ZeroSpeech TTS without T
1.0.0
git clone [email protected]:andi611/ZeroSpeech-TTS-without-T.gitcd ZeroSpeech-TTS-without-T파이썬 3을 설치하십시오.
플랫폼에 따라 최신 버전의 Pytorch를 설치하십시오. 더 나은 성능을 보려면 GPU 지원 (CUDA)으로 실행 가능한 경우 설치하십시오. 이 코드는 Pytorch 0.4 이상에서 작동합니다.
Zerospeech 데이터 세트를 다운로드하십시오.
wget https://download.zerospeech.com/2019/english.tgz
tar xvfz english.tgz -C data
rm -f english.tgz
wget https://download.zerospeech.com/2019/surprise.zip
# Go to https://download.zerospeech.com and accept the licence agreement
# to get the password protecting the archive
unzip surprise.zip -d data
rm -f surprise.zip
데이터 세트를 ~/ZeroSpeech-TTS-without-T/data 로 포장 한 후 데이터 트리는 다음과 같습니다.
|- ZeroSpeech-TTS-without-T
|- data
|- english
|- train
|- unit
|- voice
|- test
|- surprise
|- train
|- unit
|- voice
|- test
데이터 세트 및 샘플 모델 지원 인덱스 파일 전처리 :
python3 main.py --preprocess —-remake
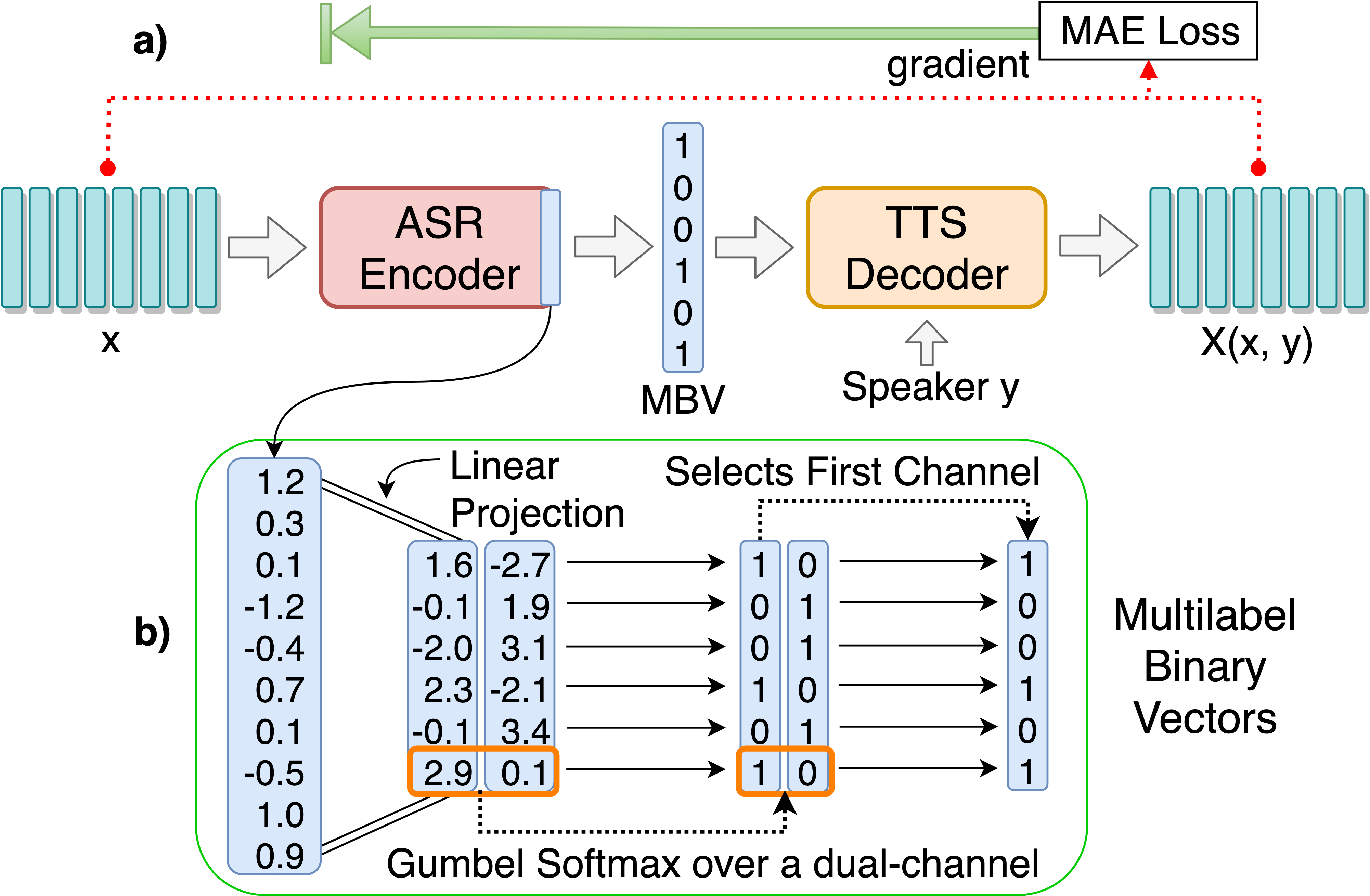
개별 언어 단위 발견을위한 ASR-TTS 자동 코디더 모델을 훈련시킵니다.
python3 main.py --train_ae
조정 가능한 하이퍼 파라미터는 HPS/Zerospeech.json에서 찾을 수 있습니다. 파일을 편집하여 이러한 매개 변수를 조정하고 설정할 수 있으며이 프로젝트에는 기본 하이퍼 파라미터가 권장됩니다.
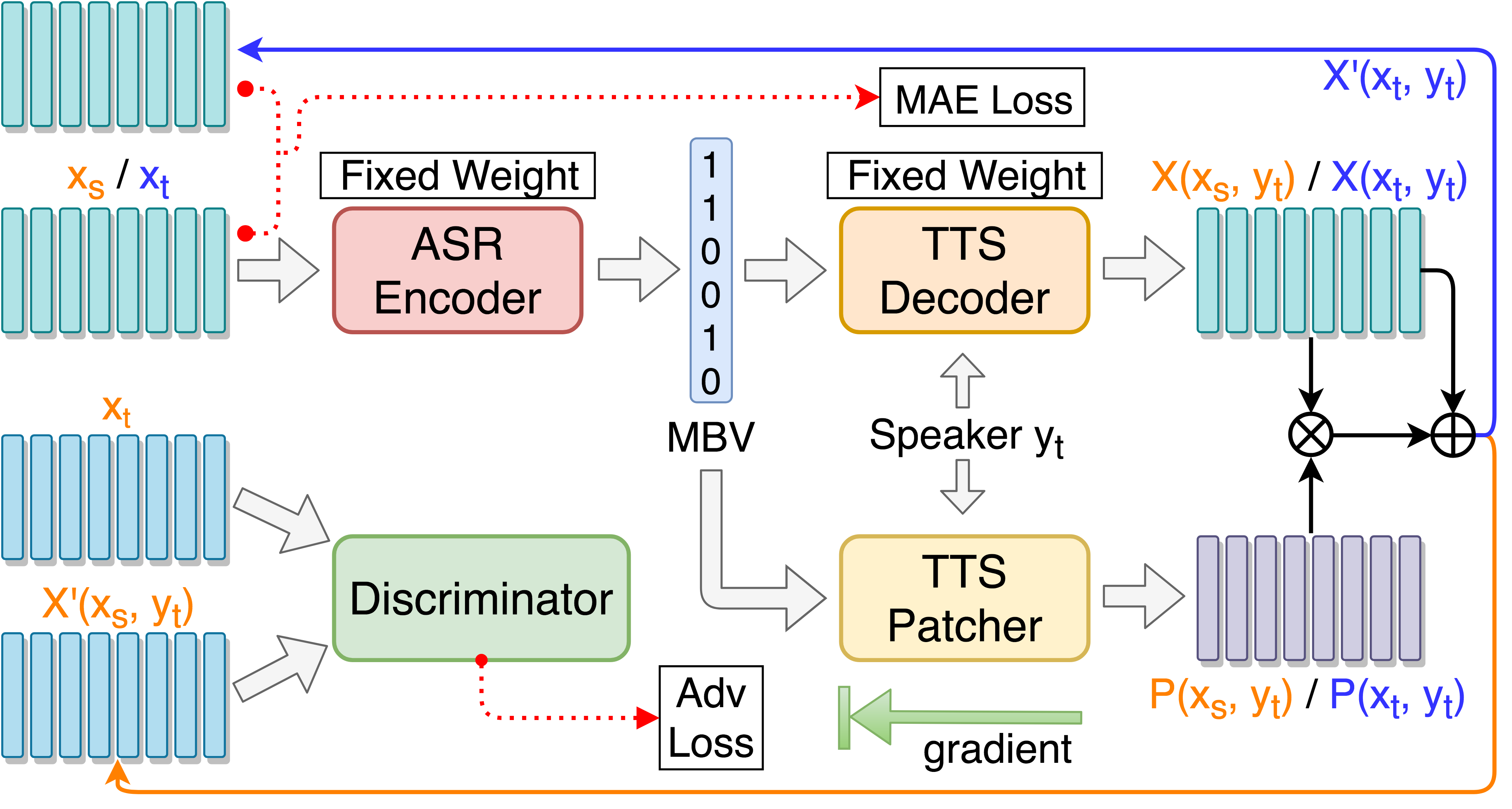
음성 변환 성능 향상을위한 TTT 패치기 열차 :
python3 main.py --train_p --load_model --load_train_model_name=model.pth-ae-400000
대상 가이드 대적 훈련으로 TTS 패치를 기차 :
python3 main.py --train_tgat --load_model --load_train_model_name=model.pth-ae-400000
텐서 보드로 모니터링 (선택 사항)
tensorboard --logdir='path to log dir'
or
python3 -m tensorboard.main --logdir='path to log dir'
단일 연설에서 테스트 ::
python3 main.py --test_single --load_test_model_name=model.pth-ae-200000
'synthesis.txt'를 테스트하고 재 동기화 된 오디오 파일을 생성합니다. : :
python3 main.py --test --load_test_model_name=model.pth-ae-200000
test/ 중인 모든 테스트 음성을 테스트하고 인코딩 파일을 생성합니다.
python3 main.py --test_encode --load_test_model_name=model.pth-ae-200000
ASR-TTS Autoencoder로만 테스트하는 경우 --enc_only 추가하십시오.
python3 main.py --test_single --load_test_model_name=model.pth-ae-200000 --enc_only
python3 main.py --test --load_test_model_name=model.pth-ae-200000 --enc_only
python3 main.py --test_encode --load_test_model_name=model.pth-ae-200000 --enc_only
--dataset=surprise 사용하여 기본 대체 세트로 전환하려면 데이터 트리 구조가 제안 된대로 배치되면 모든 경로가 자동으로 처리됩니다. 예를 들어: python3 main.py --train_ae --dataset=surprise
--load_train_model_name=model.pth-ae-400000-128-multi-1024-english
--ckpt_dir=./ckpt_english 또는 --ckpt_dir=./ckpt_surprise ). --load_test_model_name=model.pth-ae-400000-128-multi-1024-english (by name)
--ckpt_pth=ckpt/model.pth-ae-400000-128-multi-1024-english (direct path)
128-multi-1024 모델이로드되면 seg_len 및 enc_size 각각 128과 1024로 설정해야합니다. ae 모델이로드되는 경우 main.py 실행할 때 --enc_only 를 사용해야합니다 (테스트 섹션의 4. 참조). @article{Liu_2019,
title={Unsupervised End-to-End Learning of Discrete Linguistic Units for Voice Conversion},
url={http://dx.doi.org/10.21437/interspeech.2019-2048},
DOI={10.21437/interspeech.2019-2048},
journal={Interspeech 2019},
publisher={ISCA},
author={Liu, Andy T. and Hsu, Po-chun and Lee, Hung-Yi},
year={2019},
month={Sep}
}


