generative ai cybersecurity
1.0.0
Este repositório contém os materiais e scripts para a palestra intitulada "IA generativa em segurança cibernética: gerando código ofensivo a partir da linguagem natural" de Pietro Liguori, Universidade de Nápoles Federico II, Grupo de sobremesas. A palestra faz parte do Artisan 2024: Escola de Verão sobre o papel e os efeitos da inteligência artificial em aplicações seguras .
Certifique -se de instalar o Python no seu sistema. Caso contrário, você pode usar um ambiente virtual com a Anaconda para evitar trabalhar diretamente em sua máquina. Siga as etapas abaixo:
wget para baixar o instalador: wget https://repo.anaconda.com/archive/Anaconda3-version-OS.shchmod +x Anaconda3-version-OS.shbash Anaconda3-version-OS.shbashrc : export PATH= " /path_to_anaconda/anaconda3/bin: $PATH "Crie um ambiente virtual Python 3.9 :
conda create -n yourenvname python=3.9yourenvname do seu nome de ambiente desejado.Ative o ambiente :
source activate yourenvnameAgora você está pronto para instalar dependências e trabalhar em seu ambiente virtual.
Na pasta Violent-Python-functions , temos arquivos .in e .out contendo as descrições de NL (linguagem natural) e as funções Python correspondentes, respectivamente.
O conjunto de dados violento do Python é um conjunto de dados com curadoria manual, onde uma amostra contém um código Python de um software ofensivo e sua descrição correspondente na linguagem natural (inglês simples). Construímos o conjunto de dados usando o popular livro "Violent Python" de TJ O'Connor, que apresenta vários exemplos de programas ofensivos usando o idioma Python.
Incluímos apenas as descrições no nível da função, totalizando 72 pares de descrições de NL - funções python.
Instale dependências :
pip install -r requirements.txt --userExtração de subconjuntos :
create_subset.py com o seguinte comando: python create_subset.pyscripts/results que contêm reference.in e reference.out Arquivos.reference.in contém as 10 descrições de NL extraídas aleatoriamente.reference.out contém as 10 funções python correspondentes e serve como nossa verdade para a avaliação.Em seguida, você gerará 10 saídas usando modelos generativos de IA como ChatGPT ou Claude Sonnet.
Cuidado
Preste atenção à estrutura dos trechos de código. Como você pode ver, os códigos Python são todos de linha única . De fato, as instruções de várias linhas são separadas uma da outra com n .
Gerar saídas :
reference.in para gerar as 10 saídas usando os modelos AI.output.out na pasta results .Exemplo de prompt:
Generate Python 10 functions starting from the following 10 natural language (NL) descriptions:
1. [NL description]
2. [NL description]
...
10. [NL description]
Each function should be generated in a single line, for a total of 10 lines.
Different instructions of the same function should be separated by the special character "n".
Do not use empty lines to separate functions.
Calcule métricas de similaridade de saída :
scripts , execute o script python output_similarity_metrics.py para calcular as métricas de similaridade de saída entre as previsões do modelo ( output.out ) e a referência da verdade ( reference.out ): python output_similarity_metrics.py hypothesis_filehypothesis_file é o arquivo results/output.out . As métricas serão geradas no arquivo results/output_metrics.txt .
scripts , execute o script boxplot_metrics.py para visualizar a variabilidade das métricas salvas nos results/output_metrics.txt : python boxplot_metrics.pyAbaixo está uma imagem que mostra a variabilidade das métricas de similaridade de saída com um boxplot:
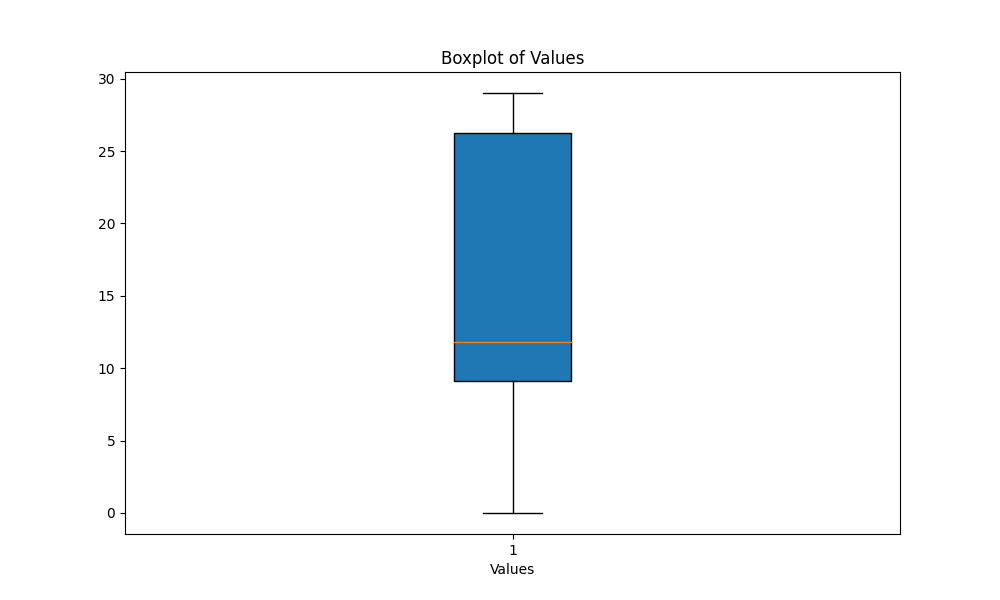
results/output2.out .output_similarity_metrics.py para calcular as métricas de similaridade de saída entre as previsões do modelo ( output2.out ) e a referência da verdade do solo ( reference.out ): python output_similarity_metrics.py results/output2.outcompare_models.py para mostrar a comparação de dois modelos de desempenho em duas métricas python compare_models.pyAbaixo está um exemplo da saída:
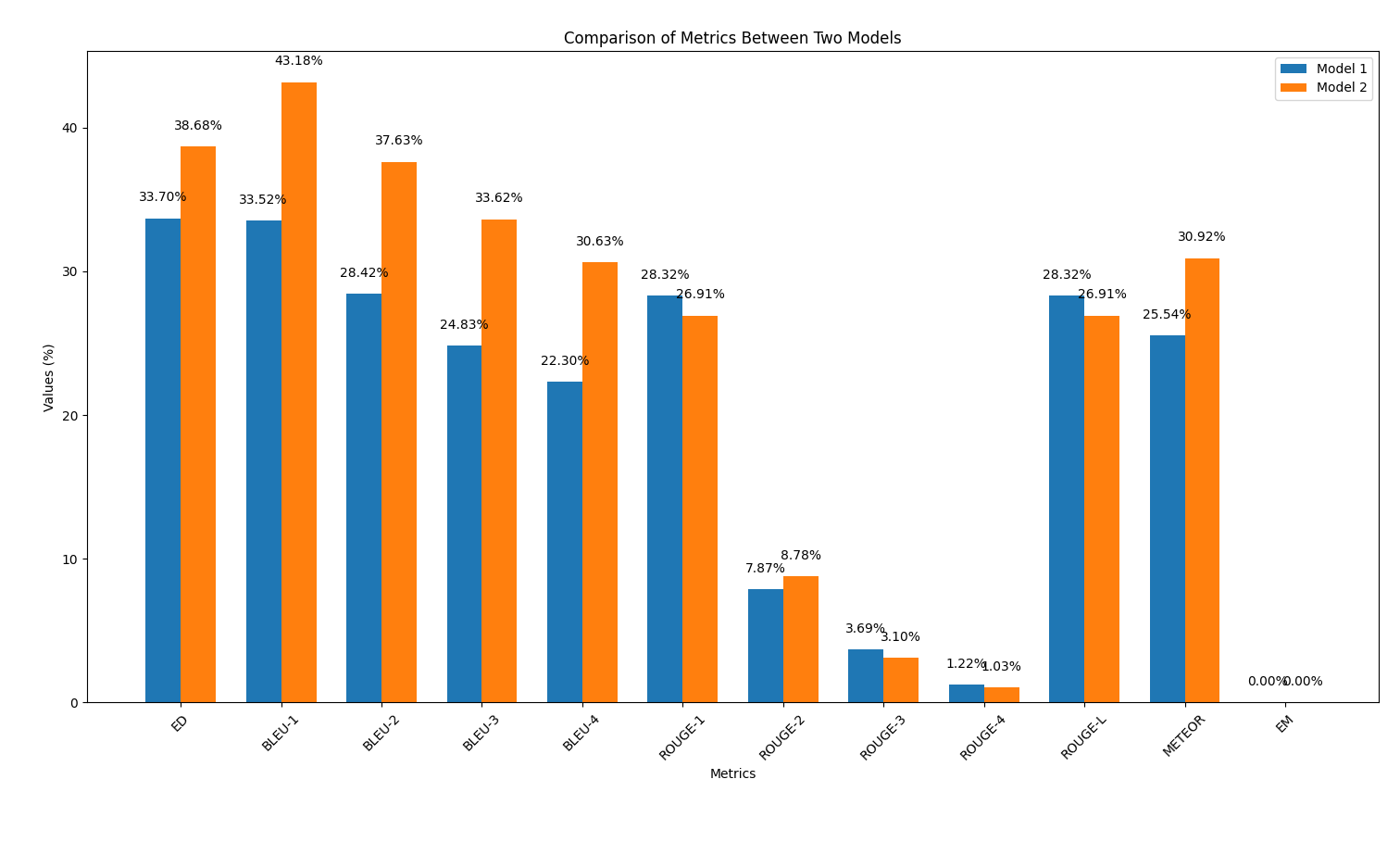
Nesta parte, repetiremos o processo de geração de código usando os modelos de IA, mas desta vez aplicava uma técnica de engenharia rápida discutida durante a palestra. O objetivo é observar se essa técnica melhora a qualidade do código gerado.
Aplique engenharia rápida :
reference.in . Exemplos de instruções podem ser encontrados na pasta scripts/prompt_examples .
Gerar saídas :
output_prompt_pattern.out na pasta scripts/results , onde prompt_pattern é um identificador que você deseja usar para especificar o padrão adotado (por exemplo, output_persona.out , output_few_shot.out ).Calcule métricas de similaridade de saída :
scripts , execute o script para calcular as métricas de similaridade de saída entre as previsões do modelo ( output_prompt_pattern.out ) e a referência da verdade do solo ( reference.out ): python output_similarity_metrics.py hypothesis_file onde hypothesis_file é o arquivo gerado com um padrão rápido (por exemplo, results/output_few_shot.out arquivo).
scripts/results/output_prompt_engineering_metrics.txt (por exemplo, scripts/results/output_few_shot_metrics.txt arquivo).Compare os resultados :
scripts , execute o script plot_metrics_comparison.py para comparar os resultados: python plot_metrics_comparison.py file_metricsfile_metrics é scripts/results/output_prompt_engineering_metrics.txt arquivo.Abaixo está uma imagem que mostra a comparação de métricas entre as saídas geradas sem engenharia imediata e com poucas engenharia de prompt de tiro:
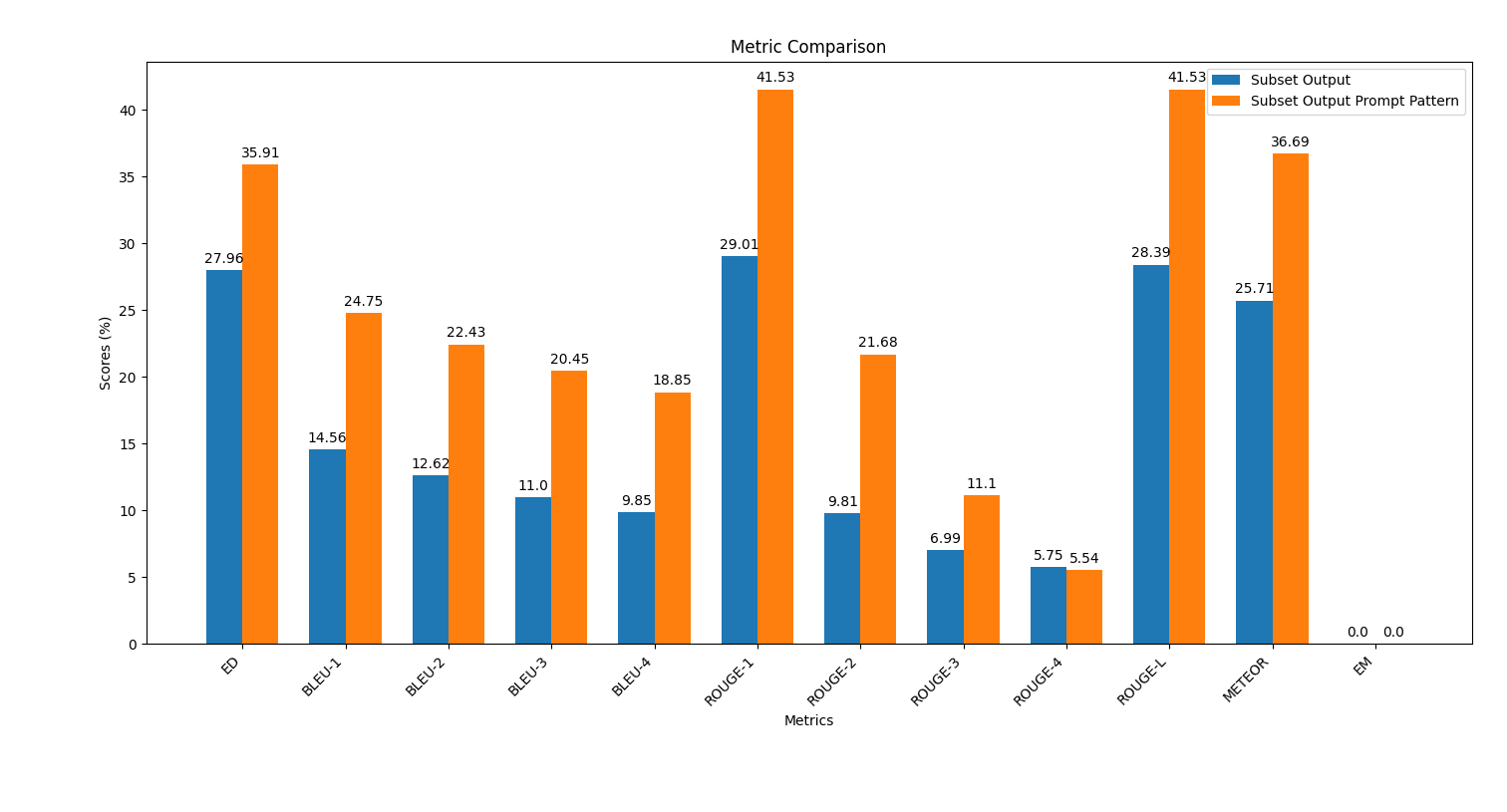
Siga estas etapas para aplicar engenharia imediata e avaliar seu impacto na qualidade da geração de código.
Na pasta saved_outputs , você encontrará exemplos gerados com ChatGPT-4O. Esses exemplos ilustram como as saídas do modelo se parecem com diferentes técnicas de engenharia rápidas aplicadas.
Este repositório e os materiais foram desenvolvidos por:


