generative ai cybersecurity
1.0.0
Dieses Repository enthält die Materialien und Skripte für den Vortrag mit dem Titel "Generative AI in Cybersicherheit: Erzeugung von Offensivcode aus der Natursprache" von Pietro Liguori, Universität Naples Federico II, Dessert Group. Der Vortrag ist Teil von Artisan 2024: Sommerschule über die Rolle und die Auswirkungen künstlicher Intelligenz in sicheren Anwendungen .
Stellen Sie sicher, dass Sie Python auf Ihrem System installiert haben. Wenn nicht, können Sie eine virtuelle Umgebung mit Anaconda verwenden, um nicht direkt auf Ihrer Maschine zu arbeiten. Befolgen Sie die folgenden Schritte:
wget , um das Installateur herunterzuladen: wget https://repo.anaconda.com/archive/Anaconda3-version-OS.shchmod +x Anaconda3-version-OS.shbash Anaconda3-version-OS.shbashrc -Datei hinzu: export PATH= " /path_to_anaconda/anaconda3/bin: $PATH "Erstellen Sie eine virtuelle Python 3.9 -Umgebung :
conda create -n yourenvname python=3.9yourenvname durch Ihren gewünschten Umgebungsnamen.Aktivieren Sie die Umgebung :
source activate yourenvnameSie sind jetzt bereit, Abhängigkeiten zu installieren und in Ihrer virtuellen Umgebung zu arbeiten.
Im Ordner Violent-Python-functions haben wir .in und .out Dateien, die die NL-Beschreibungen (Natural Language) bzw. die entsprechenden Python-Funktionen enthalten.
Der gewalttätige Python -Datensatz ist ein manuell kuratierter Datensatz, in dem ein Beispiel ein Stück Python -Code aus einer offensiven Software und seine entsprechende Beschreibung in der natürlichen Sprache (einfach Englisch) enthält. Wir haben den Datensatz mit dem beliebten Buch "Violent Python" von TJ O'Connor erstellt, in dem mehrere Beispiele für offensive Programme mithilfe der Python -Sprache vorgestellt werden.
Wir haben nur die Beschreibungen auf Funktionsebene mit insgesamt 72 Paaren von NL -Beschreibungen aufgenommen - Python -Funktionen.
Abhängigkeiten installieren :
pip install -r requirements.txt --userUntergruppenextraktion :
create_subset.py mit dem folgenden Befehl aus: python create_subset.pyscripts/results mit reference.in und reference.out -Dateien.reference.in -Datei enthält die 10 zufällig extrahierten NL -Beschreibungen.reference.out -Datei enthält die entsprechenden 10 Python -Funktionen und dient als Grundwahrheit für die Bewertung.Als nächstes generieren Sie 10 Ausgänge mit generativen KI -Modellen wie Chatgpt oder Claude -Sonnet.
Vorsicht
Achten Sie auf die Struktur der Code -Snippets. Wie Sie sehen können, sind die Python-Codes alle einzeln . Tatsächlich werden Multi-Line-Anweisungen mit n voneinander getrennt.
Ausgänge erzeugen :
reference.in -Datei gespeicherten NL -Beschreibungen, um die 10 Ausgänge mit den AI -Modellen zu generieren.output.out im results .Beispielaufforderung:
Generate Python 10 functions starting from the following 10 natural language (NL) descriptions:
1. [NL description]
2. [NL description]
...
10. [NL description]
Each function should be generated in a single line, for a total of 10 lines.
Different instructions of the same function should be separated by the special character "n".
Do not use empty lines to separate functions.
Berechnen Sie Ausgangsähnlichkeitsmetriken :
reference.out im scripts -Ordner die Python output.out output_similarity_metrics.py . python output_similarity_metrics.py hypothesis_filehypothesis_file die Datei der results/output.out ist. Die Metriken werden in der Datei results/output_metrics.txt generiert.
scripts die script boxplot_metrics.py aus, um die Variabilität der in der results/output_metrics.txt gespeicherten Metriken zu visualisieren: python boxplot_metrics.pyIm Folgenden finden Sie ein Bild, das die Variabilität der Ausgangsähnlichkeitsmetriken mit einem Boxplot zeigt:
results/output2.out zu speichern.output2.out erneut die Python -Skript output_similarity_metrics.py reference.out python output_similarity_metrics.py results/output2.outcompare_models.py aus, um den Vergleich von zwei Modelsleistung über zwei Metriken hinweg anzuzeigen python compare_models.pyUnten finden Sie ein Beispiel für die Ausgabe:
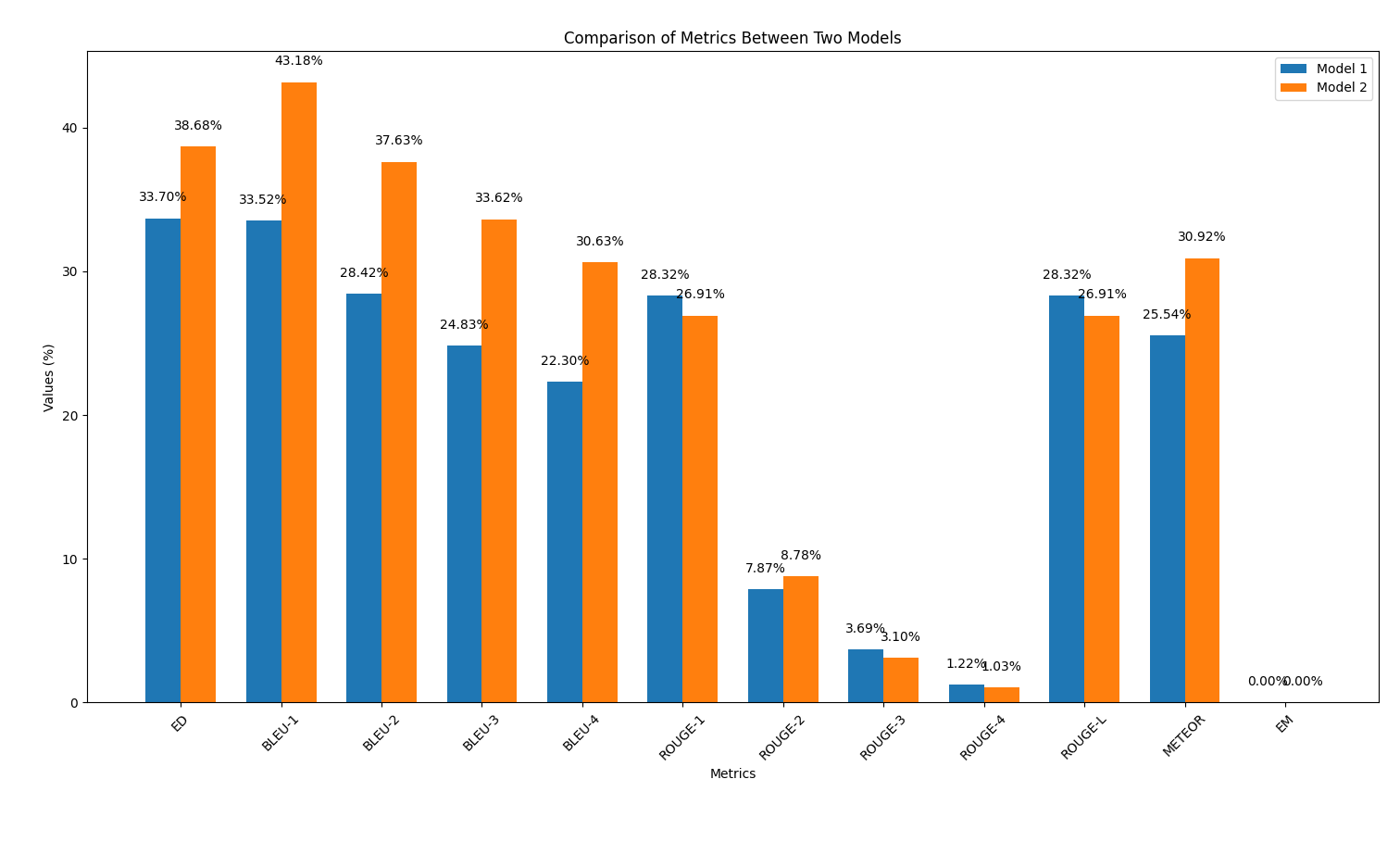
In diesem Teil wiederholen wir den Code -Erzeugungsprozess mithilfe der KI -Modelle. Diesmal wird jedoch eine schnelle technische Technik angewendet, die während des Vortrags diskutiert wird. Ziel ist es zu beobachten, ob diese Technik die Qualität des generierten Codes verbessert.
Bewerben Sie schnelle Engineering :
reference.in gespeichert sind. Beispiele für Eingabeaufforderungen finden Sie im Ordner scripts/prompt_examples .
Ausgänge erzeugen :
output_prompt_pattern.out im Ordner scripts/results , wobei prompt_pattern eine Kennung ist, mit der Sie das angenommene Muster angeben möchten (z. B. output_persona.out , output_few_shot.out ).Berechnen Sie Ausgangsähnlichkeitsmetriken :
scripts -Ordner das Skript aus, um die Ausgangsähnlichkeitsmetriken zwischen den Modellvorhersagen ( output_prompt_pattern.out ) und der Grundwahrheitsreferenz ( reference.out ) zu berechnen: python output_similarity_metrics.py hypothesis_file wobei hypothesis_file die Datei ist, die mit einem Eingabeaufforderungmuster generiert wird (z. B. results/output_few_shot.out -Datei).
scripts/results/output_prompt_engineering_metrics.txt generiert (z. B. scripts/results/output_few_shot_metrics.txt -Datei).Vergleichen Sie die Ergebnisse :
scripts -Ordner die Skript plot_metrics_comparison.py aus, um die Ergebnisse zu vergleichen: python plot_metrics_comparison.py file_metricsfile_metrics scripts/results/output_prompt_engineering_metrics.txt -Datei ist.Im Folgenden finden Sie ein Bild, das den Vergleich von Metriken zwischen den ohne sofortigen Engineering erzeugten Ausgaben und mit wenigen Schuss-Eingabeaufforderungstechnik zeigt:
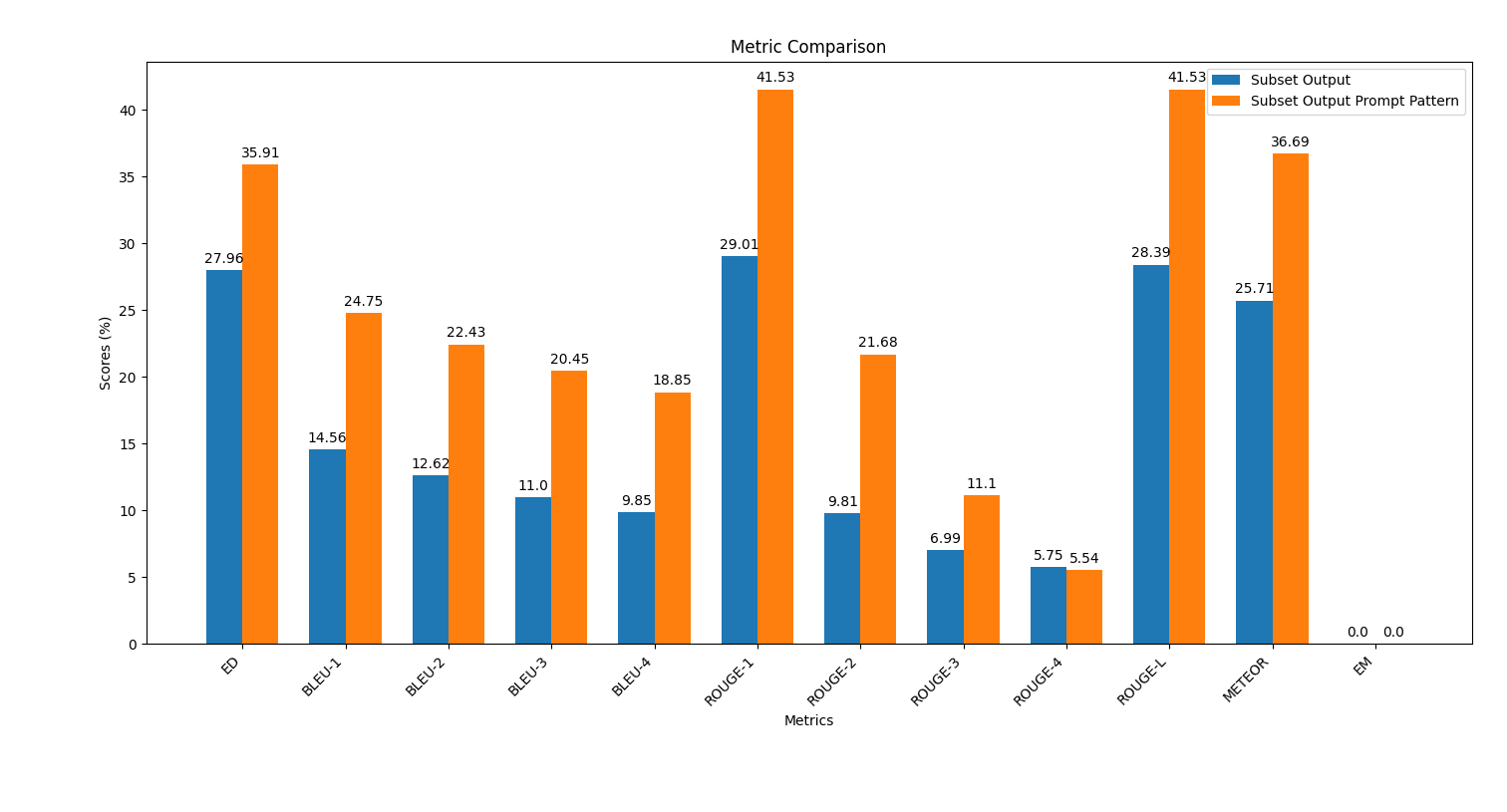
Befolgen Sie die folgenden Schritte, um eine schnelle Technik anzuwenden und die Auswirkungen auf die Qualität der Codegenerierung zu bewerten.
Im Ordner saved_outputs finden Sie Beispiele, die mit ChatGPT-4O erzeugt wurden. Diese Beispiele veranschaulichen, wie die Ausgaben des Modells mit verschiedenen angewandten technischen Techniken aussehen.
Dieses Repository und die Materialien wurden entwickelt von:


