sampel file indeks siap-model:
python3 main.py --preprocess —-remake
Latih model autoencoder ASR-TTS untuk penemuan unit linguistik diskrit:
python3 main.py --train_ae
Hyperparameter yang dapat disetel dapat ditemukan di HPS/Zerospeech.json. Anda dapat menyesuaikan parameter ini dan pengaturan dengan mengedit file, hyperparameter default direkomendasikan untuk proyek ini.
Latih TTS Patcher untuk meningkatkan kinerja konversi suara:
python3 main.py --train_p --load_model --load_train_model_name=model.pth-ae-400000
Latih TTS Patcher dengan pelatihan permusuhan yang dipandu target:
python3 main.py --train_tgat --load_model --load_train_model_name=model.pth-ae-400000
Monitor dengan Tensorboard (Opsional)
tensorboard --logdir='path to log dir'
or
python3 -m tensorboard.main --logdir='path to log dir'
Tes pada satu pidato ::
python3 main.py --test_single --load_test_model_name=model.pth-ae-200000
Tes pada 'sintesis.txt' dan menghasilkan file audio yang disintesis ::
python3 main.py --test --load_test_model_name=model.pth-ae-200000
Tes pada semua pidato pengujian yang test/ dan hasilkan file pengkodean ::
python3 main.py --test_encode --load_test_model_name=model.pth-ae-200000
Tambahkan --enc_only jika hanya pengujian dengan Autoencoder ASR-TTS:
python3 main.py --test_single --load_test_model_name=model.pth-ae-200000 --enc_only
python3 main.py --test --load_test_model_name=model.pth-ae-200000 --enc_only
python3 main.py --test_encode --load_test_model_name=model.pth-ae-200000 --enc_only
--dataset=surprise untuk beralih ke set alternatif default, semua jalur ditangani secara otomatis jika struktur pohon data ditempatkan seperti yang disarankan. Misalnya: python3 main.py --train_ae --dataset=surprise
--load_train_model_name=model.pth-ae-400000-128-multi-1024-english
--ckpt_dir=./ckpt_english atau --ckpt_dir=./ckpt_surprise secara default). --load_test_model_name=model.pth-ae-400000-128-multi-1024-english (by name)
--ckpt_pth=ckpt/model.pth-ae-400000-128-multi-1024-english (direct path)
128-multi-1024 sedang dimuat, seg_len dan enc_size harus diatur masing-masing ke 128 dan 1024. Jika model ae sedang dimuat, argumen --enc_only harus digunakan saat menjalankan main.py (lihat 4. Di bagian pengujian). @article{Liu_2019,
title={Unsupervised End-to-End Learning of Discrete Linguistic Units for Voice Conversion},
url={http://dx.doi.org/10.21437/interspeech.2019-2048},
DOI={10.21437/interspeech.2019-2048},
journal={Interspeech 2019},
publisher={ISCA},
author={Liu, Andy T. and Hsu, Po-chun and Lee, Hung-Yi},
year={2019},
month={Sep}
}


