generative ai cybersecurity
1.0.0
Этот репозиторий содержит материалы и сценарии для разговора под названием «Генеративный ИИ в кибербезопасности: генерирование наступательного кода от естественного языка» Пьетро Лигуори, Университет Неаполя Федерико II, десертная группа. Разговор является частью Artisan 2024: Летняя школа о роли и последствиях искусственного интеллекта в безопасных приложениях .
Убедитесь, что у вас установлен Python в вашей системе. Если нет, вы можете использовать виртуальную среду с Anaconda, чтобы не работать непосредственно на вашей машине. Следуйте шагам ниже:
wget для загрузки установщика: wget https://repo.anaconda.com/archive/Anaconda3-version-OS.shchmod +x Anaconda3-version-OS.shbash Anaconda3-version-OS.shbashrc : export PATH= " /path_to_anaconda/anaconda3/bin: $PATH "Создайте виртуальную среду Python 3.9 :
conda create -n yourenvname python=3.9yourenvname на желаемое название среды.Активируйте окружающую среду :
source activate yourenvnameТеперь вы готовы установить зависимости и работать в своей виртуальной среде.
В папке Violent-Python-functions у нас есть файлы .in и .out , содержащие описания NL (естественный язык) и соответствующие функции Python, соответственно.
Набор данных Python - это набор данных вручную куратор, где образец содержит кусок кода Python из наступательного программного обеспечения и его соответствующее описание на естественном языке (простой английский). Мы построили набор данных, используя популярную книгу «Насильственный питон» TJ O'Connor, в которой представлены несколько примеров оскорбительных программ с использованием языка Python.
Мы включили только описания на уровне функции, в общей сложности 72 пары описаний NL - функции Python.
Установить зависимости :
pip install -r requirements.txt --userИзвлечение подмножество :
create_subset.py со следующей командой: python create_subset.pyscripts/results содержащую reference.in и reference.out files.reference.in содержит 10 случайно извлеченных описаний NL.reference.out содержит соответствующие 10 функций Python и служит нашей основной истиной для оценки.Затем вы будете генерировать 10 выходов, используя генеративные модели искусственного интеллекта, такие как CHATGPT или Claude Sonnet.
Осторожность
Обратите внимание на структуру фрагментов кода. Как вы можете видеть, коды Python все однострочные . Фактически, многострочные инструкции отделены друг от друга с n .
Генерировать выходы :
reference.in для генерации 10 выходов с использованием моделей ИИ.output.out в папке results .Пример подсказки:
Generate Python 10 functions starting from the following 10 natural language (NL) descriptions:
1. [NL description]
2. [NL description]
...
10. [NL description]
Each function should be generated in a single line, for a total of 10 lines.
Different instructions of the same function should be separated by the special character "n".
Do not use empty lines to separate functions.
Рассчитайте показатели сходства вывода :
scripts запустите Python Script output_similarity_metrics.py для вычисления показателей сходства выходных данных между предсказаниями модели ( output.out ) и ссылкой на основание истины ( reference.out ): python output_similarity_metrics.py hypothesis_filehypothesis_file является файлом results/output.out . Метрики будут сгенерированы в файле results/output_metrics.txt .
scripts выполните Script boxplot_metrics.py , чтобы визуализировать изменчивость метрик, сохраненные в results/output_metrics.txt : python boxplot_metrics.pyНиже приведено изображение, показывающее изменчивость метрик сходства вывода с помощью ящика:
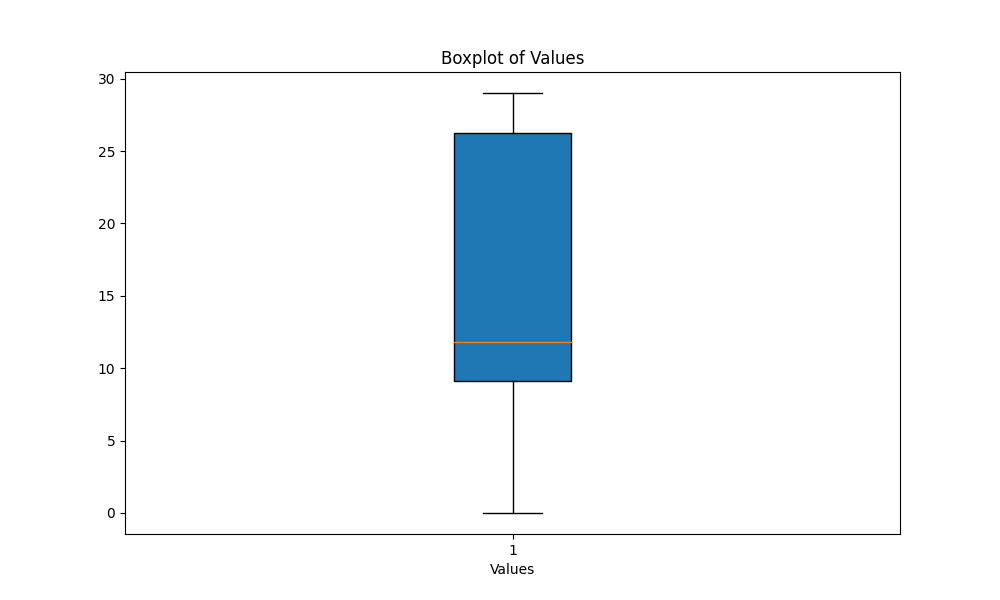
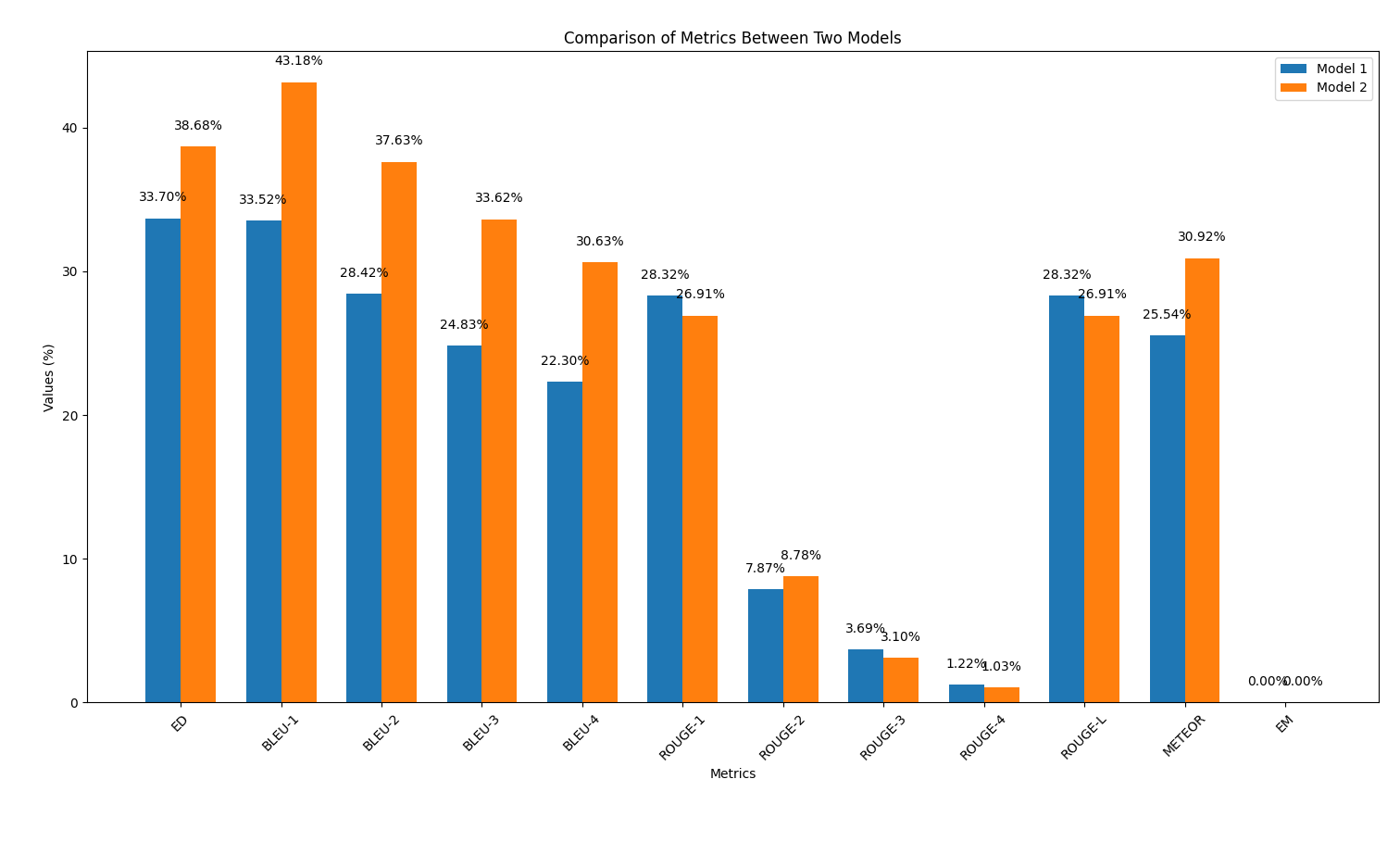
results/output2.out .reference.out Python Script output_similarity_metrics.py для вычисления показателей выходной сходства между прогнозами модели ( output2.out . python output_similarity_metrics.py results/output2.outcompare_models.py , чтобы показать сравнение двух моделей производительности в двух метрик. python compare_models.pyНиже приведен пример вывода:
В этой части мы повторим процесс генерации кода, используя модели искусственного интеллекта, но на этот раз применяя быструю технику инженерной техники, обсуждаемую во время разговора. Цель состоит в том, чтобы наблюдать, улучшает ли этот метод качество сгенерированного кода.
Применить быстрое инженер :
reference.in . Примеры подсказок можно найти в папке scripts/prompt_examples .
Генерировать выходы :
output_prompt_pattern.out в папке scripts/results , где prompt_pattern - это идентификатор, который вы хотите использовать для указания принятого шаблона (например, output_persona.out , output_few_shot.out ).Рассчитайте показатели сходства вывода :
scripts запустите скрипт, чтобы вычислять показатели сходства выходных данных между прогнозами модели ( output_prompt_pattern.out ) и ссылкой reference.out истинность основной python output_similarity_metrics.py hypothesis_file где hypothesis_file - это файл, сгенерированный с шаблоном приглашения (например, файл results/output_few_shot.out ).
scripts/results/output_prompt_engineering_metrics.txt (например, scripts/results/output_few_shot_metrics.txt file).Сравните результаты :
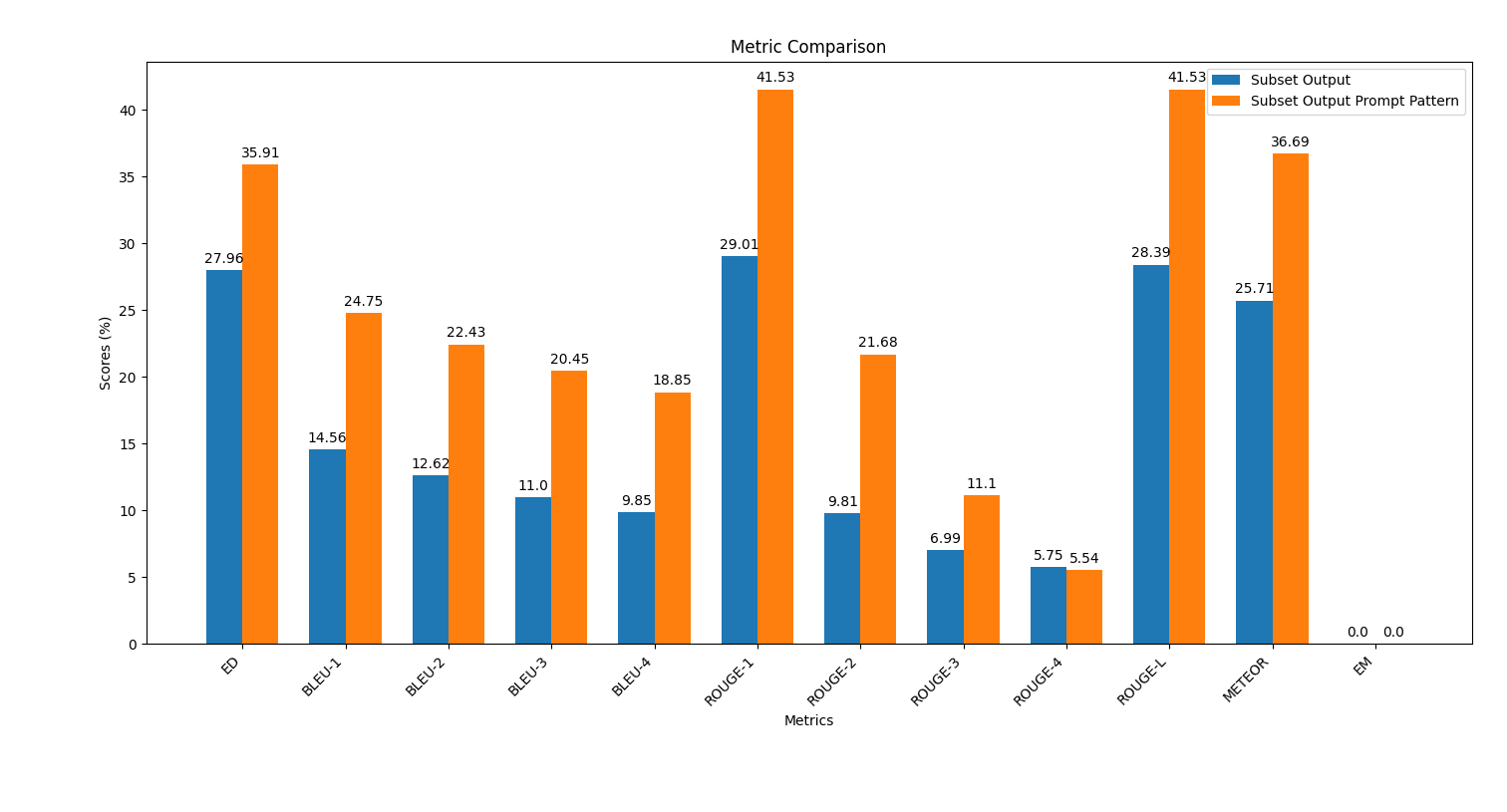
scripts выполните Script plot_metrics_comparison.py , чтобы сравнить результаты: python plot_metrics_comparison.py file_metricsfile_metrics - это scripts/results/output_prompt_engineering_metrics.txt файл.Ниже приведено изображение, показывающее сравнение метриков между выходами, сгенерированными без быстрого инженера и с несколькими выстрелами, разработка:
Следуйте этим шагам, чтобы применять быструю технику и оценить его влияние на качество генерации кода.
В папке saved_outputs вы найдете примеры, сгенерированные с помощью CHATGPT-4O. Эти примеры иллюстрируют, как выглядят выходы модели с применением различных применяемых технических методов быстрого разработки.
Этот репозиторий и материалы были разработаны:


