generative ai cybersecurity
1.0.0
พื้นที่เก็บข้อมูลนี้มีวัสดุและสคริปต์สำหรับการพูดคุยเรื่อง "Generative AI ใน Cybersecurity: การสร้างรหัสที่น่ารังเกียจจากภาษาธรรมชาติ" โดย Pietro Liguori, University of Naples Federico II, กลุ่มของหวาน การพูดคุยเป็นส่วนหนึ่งของ Artisan 2024: Summer School เกี่ยวกับบทบาทและผลกระทบของปัญญาประดิษฐ์ในการใช้งานที่ปลอดภัย
ตรวจสอบให้แน่ใจว่าคุณติดตั้ง Python ในระบบของคุณ ถ้าไม่คุณสามารถใช้สภาพแวดล้อมเสมือนจริงกับ Anaconda เพื่อหลีกเลี่ยงการทำงานบนเครื่องโดยตรง ทำตามขั้นตอนด้านล่าง:
wget เพื่อดาวน์โหลดตัวติดตั้ง: wget https://repo.anaconda.com/archive/Anaconda3-version-OS.shchmod +x Anaconda3-version-OS.shbash Anaconda3-version-OS.shbashrc ของคุณ: export PATH= " /path_to_anaconda/anaconda3/bin: $PATH "สร้าง Python 3.9 Virtual Environment :
conda create -n yourenvname python=3.9yourenvname ด้วยชื่อสภาพแวดล้อมที่คุณต้องการเปิดใช้งานสภาพแวดล้อม :
source activate yourenvnameตอนนี้คุณพร้อมที่จะติดตั้งการพึ่งพาและทำงานภายในสภาพแวดล้อมเสมือนจริงของคุณ
ในโฟลเดอร์ Violent-Python-functions เรามีไฟล์ .in และ .out ที่มีคำอธิบาย NL (ภาษาธรรมชาติ) และฟังก์ชั่น Python ที่สอดคล้องกันตามลำดับ
ชุดข้อมูล Python ที่มีความรุนแรงเป็นชุดข้อมูลที่ดูแลด้วยตนเองซึ่งตัวอย่างมีรหัส Python ชิ้นหนึ่งจากซอฟต์แวร์ที่น่ารังเกียจและคำอธิบายที่สอดคล้องกันในภาษาธรรมชาติ (ภาษาอังกฤษธรรมดา) เราสร้างชุดข้อมูลโดยใช้หนังสือยอดนิยม "Violent Python" โดย TJ O'Connor ซึ่งนำเสนอตัวอย่างของโปรแกรมที่น่ารังเกียจหลายรายการโดยใช้ภาษา Python
เราได้รวมเฉพาะคำอธิบายระดับฟังก์ชั่นรวม 72 คู่ของคำอธิบาย NL - ฟังก์ชั่น Python
ติดตั้งการพึ่งพา :
pip install -r requirements.txt --userการสกัดส่วนย่อย :
create_subset.py ด้วยคำสั่งต่อไปนี้: python create_subset.pyscripts/results ที่มี reference.in และ reference.out ไฟล์reference.in มีคำอธิบาย NL ที่แยกแบบสุ่ม 10 แบบreference.out มีฟังก์ชั่น 10 Python ที่สอดคล้องกันและทำหน้าที่เป็นความจริงพื้นฐานของเราสำหรับการประเมินผลถัดไปคุณจะสร้างเอาต์พุต 10 เอาต์พุตโดยใช้รุ่น AI แบบกำเนิดเช่น CHATGPT หรือ Claude Sonnet
คำเตือน
ให้ความสนใจกับโครงสร้างของตัวอย่างรหัส อย่างที่คุณเห็นรหัส Python ล้วนเป็น บรรทัดเดียว ในความเป็นจริงคำแนะนำหลายบรรทัดจะถูกแยกออกจากกันด้วย n
สร้างผลลัพธ์ :
reference.in ไฟล์เพื่อสร้างเอาต์พุต 10 เอาต์พุตโดยใช้โมเดล AIoutput.out ในโฟลเดอร์ resultsตัวอย่างพรอมต์:
Generate Python 10 functions starting from the following 10 natural language (NL) descriptions:
1. [NL description]
2. [NL description]
...
10. [NL description]
Each function should be generated in a single line, for a total of 10 lines.
Different instructions of the same function should be separated by the special character "n".
Do not use empty lines to separate functions.
คำนวณตัวชี้วัดความคล้ายคลึงกันของเอาต์พุต :
scripts ให้เรียกใช้สคริปต์ Python output_similarity_metrics.py เพื่อคำนวณตัวชี้วัดความคล้ายคลึงกันของเอาต์พุตระหว่างการทำนายแบบจำลอง ( output.out ) และการอ้างอิงความจริงภาคพื้นดิน ( reference.out ): python output_similarity_metrics.py hypothesis_filehypothesis_file คือไฟล์ results/output.out ตัวชี้วัดจะถูกสร้างขึ้นในไฟล์ results/output_metrics.txt
scripts ให้ดำเนินการสคริปต์ boxplot_metrics.py เพื่อแสดงภาพความแปรปรวนของตัวชี้วัดที่บันทึกไว้ใน results/output_metrics.txt : python boxplot_metrics.pyด้านล่างเป็นภาพที่แสดงความแปรปรวนของตัวชี้วัดความคล้ายคลึงกันของเอาต์พุตด้วย boxplot:
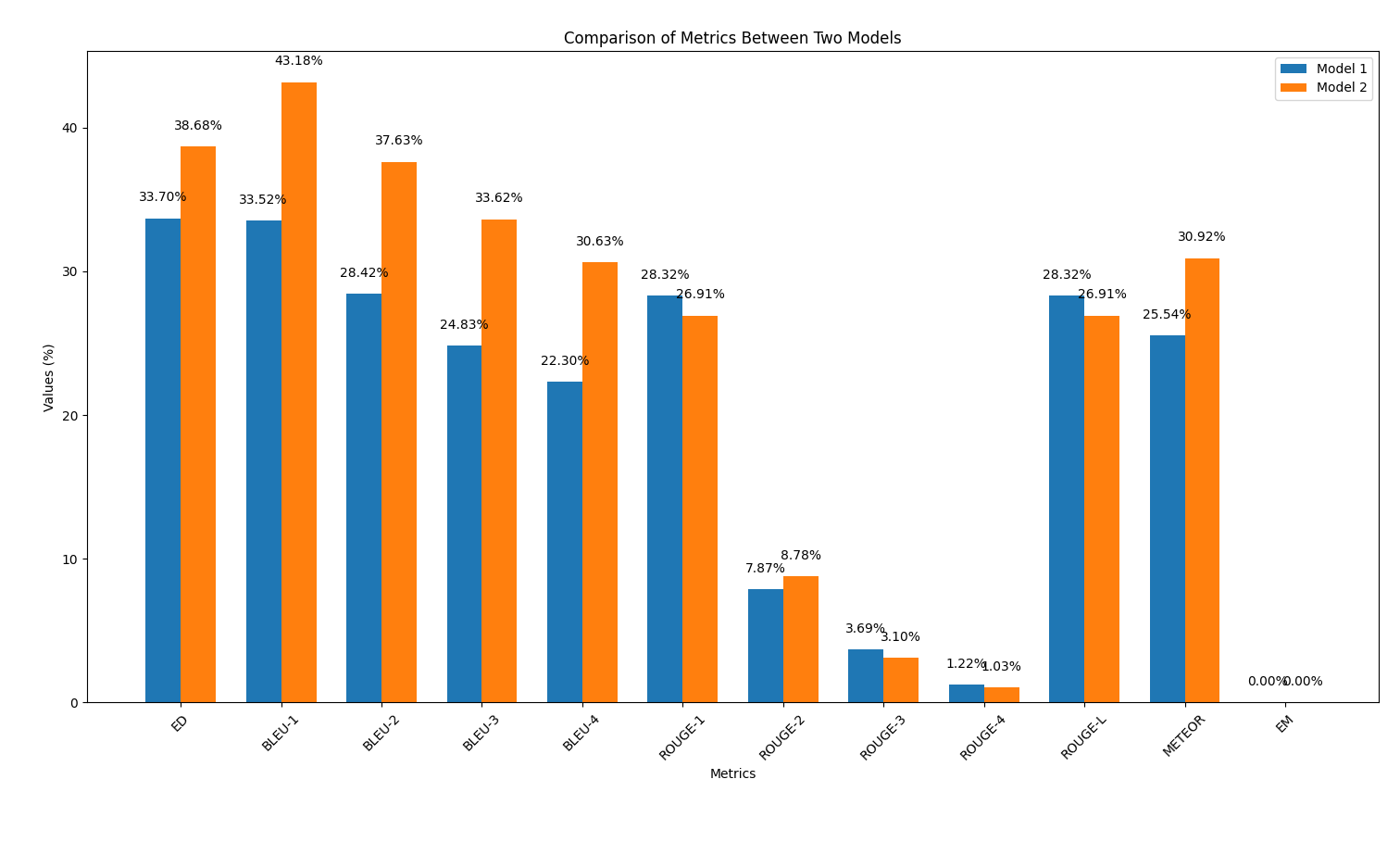
results/output2.outoutput_similarity_metrics.py เพื่อคำนวณตัวชี้วัดความคล้ายคลึงกันของเอาต์พุตระหว่างการทำนายแบบจำลอง ( output2.out ) และการอ้างอิงความจริงภาคพื้นดิน ( reference.out ): python output_similarity_metrics.py results/output2.outcompare_models.py เพื่อแสดงการเปรียบเทียบประสิทธิภาพสองรุ่นในสองตัวชี้วัด python compare_models.pyด้านล่างเป็นตัวอย่างของผลลัพธ์:
ในส่วนนี้เราจะทำซ้ำกระบวนการสร้างรหัสโดยใช้โมเดล AI แต่คราวนี้ใช้เทคนิควิศวกรรมที่รวดเร็วที่กล่าวถึงในระหว่างการพูดคุย เป้าหมายคือการสังเกตว่าเทคนิคนี้ปรับปรุงคุณภาพของรหัสที่สร้างขึ้นหรือไม่
ใช้วิศวกรรมที่รวดเร็ว :
reference.in ไฟล์ ตัวอย่างของพรอมต์สามารถพบได้ในโฟลเดอร์ scripts/prompt_examples
สร้างผลลัพธ์ :
output_prompt_pattern.out ในโฟลเดอร์ scripts/results โดยที่ prompt_pattern เป็นตัวระบุที่คุณต้องการใช้เพื่อระบุรูปแบบที่นำมาใช้ (เช่น output_persona.out , output_few_shot.out )คำนวณตัวชี้วัดความคล้ายคลึงกันของเอาต์พุต :
scripts ให้เรียกใช้สคริปต์เพื่อคำนวณตัวชี้วัดความคล้ายคลึงกันของเอาต์พุตระหว่างการทำนายแบบจำลอง ( output_prompt_pattern.out ) และการอ้างอิงความจริงภาคพื้นดิน ( reference.out ): python output_similarity_metrics.py hypothesis_file โดยที่ hypothesis_file เป็นไฟล์ที่สร้างขึ้นด้วยรูปแบบพรอมต์ (เช่นไฟล์ results/output_few_shot.out )
scripts/results/output_prompt_engineering_metrics.txt (เช่น scripts/results/output_few_shot_metrics.txt )เปรียบเทียบผลลัพธ์ :
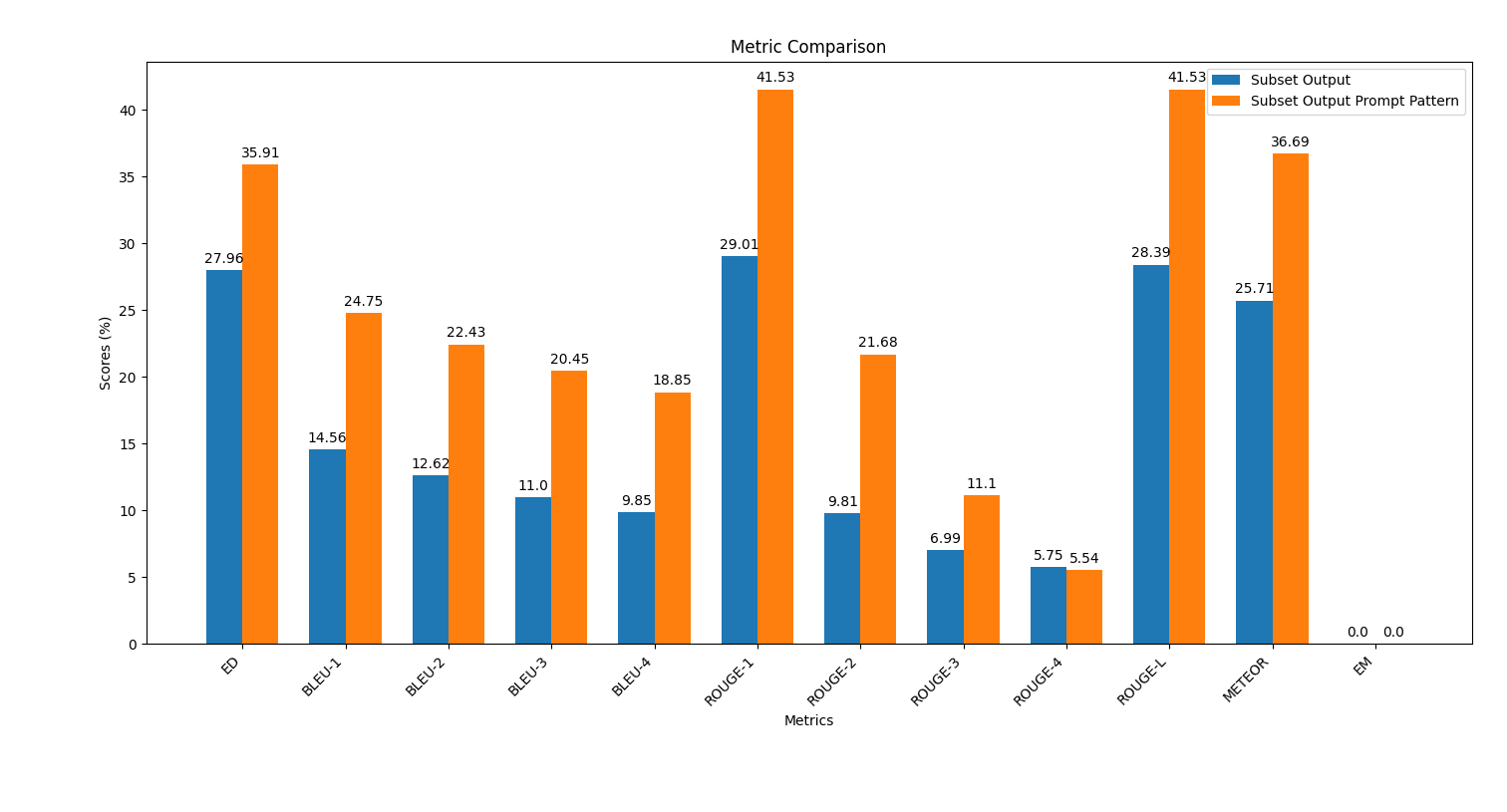
scripts ให้ดำเนินการสคริปต์ plot_metrics_comparison.py เพื่อเปรียบเทียบผลลัพธ์: python plot_metrics_comparison.py file_metricsfile_metrics เป็น scripts/results/output_prompt_engineering_metrics.txt ไฟล์ด้านล่างเป็นภาพที่แสดงการเปรียบเทียบตัวชี้วัดระหว่างเอาต์พุตที่เกิดขึ้นโดยไม่มีวิศวกรรมที่รวดเร็วและมีวิศวกรรมพรอมต์ไม่กี่นัด:
ทำตามขั้นตอนเหล่านี้เพื่อใช้วิศวกรรมที่รวดเร็วและประเมินผลกระทบต่อคุณภาพการสร้างรหัส
ในโฟลเดอร์ saved_outputs คุณจะพบตัวอย่างที่สร้างขึ้นด้วย chatgpt-4o ตัวอย่างเหล่านี้แสดงให้เห็นว่าเอาต์พุตของโมเดลมีลักษณะอย่างไรกับเทคนิคการวิศวกรรมที่รวดเร็วที่ใช้
พื้นที่เก็บข้อมูลนี้และวัสดุได้รับการพัฒนาโดย:


