generative ai cybersecurity
1.0.0
Este repositorio contiene los materiales y guiones para la charla titulada "IA generativa en ciberseguridad: generar código ofensivo del lenguaje natural" por Pietro Liguori, Universidad de Nápoles Federico II, grupo de postres. La charla es parte de Artisan 2024: School de verano sobre el papel y los efectos de la inteligencia artificial en aplicaciones seguras .
Asegúrese de tener Python instalado en su sistema. Si no, puede usar un entorno virtual con Anaconda para evitar trabajar directamente en su máquina. Siga los pasos a continuación:
wget para descargar el instalador: wget https://repo.anaconda.com/archive/Anaconda3-version-OS.shchmod +x Anaconda3-version-OS.shbash Anaconda3-version-OS.shbashrc : export PATH= " /path_to_anaconda/anaconda3/bin: $PATH "Crea un entorno virtual Python 3.9 :
conda create -n yourenvname python=3.9yourenvname con su nombre de entorno deseado.Activar el entorno :
source activate yourenvnameAhora está listo para instalar dependencias y trabajar dentro de su entorno virtual.
En la carpeta Violent-Python-functions , tenemos archivos .in y .out que contienen las descripciones de NL (lenguaje natural) y las funciones de pitón correspondientes, respectivamente.
El violento conjunto de datos de Python es un conjunto de datos curado manualmente, donde una muestra contiene una pieza de código Python de un software ofensivo y su descripción correspondiente en lenguaje natural (inglés simple). Construimos el conjunto de datos utilizando el popular libro "Violent Python" de TJ O'Connor, que presenta varios ejemplos de programas ofensivos utilizando el lenguaje Python.
Hemos incluido solo las descripciones a nivel de función, totalizando 72 pares de descripciones de NL: funciones de Python.
Instalar dependencias :
pip install -r requirements.txt --userExtracción de subconjunto :
create_subset.py con el siguiente comando: python create_subset.pyscripts/results que contiene reference.in y reference.out archivos.reference.in contiene las 10 descripciones de NL extraídas al azar.reference.out contiene las 10 funciones de Python correspondientes y sirve como nuestra verdad fundamental para la evaluación.A continuación, generará 10 salidas utilizando modelos AI generativos como ChatGPT o Claude Sonnet.
Precaución
Presta atención a la estructura de los fragmentos de código. Como puede ver, los códigos de Python son todos una sola línea . De hecho, las instrucciones de varias líneas se separan entre sí con n .
Generar salidas :
reference.in para generar las 10 salidas utilizando los modelos AI.output.out en la carpeta results .Solicitud de ejemplo:
Generate Python 10 functions starting from the following 10 natural language (NL) descriptions:
1. [NL description]
2. [NL description]
...
10. [NL description]
Each function should be generated in a single line, for a total of 10 lines.
Different instructions of the same function should be separated by the special character "n".
Do not use empty lines to separate functions.
Calcule las métricas de similitud de salida :
scripts , ejecute el script Python script output_similarity_metrics.py para calcular las métricas de similitud de salida entre las predicciones del modelo ( output.out ) y la referencia de la verdad de tierra ( reference.out ):: python output_similarity_metrics.py hypothesis_filehypothesis_file es el archivo results/output.out . Las métricas se generarán en el archivo results/output_metrics.txt .
scripts , ejecute el script boxplot_metrics.py para visualizar la variabilidad de las métricas guardadas en el archivo results/output_metrics.txt : python boxplot_metrics.pyA continuación se muestra una imagen que muestra la variabilidad de las métricas de similitud de salida con un diagrama de caja:
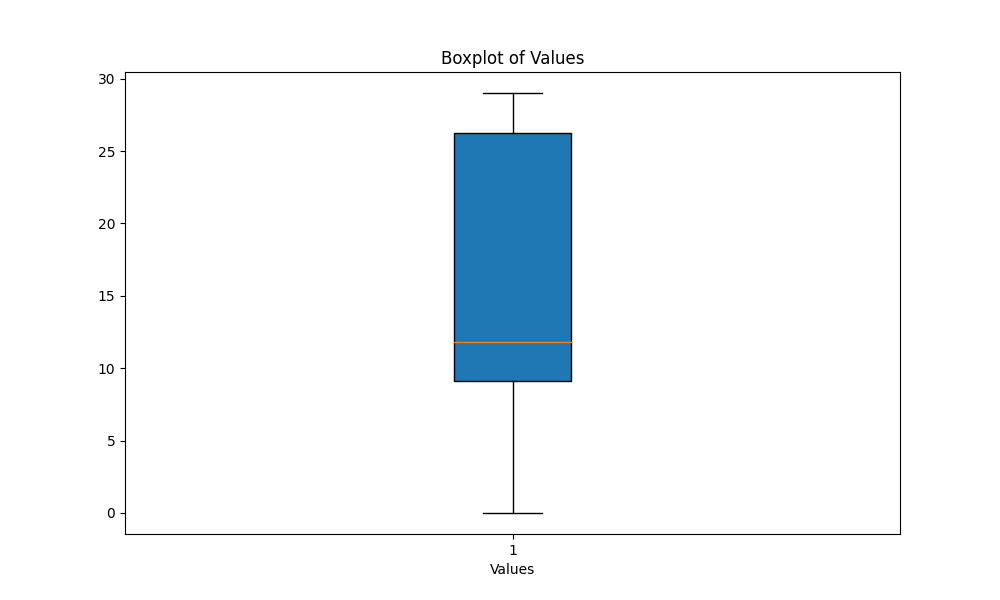
results/output2.out .output_similarity_metrics.py para calcular las métricas de similitud de salida entre las predicciones del modelo ( output2.out ) y la referencia de la verdad del suelo ( reference.out ):: python output_similarity_metrics.py results/output2.outcompare_models.py para mostrar la comparación de dos modelos de rendimiento en dos métricas python compare_models.pyA continuación se muestra un ejemplo de la salida:
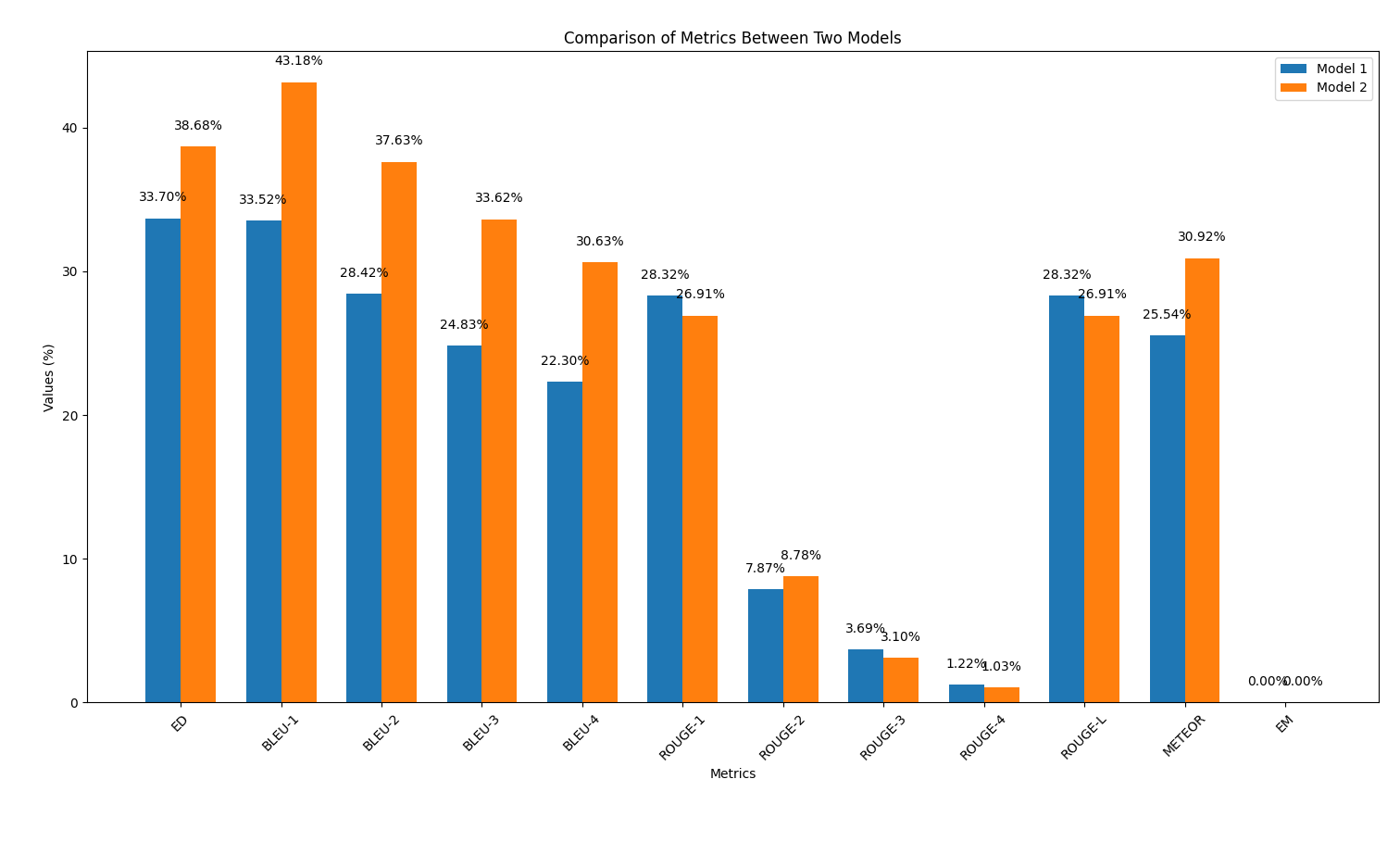
En esta parte, repetiremos el proceso de generación de código utilizando los modelos AI, pero esta vez aplicando una técnica de ingeniería rápida discutida durante la charla. El objetivo es observar si esta técnica mejora la calidad del código generado.
Aplicar ingeniería rápida :
reference.in . Se pueden encontrar ejemplos de indicaciones en la carpeta scripts/prompt_examples .
Generar salidas :
output_prompt_pattern.out en la carpeta scripts/results , donde prompt_pattern es un identificador que desea usar para especificar el patrón adoptado (por ejemplo, output_persona.out , output_few_shot.out ).Calcule las métricas de similitud de salida :
scripts , ejecute el script para calcular las métricas de similitud de salida entre las predicciones del modelo ( output_prompt_pattern.out ) y la referencia de la verdad del suelo ( reference.out ): python output_similarity_metrics.py hypothesis_file donde hypothesis_file es el archivo generado con un patrón de solicitud (por ejemplo, results/output_few_shot.out archivo).
scripts/results/output_prompt_engineering_metrics.txt (por ejemplo, scripts/results/output_few_shot_metrics.txt archivo).Compare los resultados :
scripts , ejecute el script plot_metrics_comparison.py para comparar los resultados: python plot_metrics_comparison.py file_metricsfile_metrics es scripts/results/output_prompt_engineering_metrics.txt archivo.A continuación se muestra una imagen que muestra la comparación de métricas entre las salidas generadas sin ingeniería rápida y con ingeniería rápida de pocos disparos:
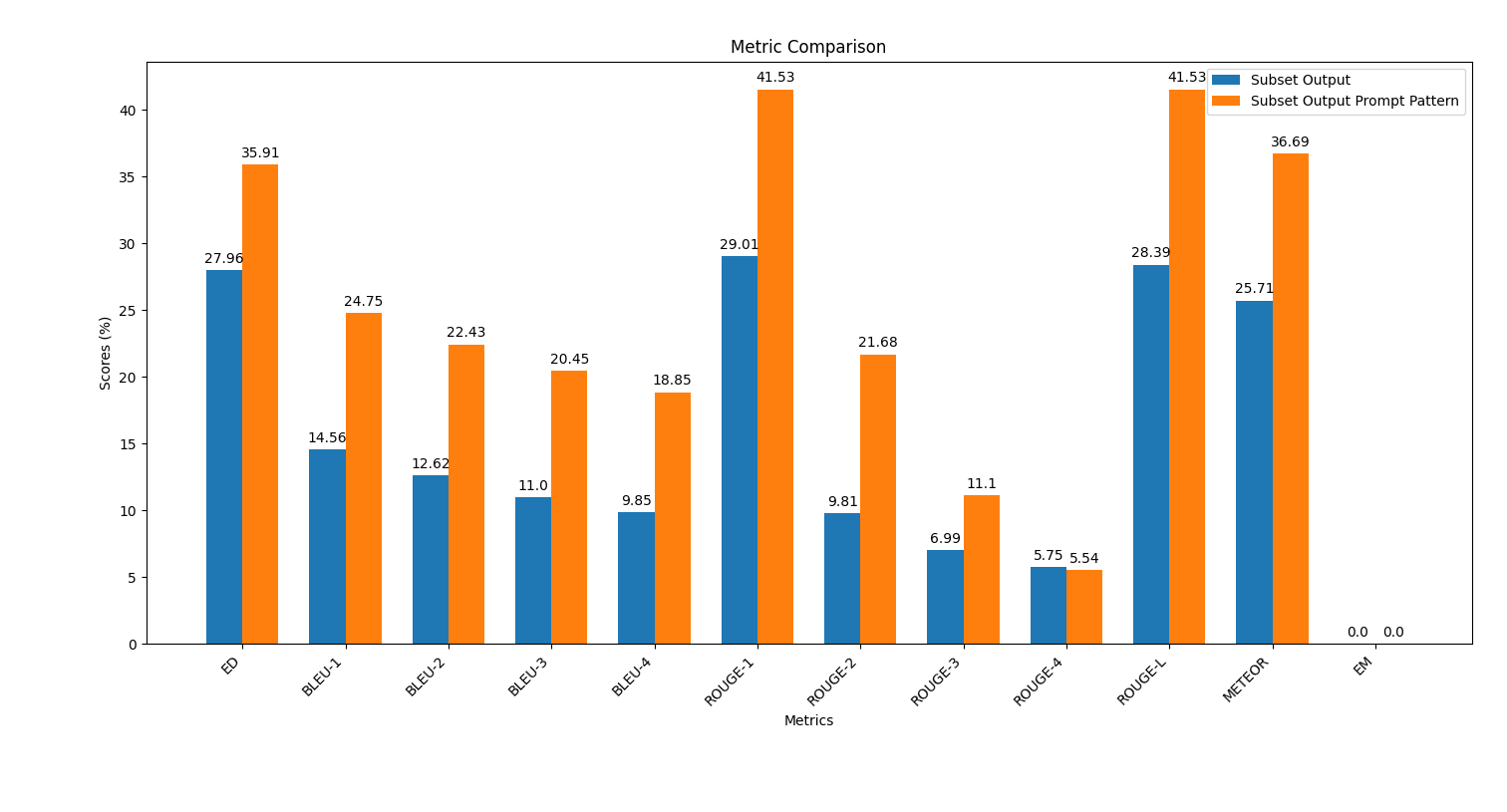
Siga estos pasos para aplicar ingeniería rápida y evaluar su impacto en la calidad de la generación de código.
En la carpeta saved_outputs , encontrará ejemplos generados con ChatGPT-4O. Estos ejemplos ilustran cómo se ven las salidas del modelo con diferentes técnicas de ingeniería rápida aplicadas.
Este repositorio y los materiales fueron desarrollados por:


