ZeroSpeech TTS without T
1.0.0
git clone [email protected]:andi611/ZeroSpeech-TTS-without-T.gitcd ZeroSpeech-TTS-without-TУстановите Python 3.
Установите последнюю версию Pytorch в соответствии с вашей платформой. Для лучшей производительности установите с помощью поддержки GPU (CUDA), если он является жизнеспособной. Этот код работает с Pytorch 0,4 и позже.
Загрузите набор данных Zerospeech.
wget https://download.zerospeech.com/2019/english.tgz
tar xvfz english.tgz -C data
rm -f english.tgz
wget https://download.zerospeech.com/2019/surprise.zip
# Go to https://download.zerospeech.com and accept the licence agreement
# to get the password protecting the archive
unzip surprise.zip -d data
rm -f surprise.zip
После распаковки набора данных в ~/ZeroSpeech-TTS-without-T/data , дерево данных должно выглядеть следующим образом:
|- ZeroSpeech-TTS-without-T
|- data
|- english
|- train
|- unit
|- voice
|- test
|- surprise
|- train
|- unit
|- voice
|- test
Предварительно обрабатывать набор данных и образцы модели, готовых к модели, файлы индекса:
python3 main.py --preprocess —-remake
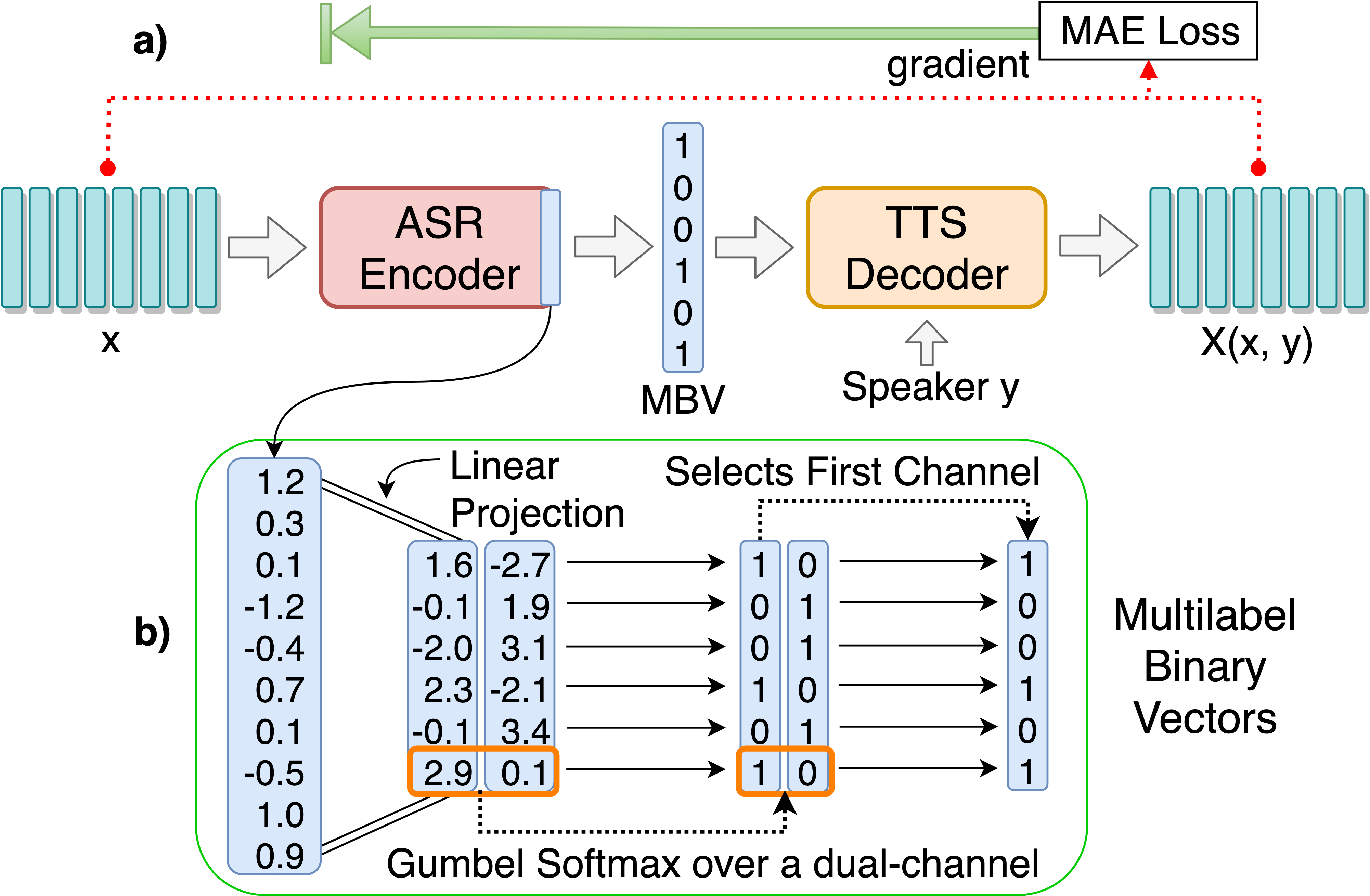
Поезд ASR-TTS AutoEncoder Model для дискретных лингвистических единиц Обнаружение:
python3 main.py --train_ae
Настраиваемые гиперпараметры можно найти в hps/zerospeech.json. Вы можете настроить эти параметры и настройки, редактируя файл, для этого проекта рекомендуется гиперпараметры по умолчанию.
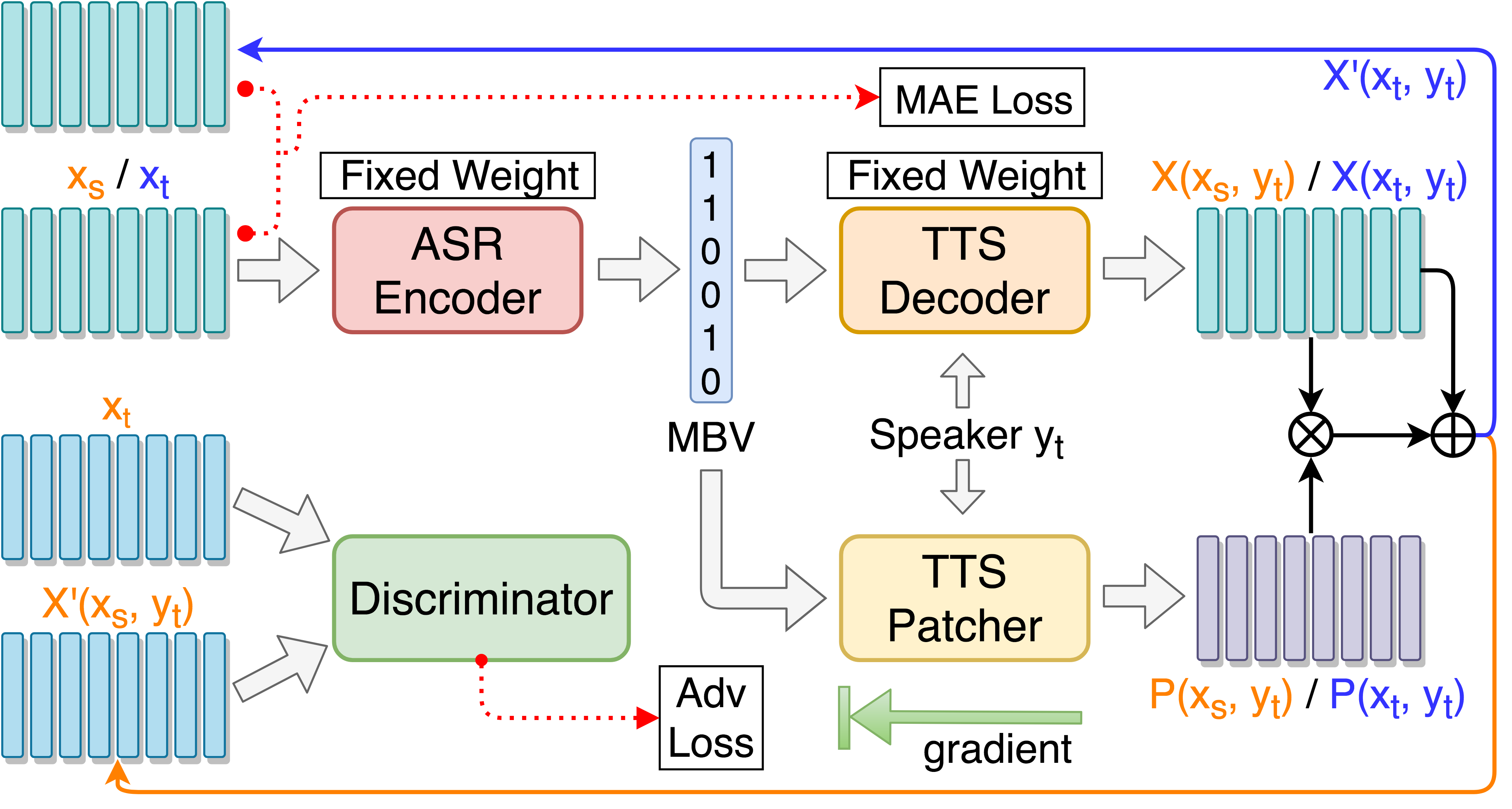
Поезда TTS Patcher для повышения производительности преобразования голоса:
python3 main.py --train_p --load_model --load_train_model_name=model.pth-ae-400000
Обучить петуширование TTS с целевым управляемым состязательным обучением:
python3 main.py --train_tgat --load_model --load_train_model_name=model.pth-ae-400000
Мониторинг с помощью Tensorboard (необязательно)
tensorboard --logdir='path to log dir'
or
python3 -m tensorboard.main --logdir='path to log dir'
Тест на одну речь ::
python3 main.py --test_single --load_test_model_name=model.pth-ae-200000
Проверьте на 'synthesis.txt' и сгенерируйте ресинтезированные аудиофайлы ::
python3 main.py --test --load_test_model_name=model.pth-ae-200000
Проверьте всю тестирующую речь под test/ и генерируйте кодирующие файлы ::
python3 main.py --test_encode --load_test_model_name=model.pth-ae-200000
Добавить --enc_only если тестирование только с ASR-TTS AutoEncoder:
python3 main.py --test_single --load_test_model_name=model.pth-ae-200000 --enc_only
python3 main.py --test --load_test_model_name=model.pth-ae-200000 --enc_only
python3 main.py --test_encode --load_test_model_name=model.pth-ae-200000 --enc_only
--dataset=surprise . Например: python3 main.py --train_ae --dataset=surprise
--load_train_model_name=model.pth-ae-400000-128-multi-1024-english
--ckpt_dir=./ckpt_english или --ckpt_dir=./ckpt_surprise по умолчанию). --load_test_model_name=model.pth-ae-400000-128-multi-1024-english (by name)
--ckpt_pth=ckpt/model.pth-ae-400000-128-multi-1024-english (direct path)
128-multi-1024 , seg_len и enc_size должны быть установлены на 128 и 1024 соответственно. Если модель ae загружается, аргумент --enc_only должен использоваться при запуске main.py (см. 4. В разделе тестирования). @article{Liu_2019,
title={Unsupervised End-to-End Learning of Discrete Linguistic Units for Voice Conversion},
url={http://dx.doi.org/10.21437/interspeech.2019-2048},
DOI={10.21437/interspeech.2019-2048},
journal={Interspeech 2019},
publisher={ISCA},
author={Liu, Andy T. and Hsu, Po-chun and Lee, Hung-Yi},
year={2019},
month={Sep}
}


