ZeroSpeech TTS without T
1.0.0
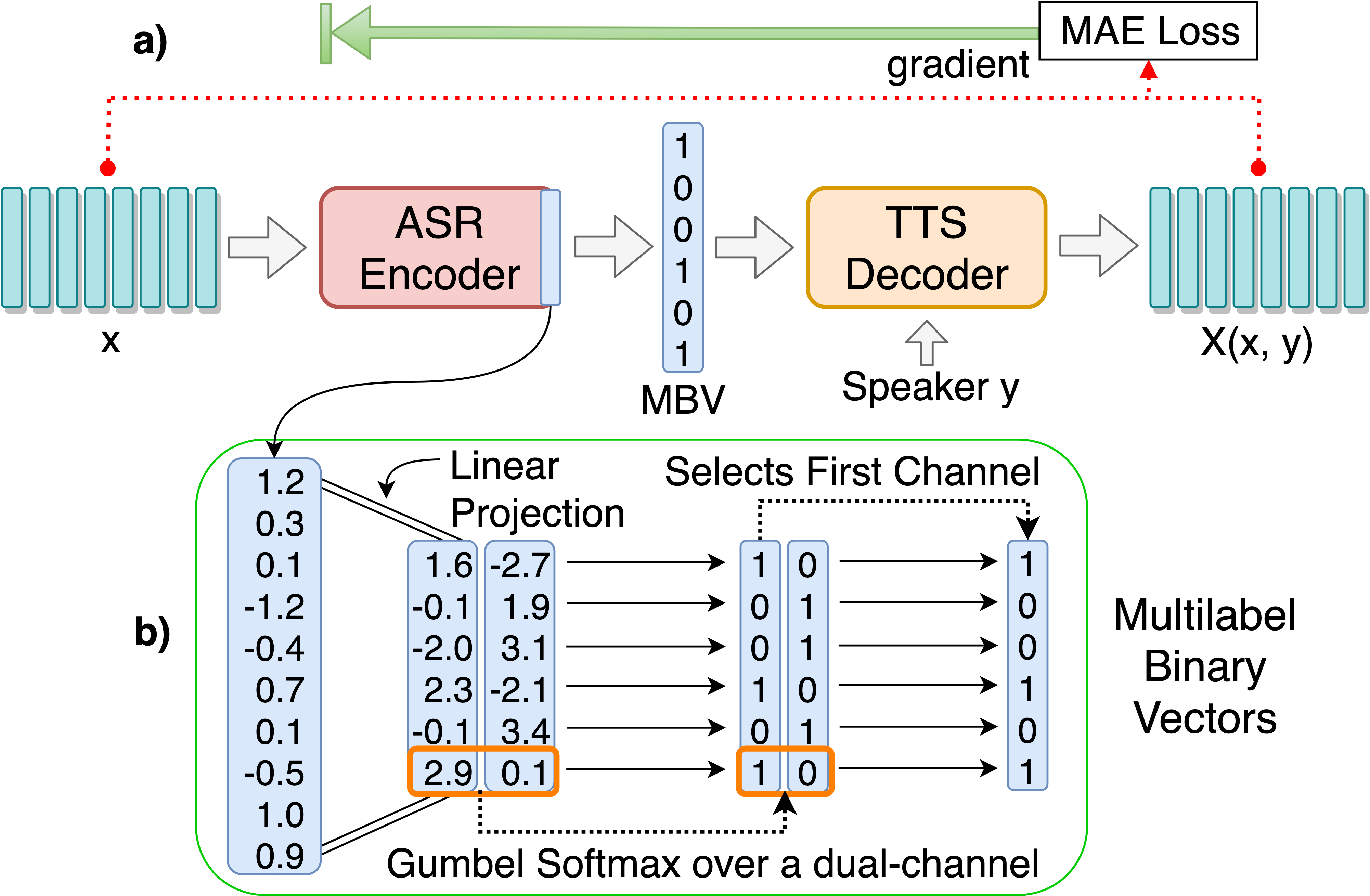
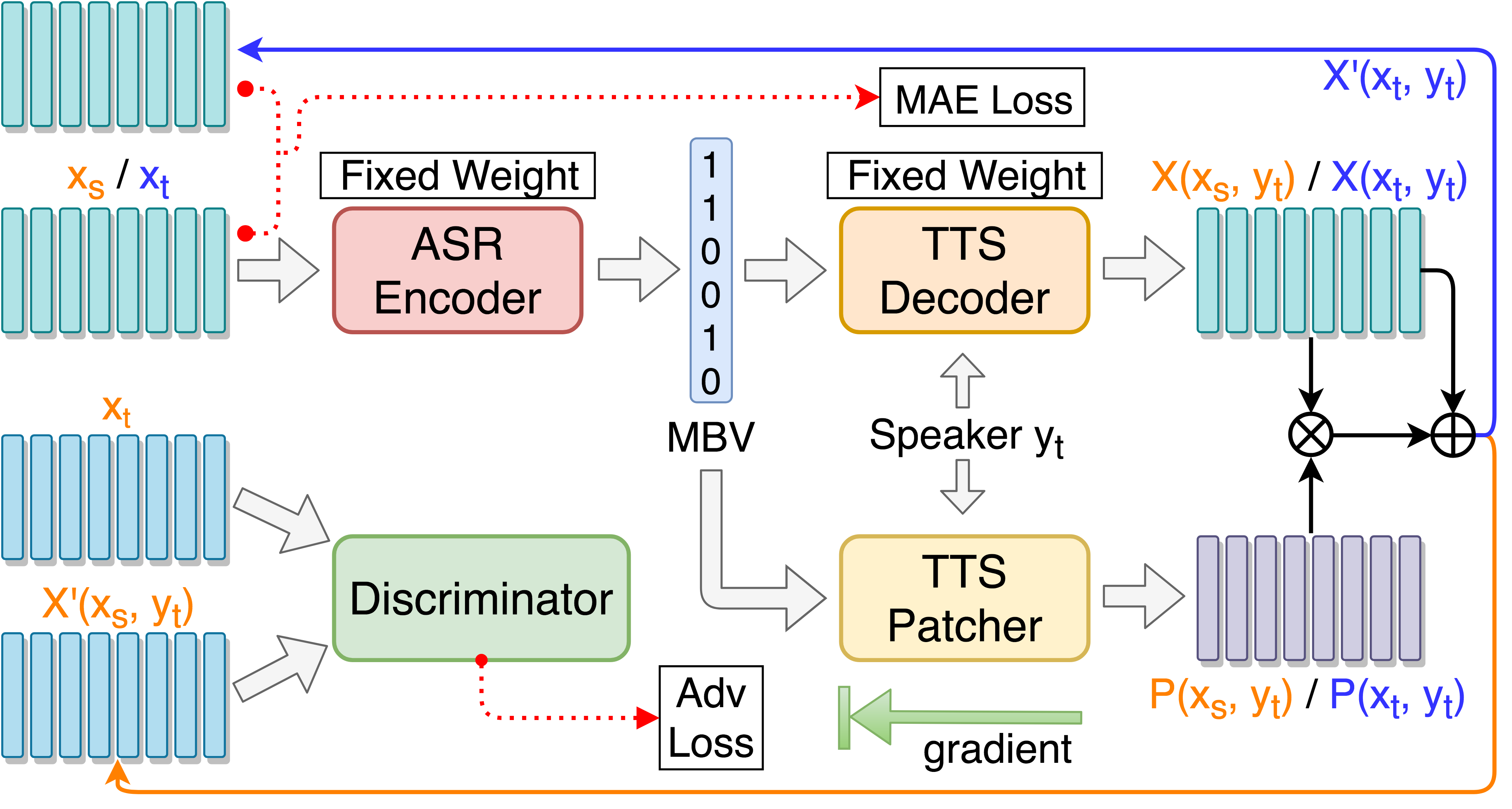
git clone [email protected]:andi611/ZeroSpeech-TTS-without-T.gitcd ZeroSpeech-TTS-without-T安裝Python 3。
根據您的平台安裝最新版本的Pytorch 。為了獲得更好的性能,請在可行的情況下使用GPU支持(CUDA)安裝。該代碼可與Pytorch 0.4及更高版本一起使用。
下載Zerospeech數據集。
wget https://download.zerospeech.com/2019/english.tgz
tar xvfz english.tgz -C data
rm -f english.tgz
wget https://download.zerospeech.com/2019/surprise.zip
# Go to https://download.zerospeech.com and accept the licence agreement
# to get the password protecting the archive
unzip surprise.zip -d data
rm -f surprise.zip
將數據集解放到~/ZeroSpeech-TTS-without-T/data之後,數據樹應該看起來像這樣:
|- ZeroSpeech-TTS-without-T
|- data
|- english
|- train
|- unit
|- voice
|- test
|- surprise
|- train
|- unit
|- voice
|- test
預處理數據集和示例模型就緒索引文件:
python3 main.py --preprocess —-remake
訓練ASR-TTS自動編碼器模型,以發現離散語言單元的發現:
python3 main.py --train_ae
可調超參數可以在HPS/Zerospeech.json中找到。您可以通過編輯文件來調整這些參數並設置設置,建議該項目使用默認的超參數。
訓練TTS Patcher以提高語音轉換性能:
python3 main.py --train_p --load_model --load_train_model_name=model.pth-ae-400000
培訓TTS Patcher和目標有指導的對抗訓練:
python3 main.py --train_tgat --load_model --load_train_model_name=model.pth-ae-400000
用張板監視(可選)
tensorboard --logdir='path to log dir'
or
python3 -m tensorboard.main --logdir='path to log dir'
在單個演講中測試::
python3 main.py --test_single --load_test_model_name=model.pth-ae-200000
測試“ Synthesis.txt”並生成重新合成的音頻文件::
python3 main.py --test --load_test_model_name=model.pth-ae-200000
測試test/並生成編碼文件::
python3 main.py --test_encode --load_test_model_name=model.pth-ae-200000
添加--enc_only僅使用ASR-TTS AutoCododer測試:
python3 main.py --test_single --load_test_model_name=model.pth-ae-200000 --enc_only
python3 main.py --test --load_test_model_name=model.pth-ae-200000 --enc_only
python3 main.py --test_encode --load_test_model_name=model.pth-ae-200000 --enc_only
--dataset=surprise即可切換到默認的替代集,如果放置數據樹結構如建議,所有路徑均自動處理。例如: python3 main.py --train_ae --dataset=surprise
--load_train_model_name=model.pth-ae-400000-128-multi-1024-english
--ckpt_dir=./ckpt_english或--ckpt_dir=./ckpt_surprise默認情況下)。 --load_test_model_name=model.pth-ae-400000-128-multi-1024-english (by name)
--ckpt_pth=ckpt/model.pth-ae-400000-128-multi-1024-english (direct path)
128-multi-1024模型,則應分別將seg_len和enc_size設置為128和1024。如果正在加載ae模型,則在運行main.py時必須使用參數--enc_only (在測試部分中請參見4。)。 @article{Liu_2019,
title={Unsupervised End-to-End Learning of Discrete Linguistic Units for Voice Conversion},
url={http://dx.doi.org/10.21437/interspeech.2019-2048},
DOI={10.21437/interspeech.2019-2048},
journal={Interspeech 2019},
publisher={ISCA},
author={Liu, Andy T. and Hsu, Po-chun and Lee, Hung-Yi},
year={2019},
month={Sep}
}


