ZeroSpeech TTS without T
1.0.0
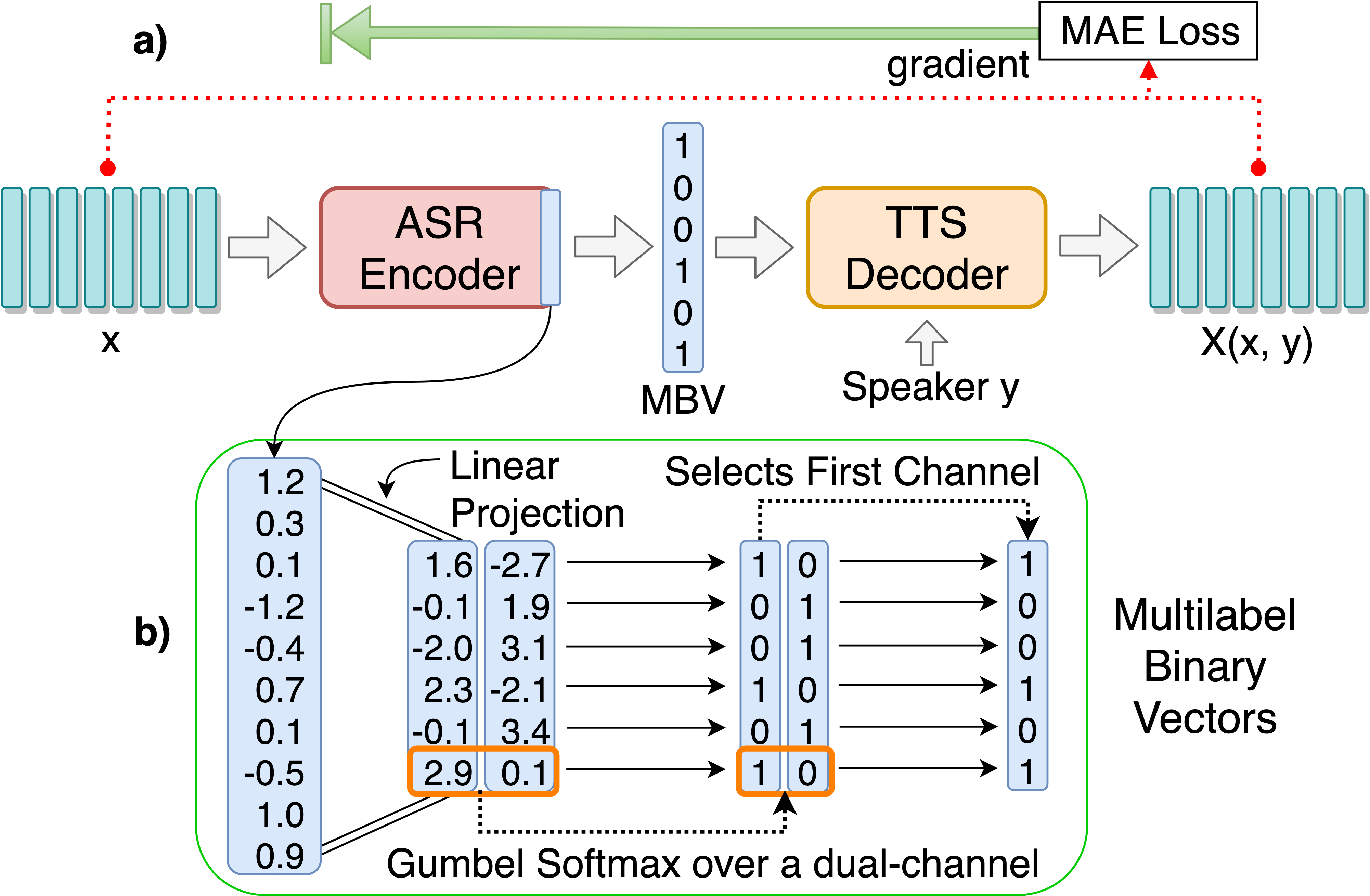
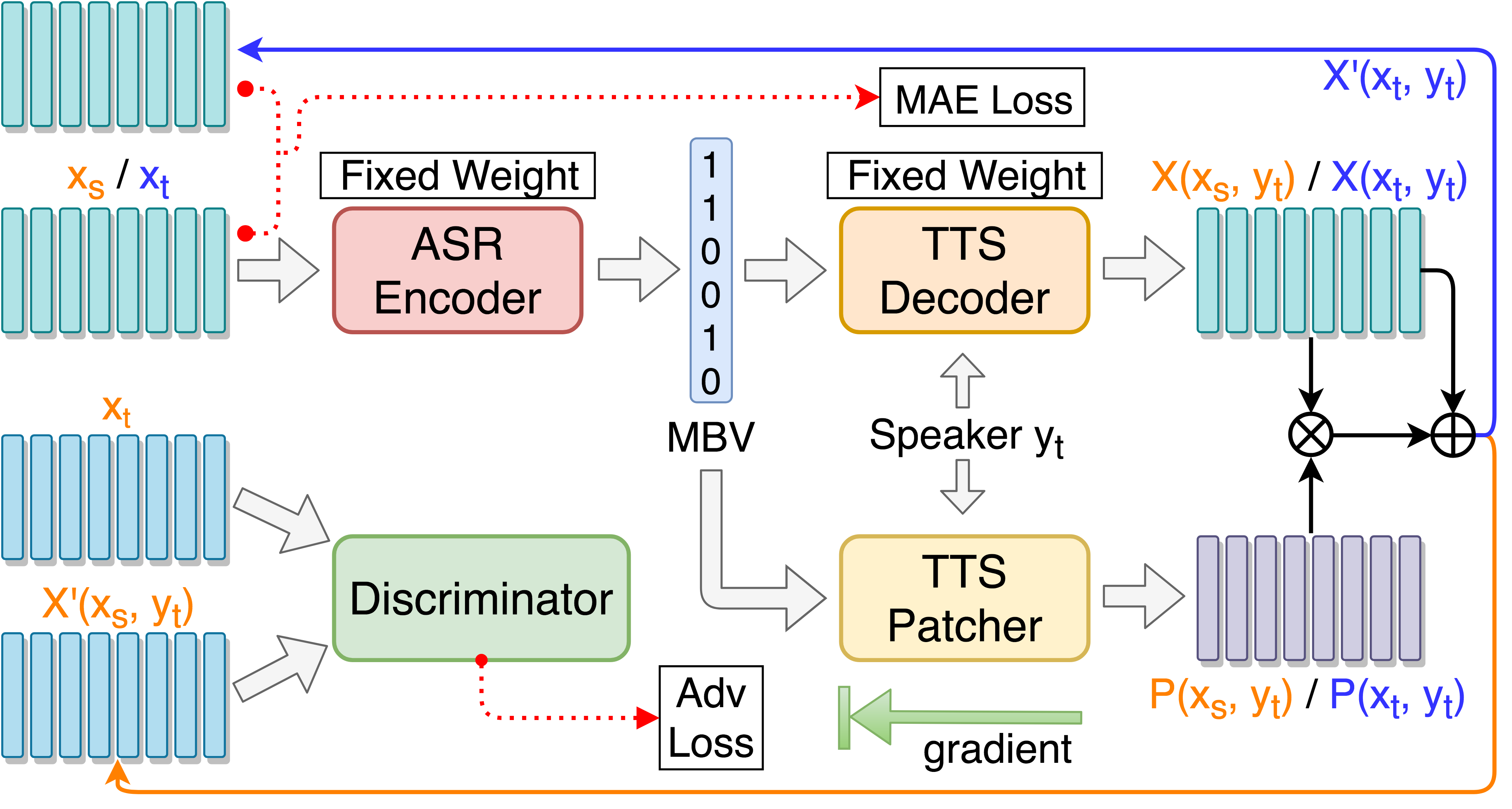
git clone [email protected]:andi611/ZeroSpeech-TTS-without-T.gitcd ZeroSpeech-TTS-without-Tติดตั้ง Python 3
ติดตั้ง Pytorch เวอร์ชันล่าสุดตามแพลตฟอร์มของคุณ เพื่อประสิทธิภาพที่ดีขึ้นให้ติดตั้งด้วย GPU Support (CUDA) หากทำงานได้ รหัสนี้ใช้งานได้กับ Pytorch 0.4 และใหม่กว่า
ดาวน์โหลดชุดข้อมูล Zerospeech
wget https://download.zerospeech.com/2019/english.tgz
tar xvfz english.tgz -C data
rm -f english.tgz
wget https://download.zerospeech.com/2019/surprise.zip
# Go to https://download.zerospeech.com and accept the licence agreement
# to get the password protecting the archive
unzip surprise.zip -d data
rm -f surprise.zip
หลังจากเปิดชุดข้อมูลลงใน ~/ZeroSpeech-TTS-without-T/data แผนผังข้อมูลควรมีลักษณะเช่นนี้:
|- ZeroSpeech-TTS-without-T
|- data
|- english
|- train
|- unit
|- voice
|- test
|- surprise
|- train
|- unit
|- voice
|- test
ประมวลผลไฟล์ดัชนีชุดข้อมูลและตัวอย่างแบบจำลองตัวอย่าง:
python3 main.py --preprocess —-remake
ฝึกอบรมโมเดล AutoEncoder AUTOENCODER สำหรับการค้นพบหน่วยภาษาศาสตร์แบบไม่ต่อเนื่อง:
python3 main.py --train_ae
hyperparameters ที่ปรับได้สามารถพบได้ใน hps/zerospeech.json คุณสามารถปรับพารามิเตอร์และการตั้งค่าเหล่านี้ได้โดยการแก้ไขไฟล์แนะนำให้ใช้พารามิเตอร์ไฮเปอร์พารามิเตอร์เริ่มต้นสำหรับโครงการนี้
Train TTS Patcher สำหรับการเพิ่มประสิทธิภาพการแปลงเสียง:
python3 main.py --train_p --load_model --load_train_model_name=model.pth-ae-400000
ฝึกอบรม TTS Patcher ด้วยการฝึกอบรมฝ่ายตรงข้ามเป้าหมาย:
python3 main.py --train_tgat --load_model --load_train_model_name=model.pth-ae-400000
ตรวจสอบด้วย tensorboard (ไม่บังคับ)
tensorboard --logdir='path to log dir'
or
python3 -m tensorboard.main --logdir='path to log dir'
ทดสอบคำพูดเดียว ::
python3 main.py --test_single --load_test_model_name=model.pth-ae-200000
ทดสอบ 'synthesis.txt' และ สร้างไฟล์เสียงที่สังเคราะห์ใหม่ :::
python3 main.py --test --load_test_model_name=model.pth-ae-200000
ทดสอบคำพูดการทดสอบทั้งหมดภายใต้ test/ และ สร้างไฟล์เข้ารหัส ::
python3 main.py --test_encode --load_test_model_name=model.pth-ae-200000
เพิ่ม --enc_only หากการทดสอบกับ ASR-TTS AutoEncoder เท่านั้น:
python3 main.py --test_single --load_test_model_name=model.pth-ae-200000 --enc_only
python3 main.py --test --load_test_model_name=model.pth-ae-200000 --enc_only
python3 main.py --test_encode --load_test_model_name=model.pth-ae-200000 --enc_only
--dataset=surprise ที่จะเปลี่ยนไปใช้ชุดทางเลือกเริ่มต้นเส้นทางทั้งหมดจะได้รับการจัดการโดยอัตโนมัติหากโครงสร้างต้นไม้ข้อมูลถูกวางตามที่แนะนำ ตัวอย่างเช่น: python3 main.py --train_ae --dataset=surprise
--load_train_model_name=model.pth-ae-400000-128-multi-1024-english
--ckpt_dir=./ckpt_english หรือ --ckpt_dir=./ckpt_surprise โดยค่าเริ่มต้น) --load_test_model_name=model.pth-ae-400000-128-multi-1024-english (by name)
--ckpt_pth=ckpt/model.pth-ae-400000-128-multi-1024-english (direct path)
128-multi-1024 ควรตั้งค่า seg_len และ enc_size เป็น 128 และ 1024 ตามลำดับ หากมีการโหลดโมเดล ae อาร์กิวเมนต์ --enc_only จะต้องใช้เมื่อเรียกใช้ main.py (ดู 4. ในส่วนการทดสอบ) @article{Liu_2019,
title={Unsupervised End-to-End Learning of Discrete Linguistic Units for Voice Conversion},
url={http://dx.doi.org/10.21437/interspeech.2019-2048},
DOI={10.21437/interspeech.2019-2048},
journal={Interspeech 2019},
publisher={ISCA},
author={Liu, Andy T. and Hsu, Po-chun and Lee, Hung-Yi},
year={2019},
month={Sep}
}


