generative ai cybersecurity
1.0.0
Ce référentiel contient les matériaux et les scripts pour le discours intitulé "Generative IA in Cybersecurity: Génération de code offensif à partir du langage naturel" par Pietro Liguori, Université de Naples Federico II, Dessert Group. Le discours fait partie de l'artisan 2024: École d'été sur le rôle et les effets de l'intelligence artificielle dans des applications sécurisées .
Assurez-vous que Python soit installé sur votre système. Sinon, vous pouvez utiliser un environnement virtuel avec Anaconda pour éviter de travailler directement sur votre machine. Suivez les étapes ci-dessous:
wget pour télécharger l'installateur: wget https://repo.anaconda.com/archive/Anaconda3-version-OS.shchmod +x Anaconda3-version-OS.shbash Anaconda3-version-OS.shbashrc : export PATH= " /path_to_anaconda/anaconda3/bin: $PATH "Créez un environnement virtuel Python 3.9 :
conda create -n yourenvname python=3.9yourenvname par le nom de l'environnement souhaité.Activez l'environnement :
source activate yourenvnameVous êtes maintenant prêt à installer des dépendances et à travailler dans votre environnement virtuel.
Dans le dossier Violent-Python-functions , nous avons des fichiers .in et .out contenant les descriptions NL (langage naturel) et les fonctions Python correspondantes, respectivement.
L'ensemble de données Python violent est un ensemble de données organisé manuellement, où un échantillon contient un morceau de code Python d'un logiciel offensif, et sa description correspondante en langue naturelle (anglais simple). Nous avons construit l'ensemble de données en utilisant le livre populaire "Violent Python" de TJ O'Connor, qui présente plusieurs exemples de programmes offensifs en utilisant la langue Python.
Nous n'avons inclus que les descriptions au niveau de la fonction, totalisant 72 paires de descriptions NL - Fonctions Python.
Installez les dépendances :
pip install -r requirements.txt --userExtraction sous-ensemble :
create_subset.py avec la commande suivante: python create_subset.pyscripts/results contenant des fichiers reference.in et reference.out .reference.in contient les 10 descriptions NL extraites aléatoires.reference.out contient les 10 fonctions Python correspondantes et sert de vérité au sol pour l'évaluation.Ensuite, vous générerez 10 sorties à l'aide de modèles AI génératifs comme ChatGpt ou Claude Sonnet.
Prudence
Faites attention à la structure des extraits de code. Comme vous pouvez le voir, les codes Python sont tous une seule ligne . En fait, les instructions multi-lignes sont séparées les unes des autres avec n .
Générer des sorties :
reference.in pour générer les 10 sorties à l'aide des modèles AI.output.out dans le dossier results .Exemple d'invite:
Generate Python 10 functions starting from the following 10 natural language (NL) descriptions:
1. [NL description]
2. [NL description]
...
10. [NL description]
Each function should be generated in a single line, for a total of 10 lines.
Different instructions of the same function should be separated by the special character "n".
Do not use empty lines to separate functions.
Calculer les métriques de similitude de sortie :
scripts , exécutez le script Python output_similarity_metrics.py pour calculer les métriques de similitude de sortie entre les prédictions du modèle ( output.out ) et la référence de vérité au sol ( reference.out ): python output_similarity_metrics.py hypothesis_filehypothesis_file est le fichier results/output.out . Les mesures seront générées dans le fichier results/output_metrics.txt .
scripts , exécutez le script boxplot_metrics.py pour visualiser la variabilité des métriques enregistrées dans les results/output_metrics.txt : python boxplot_metrics.pyVous trouverez ci-dessous une image montrant la variabilité des mesures de similitude de sortie avec un boîtier à boîte:
results/output2.out .output_similarity_metrics.py pour calculer les métriques de similitude de sortie entre les prédictions du modèle ( output2.out ) et la référence de vérité au sol ( reference.out ): python output_similarity_metrics.py results/output2.outcompare_models.py pour afficher la comparaison de deux performances de modèles sur deux métriques python compare_models.pyVous trouverez ci-dessous un exemple de la sortie:
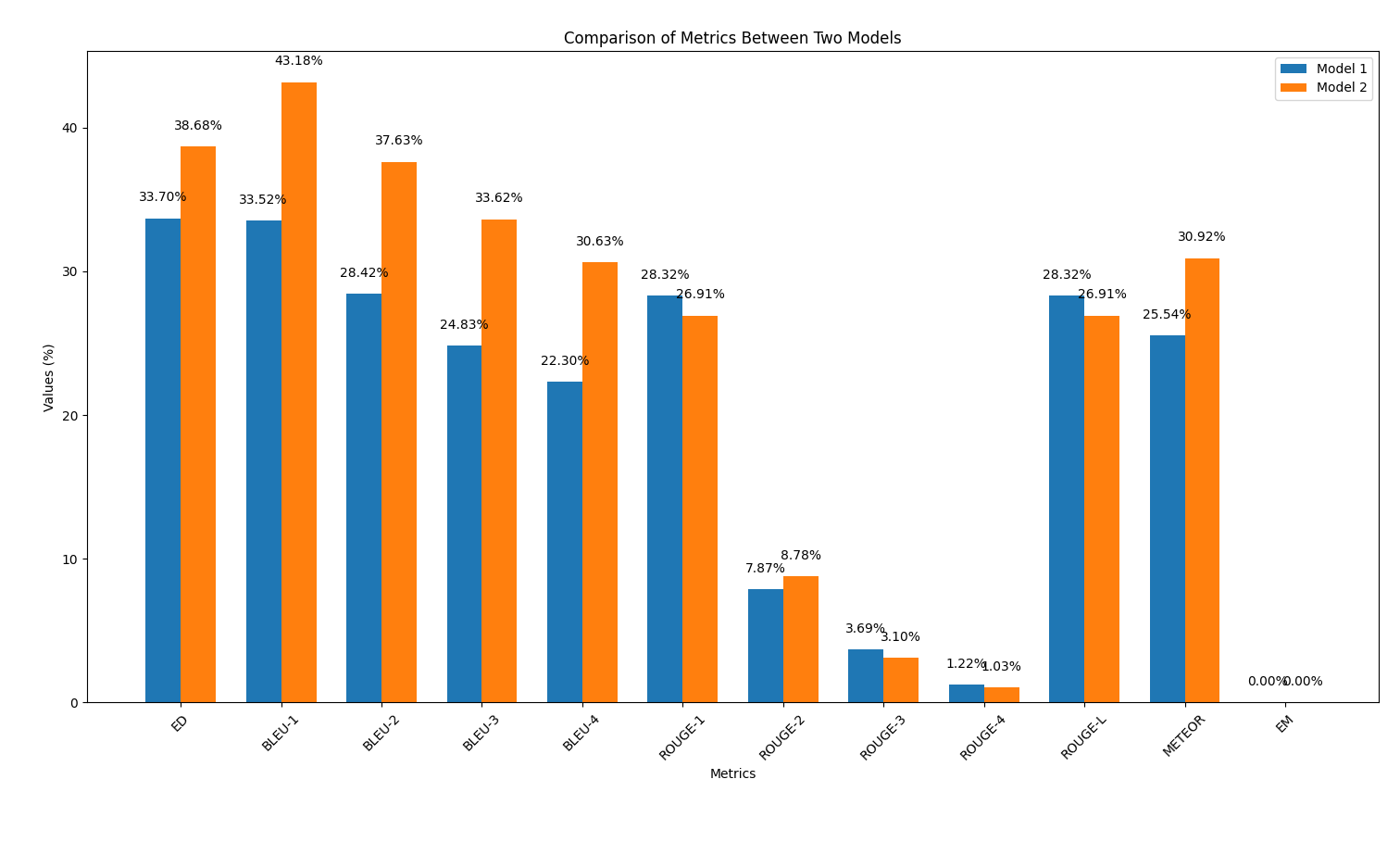
Dans cette partie, nous répéterons le processus de génération de code à l'aide des modèles d'IA, mais cette fois en appliquant une technique d'ingénierie rapide discutée lors de la conférence. L'objectif est d'observer si cette technique améliore la qualité du code généré.
Appliquer l'ingénierie rapide :
reference.in . Des exemples d'invites peuvent être trouvés dans le dossier scripts/prompt_examples .
Générer des sorties :
output_prompt_pattern.out dans le dossier scripts/results , où prompt_pattern est un identifiant que vous souhaitez utiliser pour spécifier le modèle adopté (par exemple, output_persona.out , output_few_shot.out ).Calculer les métriques de similitude de sortie :
scripts , exécutez le script pour calculer les mesures de similitude de sortie entre les prédictions du modèle ( output_prompt_pattern.out ) et la référence de vérité au sol ( reference.out ): python output_similarity_metrics.py hypothesis_file où hypothesis_file est le fichier généré avec un modèle invite (par exemple, le fichier results/output_few_shot.out ).
scripts/results/output_prompt_engineering_metrics.txt (par exemple, scripts/results/output_few_shot_metrics.txt fichier).Comparez les résultats :
scripts , exécutez le script plot_metrics_comparison.py pour comparer les résultats: python plot_metrics_comparison.py file_metricsfile_metrics est scripts/results/output_prompt_engineering_metrics.txt fichier.Vous trouverez ci-dessous une image montrant la comparaison des mesures entre les sorties générées sans ingénierie rapide et avec ingénierie rapide à quelques coups:
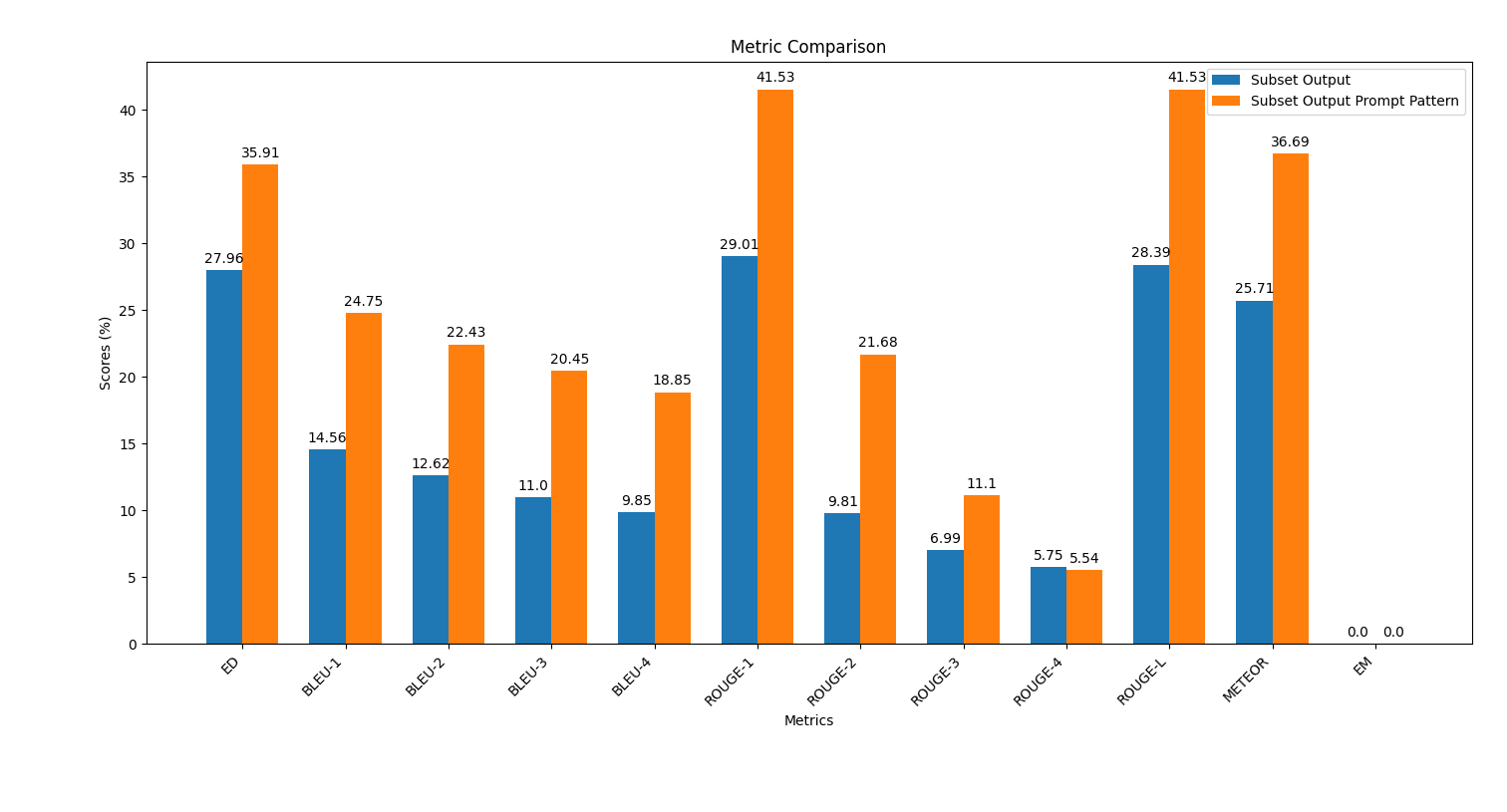
Suivez ces étapes pour appliquer l'ingénierie rapide et évaluer son impact sur la qualité de la génération de code.
Dans le dossier saved_outputs , vous trouverez des exemples générés avec ChatGPT-4O. Ces exemples illustrent à quoi ressemblent les sorties du modèle avec différentes techniques d'ingénierie rapide appliquées.
Ce référentiel et les matériaux ont été développés par:


