ZeroSpeech TTS without T
1.0.0
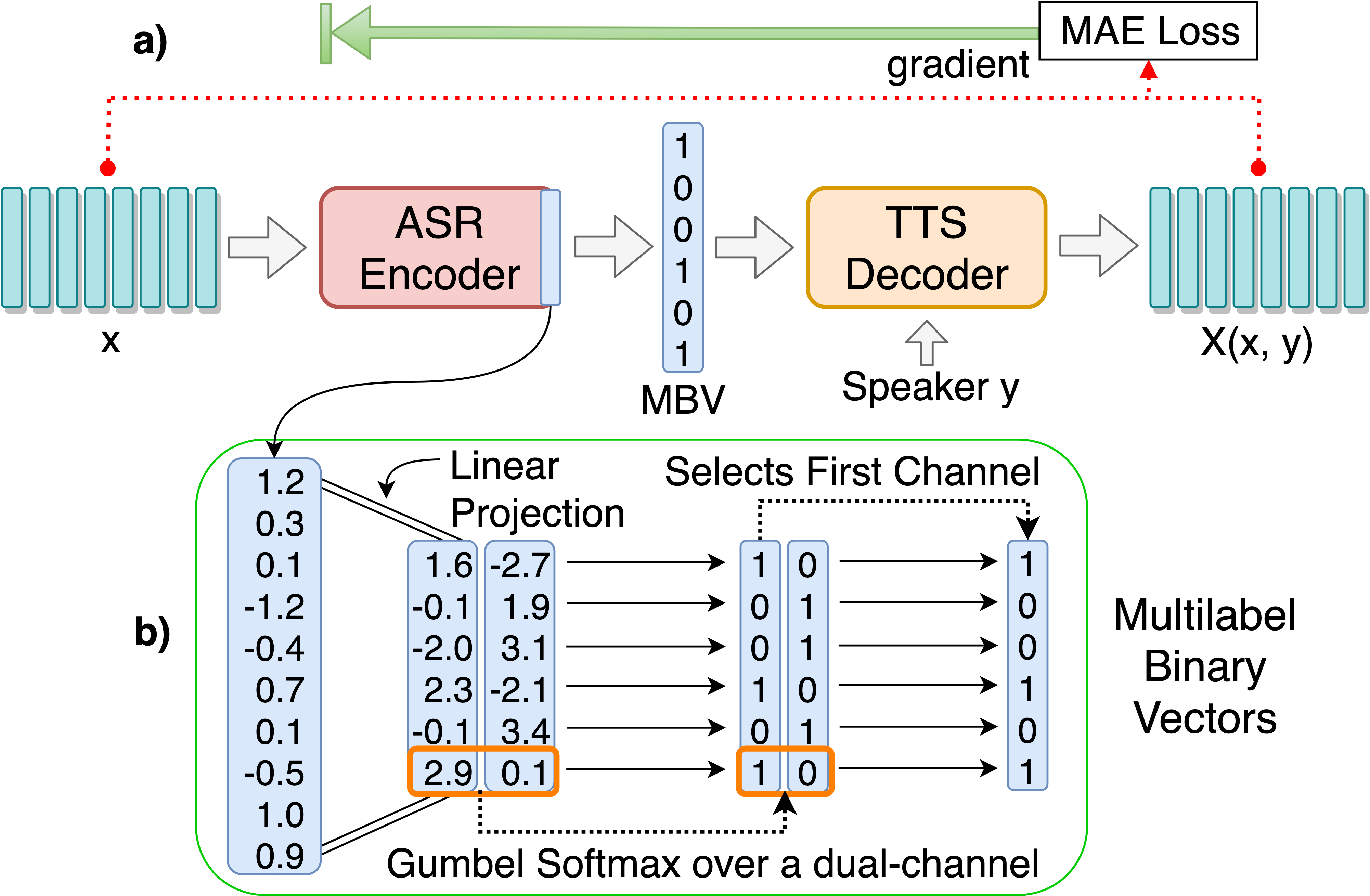
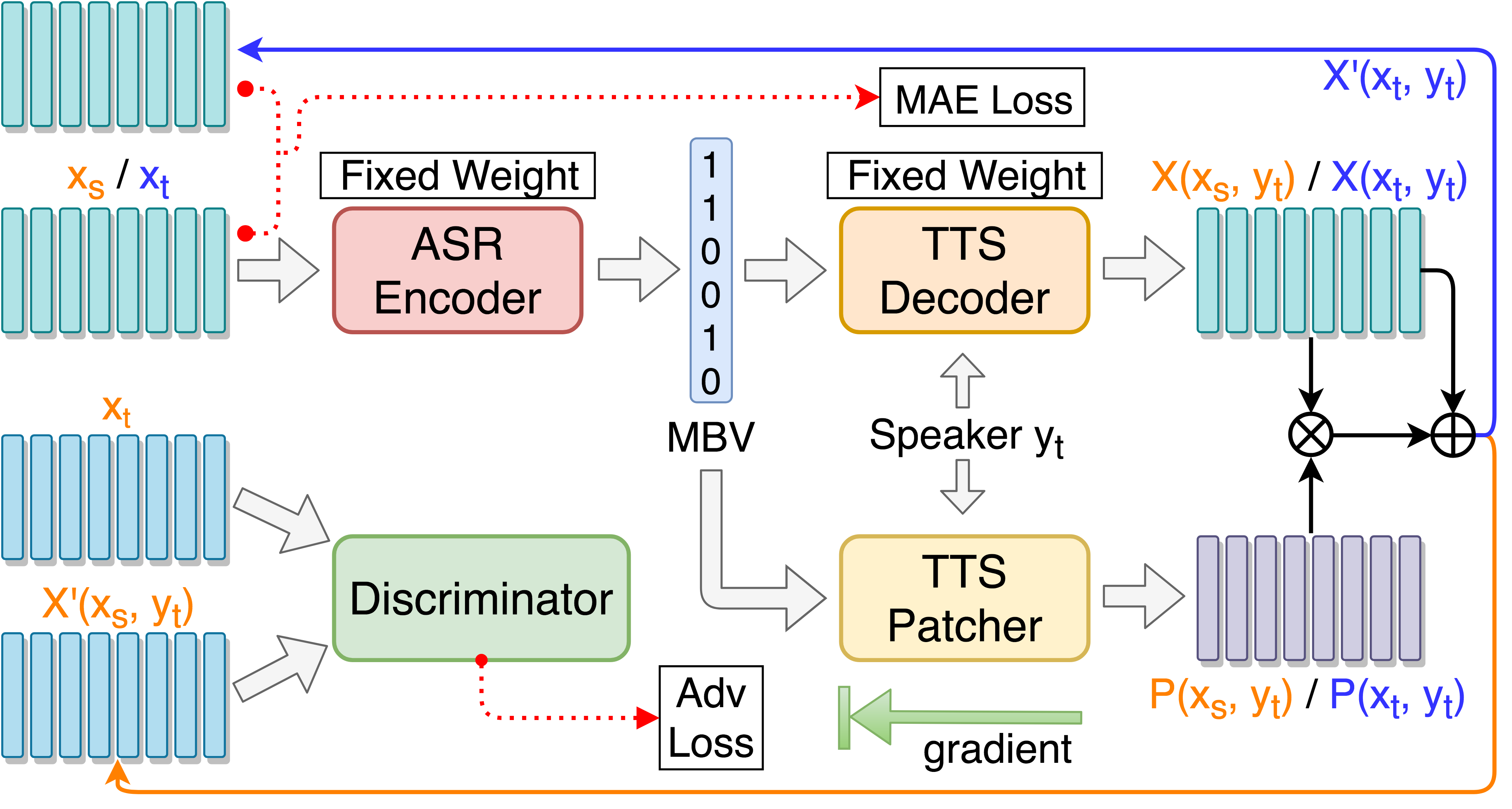
git clone [email protected]:andi611/ZeroSpeech-TTS-without-T.gitcd ZeroSpeech-TTS-without-Tتثبيت بيثون 3.
قم بتثبيت أحدث إصدار من Pytorch وفقًا للمنصة. لتحسين الأداء ، قم بالتثبيت باستخدام دعم GPU (CUDA) إذا كان قابلاً للتطبيق. يعمل هذا الرمز مع Pytorch 0.4 وبعد ذلك.
قم بتنزيل مجموعة بيانات Zerospeech.
wget https://download.zerospeech.com/2019/english.tgz
tar xvfz english.tgz -C data
rm -f english.tgz
wget https://download.zerospeech.com/2019/surprise.zip
# Go to https://download.zerospeech.com and accept the licence agreement
# to get the password protecting the archive
unzip surprise.zip -d data
rm -f surprise.zip
بعد تفريغ مجموعة البيانات في ~/ZeroSpeech-TTS-without-T/data ، يجب أن تبدو شجرة البيانات هكذا:
|- ZeroSpeech-TTS-without-T
|- data
|- english
|- train
|- unit
|- voice
|- test
|- surprise
|- train
|- unit
|- voice
|- test
المعالجة المسبقة لمجموعة البيانات وعينة من ملفات فهرس جاهزة للنموذج:
python3 main.py --preprocess —-remake
تدريب نموذج ASR-TTS Autoencoder لاكتشاف الوحدات اللغوية المنفصلة:
python3 main.py --train_ae
يمكن العثور على فرط الممتدة القابلة للضبط في HPS/Zerospeech.json. يمكنك ضبط هذه المعلمات والإعداد عن طريق تحرير الملف ، ويوصى بفرط البراميلات الافتراضية لهذا المشروع.
تدريب TTS Patcher لتعزيز أداء التحويل الصوتي:
python3 main.py --train_p --load_model --load_train_model_name=model.pth-ae-400000
تدريب TTS Patcher مع تدريب الخصومة الموجهة المستهدفة:
python3 main.py --train_tgat --load_model --load_train_model_name=model.pth-ae-400000
شاشة مع Tensorboard (اختياري)
tensorboard --logdir='path to log dir'
or
python3 -m tensorboard.main --logdir='path to log dir'
اختبار على خطاب واحد ::
python3 main.py --test_single --load_test_model_name=model.pth-ae-200000
اختبار على "sample.txt" وإنشاء ملفات صوتية إعادة تشكيل ::
python3 main.py --test --load_test_model_name=model.pth-ae-200000
اختبار على كل خطاب الاختبار ضمن test/ وإنشاء ملفات الترميز::
python3 main.py --test_encode --load_test_model_name=model.pth-ae-200000
إضافة- --enc_only إذا كان الاختبار باستخدام ASR-TTS Autoender فقط:
python3 main.py --test_single --load_test_model_name=model.pth-ae-200000 --enc_only
python3 main.py --test --load_test_model_name=model.pth-ae-200000 --enc_only
python3 main.py --test_encode --load_test_model_name=model.pth-ae-200000 --enc_only
--dataset=surprise للتبديل إلى المجموعة البديلة الافتراضية ، يتم التعامل مع جميع المسارات تلقائيًا إذا تم وضع بنية شجرة البيانات كما هو مقترح. على سبيل المثال: python3 main.py --train_ae --dataset=surprise
--load_train_model_name=model.pth-ae-400000-128-multi-1024-english
--ckpt_dir=./ckpt_english أو --ckpt_dir=./ckpt_surprise بشكل افتراضي). --load_test_model_name=model.pth-ae-400000-128-multi-1024-english (by name)
--ckpt_pth=ckpt/model.pth-ae-400000-128-multi-1024-english (direct path)
128-multi-1024 ، فيجب ضبط seg_len و enc_size على 128 و 1024 ، على التوالي. إذا تم تحميل نموذج ae ، فيجب استخدام الوسيطة --enc_only عند تشغيل main.py (انظر 4. في قسم الاختبار). @article{Liu_2019,
title={Unsupervised End-to-End Learning of Discrete Linguistic Units for Voice Conversion},
url={http://dx.doi.org/10.21437/interspeech.2019-2048},
DOI={10.21437/interspeech.2019-2048},
journal={Interspeech 2019},
publisher={ISCA},
author={Liu, Andy T. and Hsu, Po-chun and Lee, Hung-Yi},
year={2019},
month={Sep}
}


