ZeroSpeech TTS without T
1.0.0
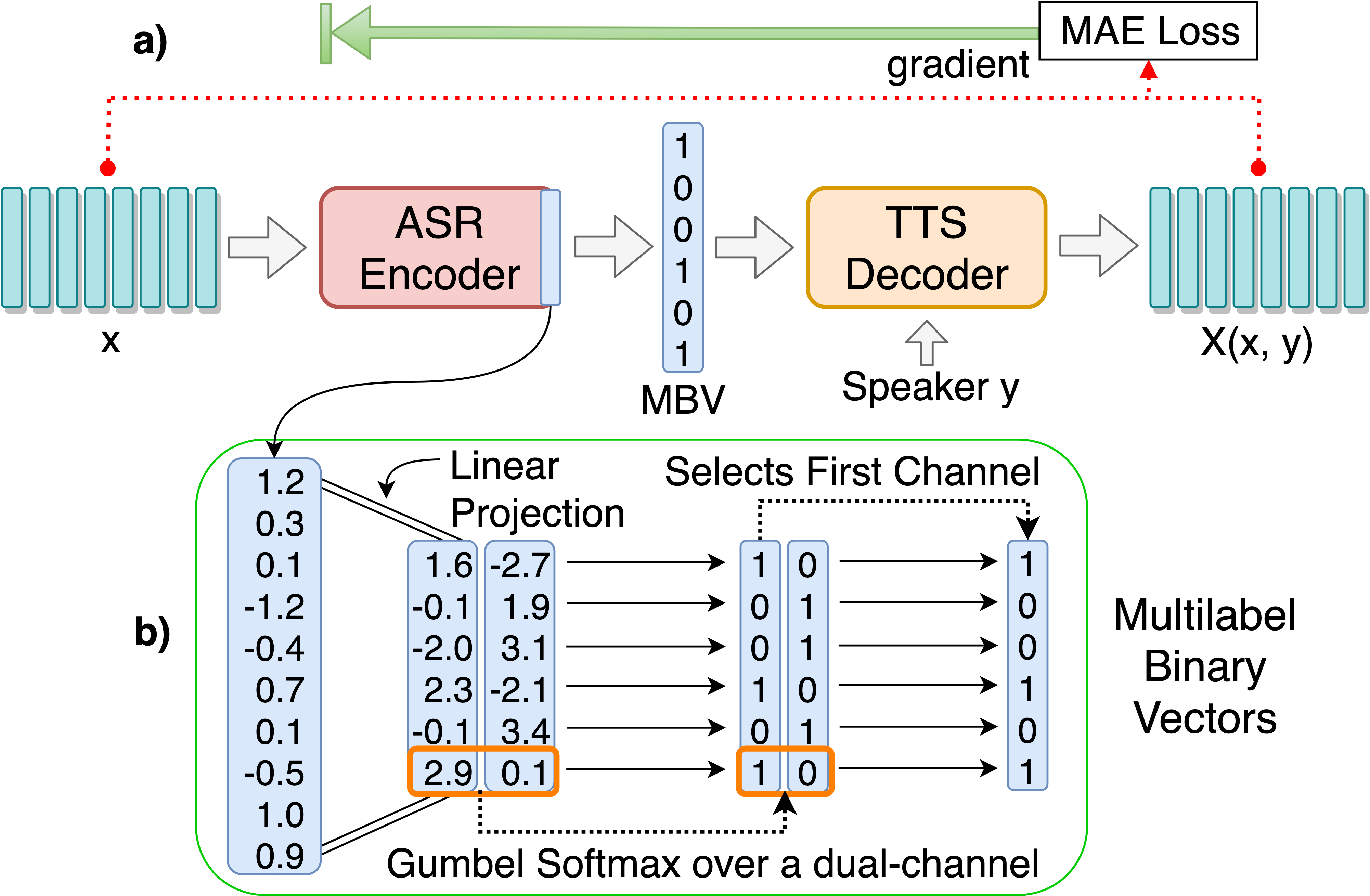
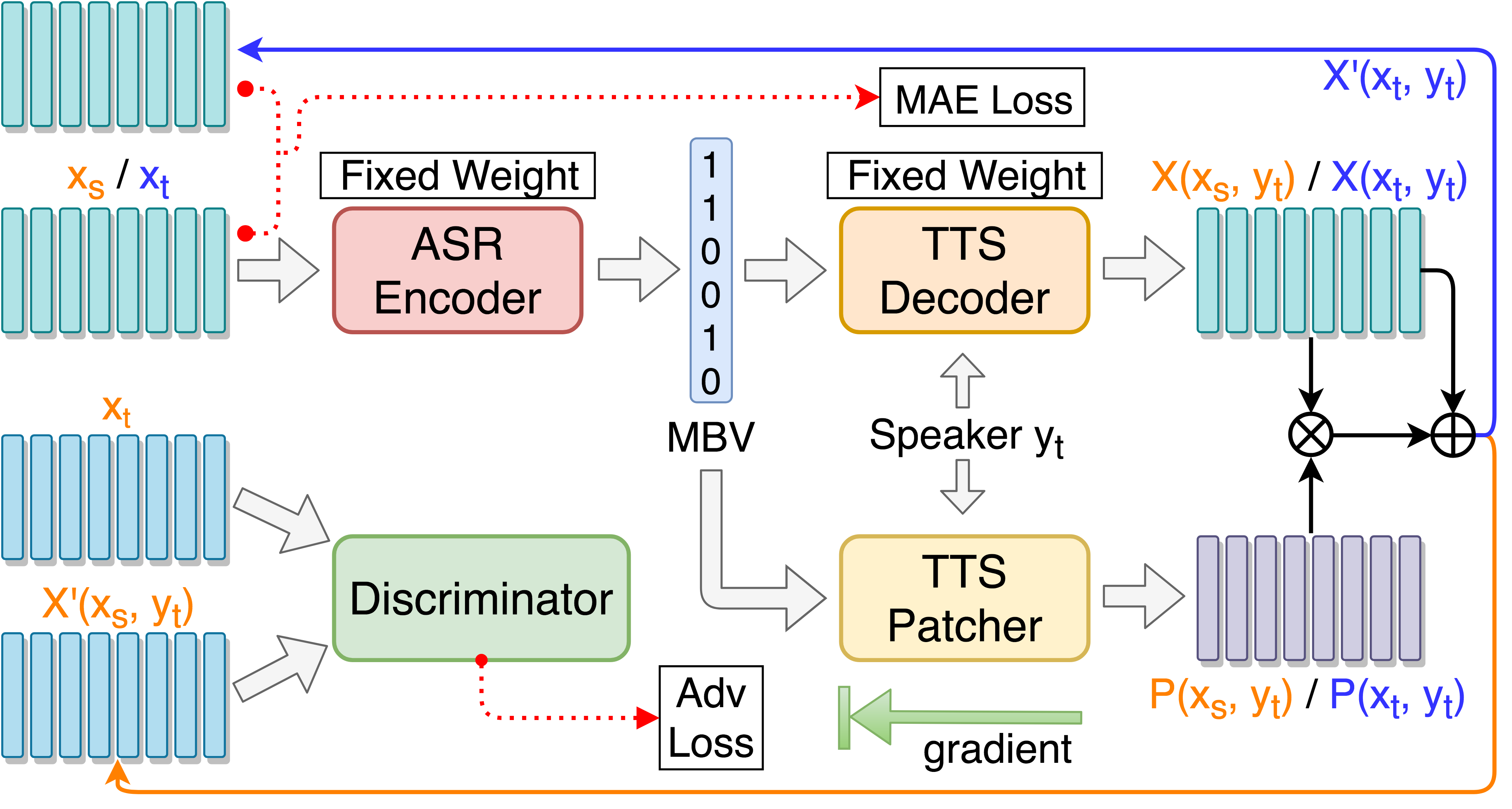
git clone [email protected]:andi611/ZeroSpeech-TTS-without-T.gitcd ZeroSpeech-TTS-without-TInstall Python 3.
Install the latest version of Pytorch according to your platform. For better performance, install with GPU support (CUDA) if viable. This code works with Pytorch 0.4 and later.
Download the ZeroSpeech dataset.
wget https://download.zerospeech.com/2019/english.tgz
tar xvfz english.tgz -C data
rm -f english.tgz
wget https://download.zerospeech.com/2019/surprise.zip
# Go to https://download.zerospeech.com and accept the licence agreement
# to get the password protecting the archive
unzip surprise.zip -d data
rm -f surprise.zip
After unpacking the dataset into ~/ZeroSpeech-TTS-without-T/data, data tree should look like this:
|- ZeroSpeech-TTS-without-T
|- data
|- english
|- train
|- unit
|- voice
|- test
|- surprise
|- train
|- unit
|- voice
|- test
Preprocess the dataset and sample model-ready index files:
python3 main.py --preprocess —-remake
Train ASR-TTS autoencoder model for discrete linguistic units discovery:
python3 main.py --train_ae
Tunable hyperparameters can be found in hps/zerospeech.json. You can adjust these parameters and setting by editing the file, the default hyperparameters are recommended for this project.
Train TTS patcher for voice conversion performance boosting:
python3 main.py --train_p --load_model --load_train_model_name=model.pth-ae-400000
Train TTS patcher with target guided adversarial training:
python3 main.py --train_tgat --load_model --load_train_model_name=model.pth-ae-400000
Monitor with Tensorboard (OPTIONAL)
tensorboard --logdir='path to log dir'
or
python3 -m tensorboard.main --logdir='path to log dir'
Test on a single speech::
python3 main.py --test_single --load_test_model_name=model.pth-ae-200000
Test on 'synthesis.txt' and generate resynthesized audio files::
python3 main.py --test --load_test_model_name=model.pth-ae-200000
Test on all the testing speech under test/ and generate encoding files::
python3 main.py --test_encode --load_test_model_name=model.pth-ae-200000
Add --enc_only if testing with ASR-TTS autoencoder only:
python3 main.py --test_single --load_test_model_name=model.pth-ae-200000 --enc_only
python3 main.py --test --load_test_model_name=model.pth-ae-200000 --enc_only
python3 main.py --test_encode --load_test_model_name=model.pth-ae-200000 --enc_only
--dataset=surprise to switch to the default alternative set, all paths are handled automatically if the data tree structure is placed as suggested.
For example:
python3 main.py --train_ae --dataset=surprise
--load_train_model_name=model.pth-ae-400000-128-multi-1024-english
--ckpt_dir=./ckpt_english or --ckpt_dir=./ckpt_surprise by default).--load_test_model_name=model.pth-ae-400000-128-multi-1024-english (by name)
--ckpt_pth=ckpt/model.pth-ae-400000-128-multi-1024-english (direct path)
128-multi-1024 model is being loaded, seg_len and enc_size should be set to 128 and 1024, respectively. If a ae model is being loaded, the argument --enc_only must be used when running main.py (See 4. in the Testing section).@article{Liu_2019,
title={Unsupervised End-to-End Learning of Discrete Linguistic Units for Voice Conversion},
url={http://dx.doi.org/10.21437/interspeech.2019-2048},
DOI={10.21437/interspeech.2019-2048},
journal={Interspeech 2019},
publisher={ISCA},
author={Liu, Andy T. and Hsu, Po-chun and Lee, Hung-Yi},
year={2019},
month={Sep}
}


