generative ai cybersecurity
1.0.0
이 저장소에는 Dessert Group의 Naples Federico II 대학교 Pietro Liguori의 "Cybersecurity in Cybersecurity : Overvensive Code 생성"이라는 제목의 토크 제목 의 자료 및 스크립트가 포함되어 있습니다. 이 대화는 안전한 응용 분야에서 인공 지능의 역할과 영향에 관한 Artisan 2024 : Summer School 의 일부입니다.
시스템에 Python이 설치되어 있는지 확인하십시오. 그렇지 않은 경우 Anaconda와 함께 가상 환경을 사용하여 컴퓨터에서 직접 작동하지 않을 수 있습니다. 아래 단계를 따르십시오.
wget 명령을 사용하여 설치 프로그램을 다운로드하십시오. wget https://repo.anaconda.com/archive/Anaconda3-version-OS.shchmod +x Anaconda3-version-OS.shbash Anaconda3-version-OS.shbashrc 파일에 추가하십시오. export PATH= " /path_to_anaconda/anaconda3/bin: $PATH "Python 3.9 가상 환경 생성 :
conda create -n yourenvname python=3.9yourenvname 원하는 환경 이름으로 바꾸십시오.환경 활성화 :
source activate yourenvname이제 가상 환경 내에서 종속성을 설치하고 작업 할 준비가되었습니다.
Violent-Python-functions 폴더에는 NL (자연어) 설명과 해당 Python 함수가 포함 된 .in 및 .out 파일이 있습니다.
폭력적인 파이썬 데이터 세트는 수동으로 선별 된 데이터 세트로, 샘플에는 공격적인 소프트웨어의 파이썬 코드가 포함되어 있으며 해당 설명 자연어 (일반 영어). 우리는 TJ O'Connor의 인기있는 책 "Violent Python"을 사용하여 데이터 세트를 만들었습니다.이 책은 Python Language를 사용하여 공격 프로그램의 몇 가지 예를 제시합니다.
우리는 함수 수준 설명 만, 총 72 쌍의 NL 설명 - 파이썬 함수를 포함했습니다.
종속성 설치 :
pip install -r requirements.txt --user서브 세트 추출 :
create_subset.py 스크립트를 실행하십시오. python create_subset.pyreference.in 및 reference.out 파일을 포함하는 scripts/results 하위 폴더를 만듭니다.reference.in 파일에는 무작위로 추출 된 10 개의 NL 설명이 포함되어 있습니다.reference.out 파일에는 해당 10 개의 파이썬 기능이 포함되어 있으며 평가를위한 근거 진실 역할을합니다.다음으로 ChatGpt 또는 Claude Sonnet과 같은 생성 AI 모델을 사용하여 10 개의 출력을 생성합니다.
주의
코드 스 니펫의 구조에주의하십시오. 보시다시피, 파이썬 코드는 모두 단일 라인 입니다. 실제로, 멀티 라인 지침은 n 으로 서로 분리됩니다.
출력 생성 :
reference.in 파일에 저장된 NL 설명을 사용하여 AI 모델을 사용하여 10 개의 출력을 생성하십시오.results 폴더에서 output.out 라는 파일에 모델 출력을 저장하십시오.예제 프롬프트 :
Generate Python 10 functions starting from the following 10 natural language (NL) descriptions:
1. [NL description]
2. [NL description]
...
10. [NL description]
Each function should be generated in a single line, for a total of 10 lines.
Different instructions of the same function should be separated by the special character "n".
Do not use empty lines to separate functions.
출력 유사성 메트릭 계산 :
scripts 폴더에서 Python Script output_similarity_metrics.py 실행하여 모델 예측 ( output.out )과 Ground Truth 참조 ( reference.out ) 간의 출력 유사성 메트릭을 계산합니다. python output_similarity_metrics.py hypothesis_filehypothesis_file 은 results/output.out 파일입니다. 메트릭은 results/output_metrics.txt 파일에서 생성됩니다.
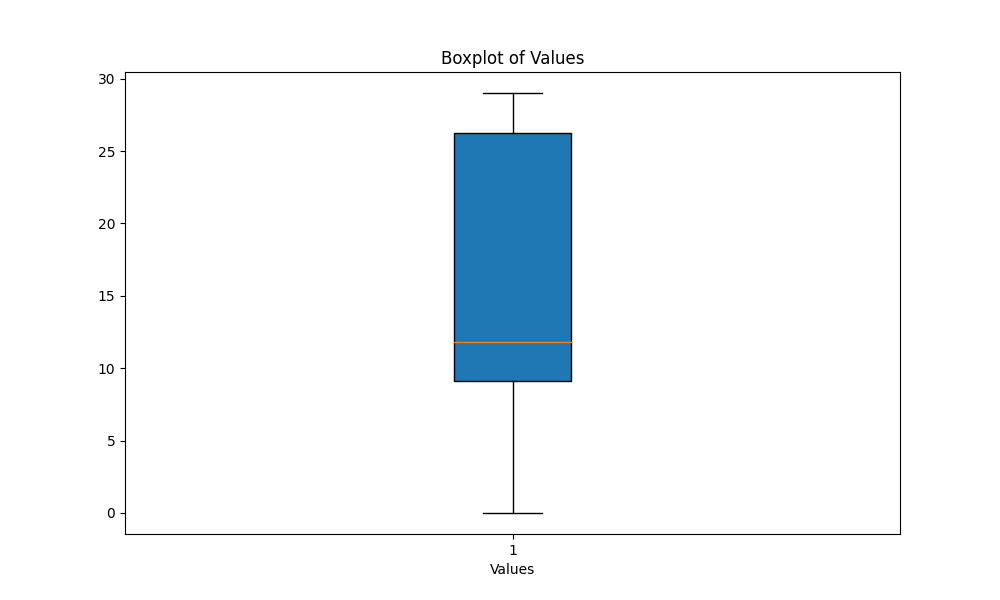
scripts 폴더에서 스크립트 boxplot_metrics.py 실행하여 파일 results/output_metrics.txt 에 저장된 메트릭의 변동성을 시각화합니다. python boxplot_metrics.py아래는 박스 플롯을 사용한 출력 유사성 메트릭의 가변성을 보여주는 이미지입니다.
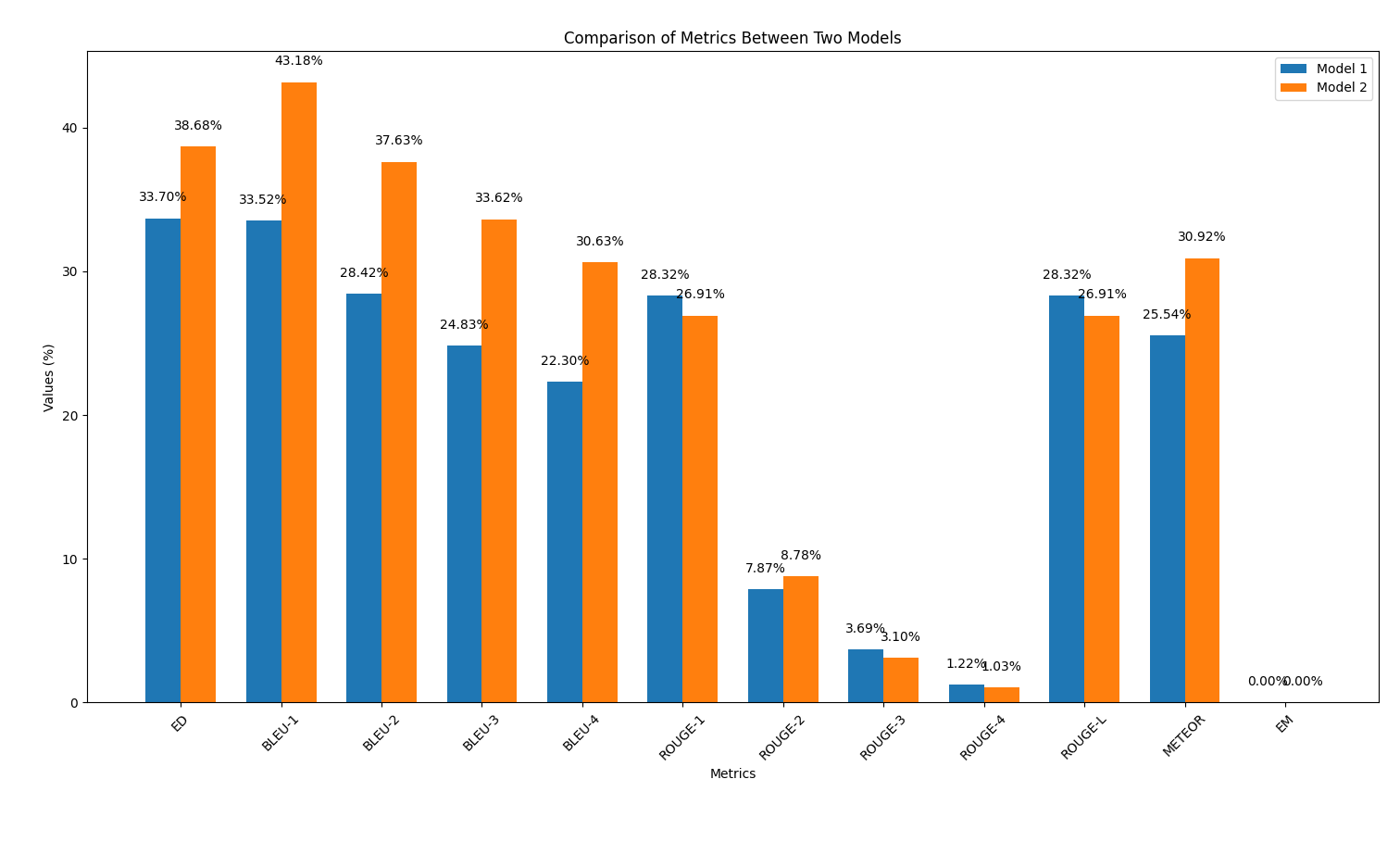
results/output2.out 파일에 모델의 예측을 저장하십시오.output_similarity_metrics.py 다시 실행하여 모델 예측 ( output2.out )과 Ground Truth Reference ( reference.out ) 간의 출력 유사성 메트릭을 계산합니다. python output_similarity_metrics.py results/output2.outcompare_models.py 실행하여 두 가지 메트릭에서 두 가지 모델 성능의 비교를 보여줍니다. python compare_models.py아래는 출력의 예입니다.
이 부분에서는 AI 모델을 사용하여 코드 생성 프로세스를 반복하지만 이번에는 대화 중에 논의 된 신속한 엔지니어링 기술을 적용합니다. 목표는이 기술이 생성 된 코드의 품질을 향상시키는 지 관찰하는 것입니다.
신속한 엔지니어링 적용 :
reference.in 파일에 저장된 동일한 NL 설명을 사용하십시오. 프롬프트의 예는 scripts/prompt_examples 폴더에서 찾을 수 있습니다.
출력 생성 :
scripts/results 폴더에서 output_prompt_pattern.out 라는 파일에 모델 출력을 저장합니다. 여기서 prompt_pattern 채택 된 패턴을 지정하는 데 사용하려는 식별자입니다 (예 : output_persona.out , output_few_shot.out ).출력 유사성 메트릭 계산 :
scripts 폴더에서 스크립트를 실행하여 모델 예측 ( output_prompt_pattern.out )과 지상 진실 참조 ( reference.out ) 간의 출력 유사성 메트릭을 계산합니다. python output_similarity_metrics.py hypothesis_file 여기서 hypothesis_file 프롬프트 패턴으로 생성 된 파일입니다 (예 : results/output_few_shot.out 파일).
scripts/results/output_prompt_engineering_metrics.txt 파일 (예 : scripts/results/output_few_shot_metrics.txt 파일)에서 생성됩니다.결과 비교 :
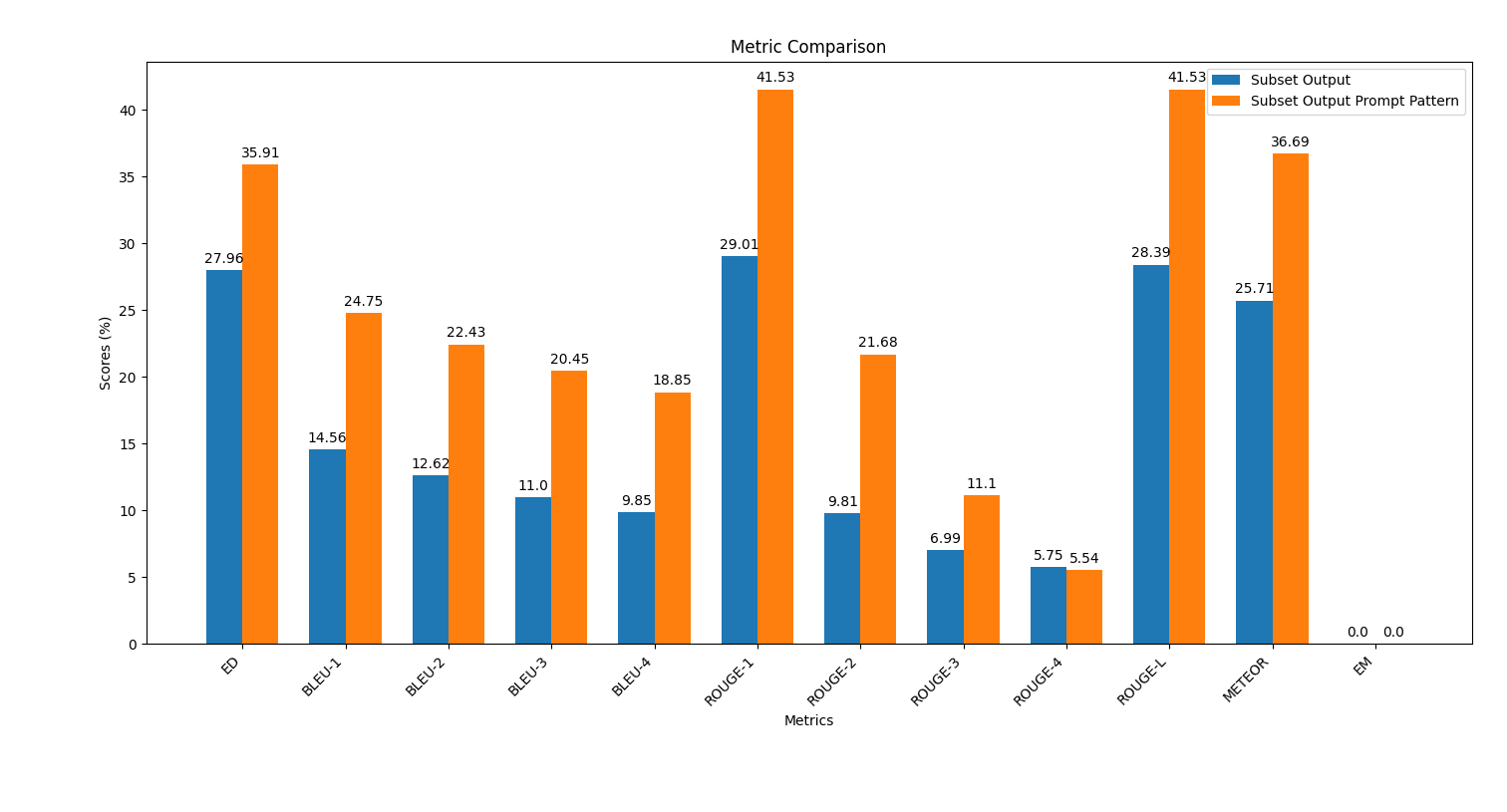
scripts 폴더에서 스크립트 plot_metrics_comparison.py 실행하여 결과를 비교하기 위해 다음과 같습니다. python plot_metrics_comparison.py file_metricsfile_metrics 는 scripts/results/output_prompt_engineering_metrics.txt 파일입니다.아래는 신속한 엔지니어링없이 생성 된 출력과 신속한 엔지니어링이 거의없는 메트릭의 비교를 보여주는 이미지입니다.
다음 단계를 따라 신속한 엔지니어링을 적용하고 코드 생성 품질에 미치는 영향을 평가하십시오.
saved_outputs 폴더에는 chatgpt-4o와 함께 생성 된 예를 찾을 수 있습니다. 이 예제는 다른 프롬프트 엔지니어링 기술이 적용된 모델의 출력이 어떻게 보이는지 보여줍니다.
이 저장소와 재료는 다음과 같이 개발되었습니다.


