ZeroSpeech TTS without T
1.0.0
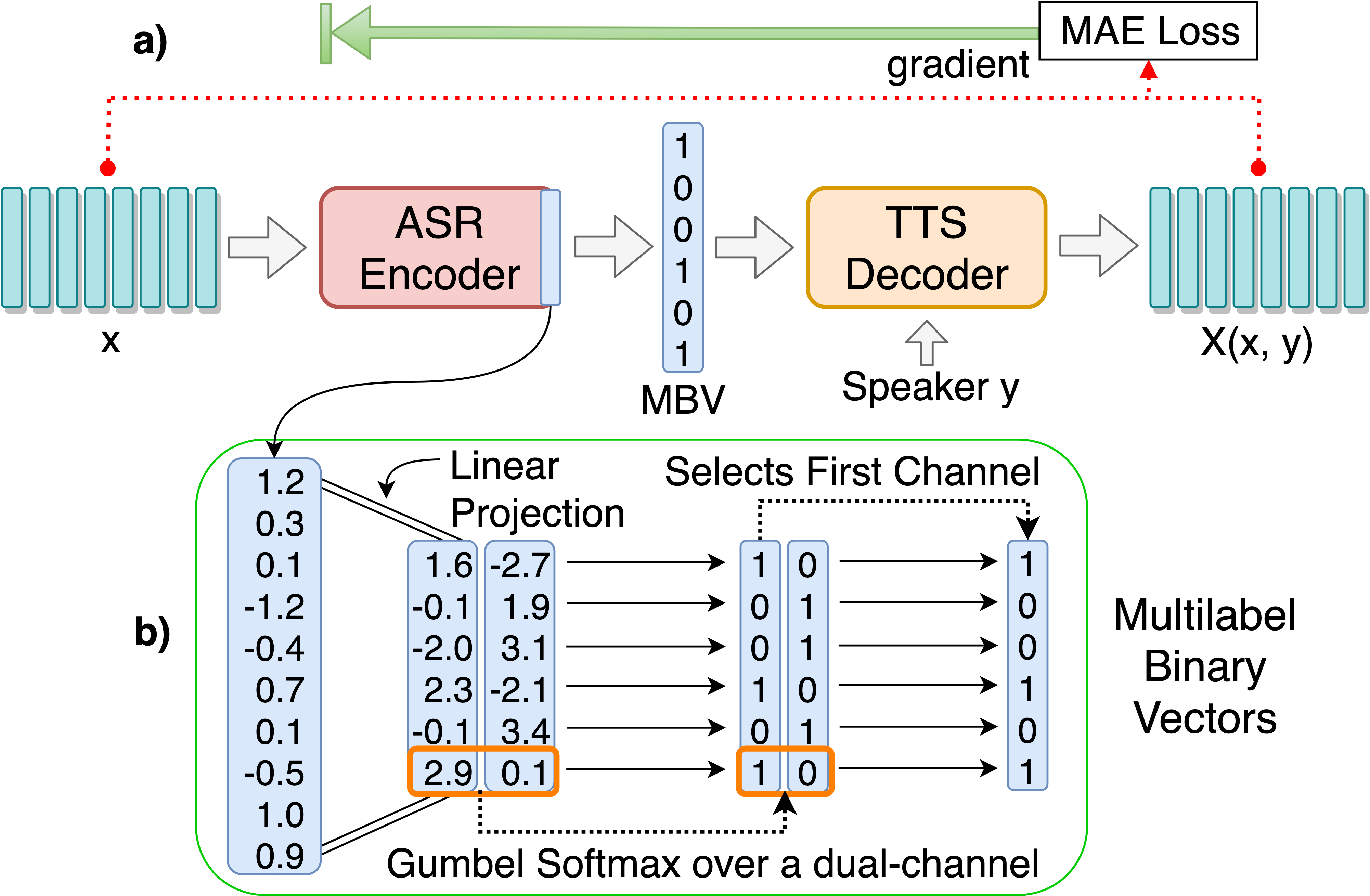
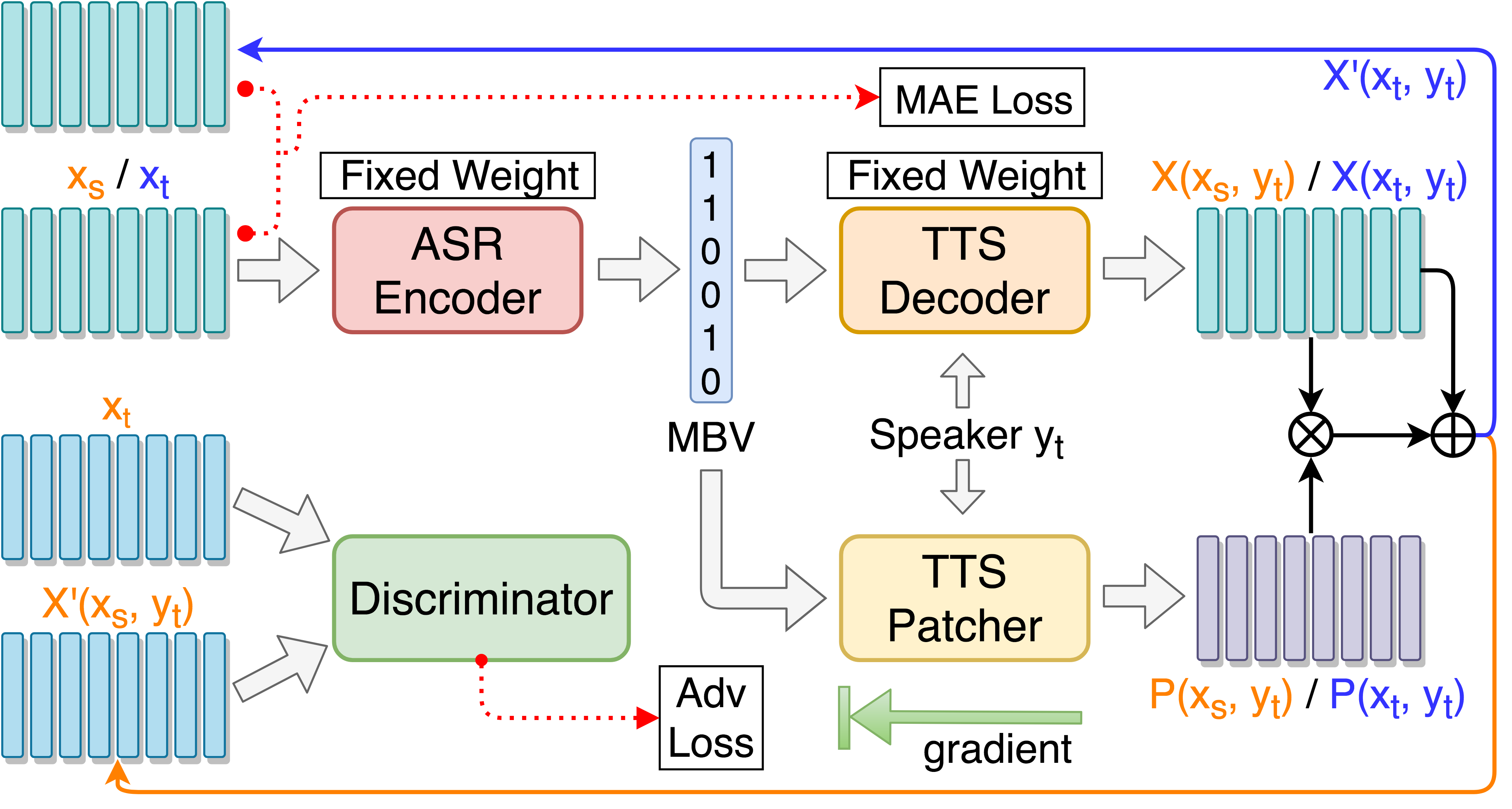
git clone [email protected]:andi611/ZeroSpeech-TTS-without-T.gitcd ZeroSpeech-TTS-without-TInstallieren Sie Python 3.
Installieren Sie die neueste Version von Pytorch gemäß Ihrer Plattform. Um eine bessere Leistung zu erzielen, installieren Sie bei der GPU -Unterstützung (CUDA), wenn sie lebensfähig sind. Dieser Code funktioniert mit Pytorch 0.4 und später.
Laden Sie den Zerspeech -Datensatz herunter.
wget https://download.zerospeech.com/2019/english.tgz
tar xvfz english.tgz -C data
rm -f english.tgz
wget https://download.zerospeech.com/2019/surprise.zip
# Go to https://download.zerospeech.com and accept the licence agreement
# to get the password protecting the archive
unzip surprise.zip -d data
rm -f surprise.zip
Nach dem Auspacken des Datensatzes in ~/ZeroSpeech-TTS-without-T/data sollte der Datenbaum so aussehen:
|- ZeroSpeech-TTS-without-T
|- data
|- english
|- train
|- unit
|- voice
|- test
|- surprise
|- train
|- unit
|- voice
|- test
Verarbeiten Sie die Datensatz- und Beispielmodell-Indexdateien:
python3 main.py --preprocess —-remake
Zug ASR-TTS AutoCoder-Modell für diskrete Spracheinheiten Entdeckung:
python3 main.py --train_ae
Abstimmbare Hyperparameter finden Sie in HPS/Zerospeech.json. Sie können diese Parameter und die Einstellung durch Bearbeiten der Datei anpassen. Die Standard -Hyperparameter werden für dieses Projekt empfohlen.
Zug TTS Patcher für Sprachkonvertierung Performance Boosting:
python3 main.py --train_p --load_model --load_train_model_name=model.pth-ae-400000
Training TTS Patcher mit zielgerichtetem kontroversem Training:
python3 main.py --train_tgat --load_model --load_train_model_name=model.pth-ae-400000
Überwachen Sie mit Tensorboard (optional)
tensorboard --logdir='path to log dir'
or
python3 -m tensorboard.main --logdir='path to log dir'
Test auf einer einzigen Rede ::
python3 main.py --test_single --load_test_model_name=model.pth-ae-200000
Testen Sie auf 'synthese.txt' und generieren resynthetisierte Audiodateien ::::
python3 main.py --test --load_test_model_name=model.pth-ae-200000
Testen Sie auf allen Testsprachen, die zu test/ und generieren Codierungsdateien generieren::::
python3 main.py --test_encode --load_test_model_name=model.pth-ae-200000
Hinzufügen --enc_only Wenn Sie nur mit ASR-TTS-Autocoder testen:
python3 main.py --test_single --load_test_model_name=model.pth-ae-200000 --enc_only
python3 main.py --test --load_test_model_name=model.pth-ae-200000 --enc_only
python3 main.py --test_encode --load_test_model_name=model.pth-ae-200000 --enc_only
--dataset=surprise , um zum Standard -Alternativsatz umzusteigen. Alle Pfade werden automatisch behandelt, wenn die Datenbaumstruktur wie vorgeschlagen platziert wird. Zum Beispiel: python3 main.py --train_ae --dataset=surprise
--load_train_model_name=model.pth-ae-400000-128-multi-1024-english
--ckpt_dir=./ckpt_english oder --ckpt_dir=./ckpt_surprise standardmäßig). --load_test_model_name=model.pth-ae-400000-128-multi-1024-english (by name)
--ckpt_pth=ckpt/model.pth-ae-400000-128-multi-1024-english (direct path)
128-multi-1024 Modell geladen wird, sollten seg_len und enc_size auf 128 bzw. 1024 eingestellt werden. Wenn ein ae -Modell geladen wird, muss das Argument --enc_only beim Ausführen main.py verwendet werden (siehe 4. Im Testabschnitt). @article{Liu_2019,
title={Unsupervised End-to-End Learning of Discrete Linguistic Units for Voice Conversion},
url={http://dx.doi.org/10.21437/interspeech.2019-2048},
DOI={10.21437/interspeech.2019-2048},
journal={Interspeech 2019},
publisher={ISCA},
author={Liu, Andy T. and Hsu, Po-chun and Lee, Hung-Yi},
year={2019},
month={Sep}
}


