generative ai cybersecurity
1.0.0
このリポジトリには、「サイバーセキュリティにおける生成AI:自然言語からの攻撃コードの生成」というタイトルの講演の資料とスクリプトが含まれています。この講演は、安全なアプリケーションにおける人工知能の役割と効果に関する職人2024:サマースクールの一部です。
システムにPythonをインストールしていることを確認してください。そうでない場合は、アナコンダを使用して仮想環境を使用して、マシンで直接作業することを避けることができます。以下の手順に従ってください。
wgetコマンドを使用して、インストーラーをダウンロードします。 wget https://repo.anaconda.com/archive/Anaconda3-version-OS.shchmod +x Anaconda3-version-OS.shbash Anaconda3-version-OS.shbashrcファイルに追加します。 export PATH= " /path_to_anaconda/anaconda3/bin: $PATH "Python 3.9仮想環境を作成します。
conda create -n yourenvname python=3.9yourenvname希望の環境名に置き換えます。環境を有効にします:
source activate yourenvnameこれで、仮想環境内で依存関係をインストールし、作業する準備ができました。
Violent-Python-functionsフォルダーには、それぞれNL(自然言語)の説明と対応するPython関数を含む.inおよび.outファイルがあります。
暴力的なPythonデータセットは、手動でキュレーションされたデータセットであり、サンプルには攻撃ソフトウェアからのPythonコードが含まれており、それに対応する自然言語(プレーン英語)が含まれています。 TJ O'Connorによる人気のある本「Violent Python」を使用してデータセットを作成しました。これは、Python言語を使用して攻撃プログラムのいくつかの例を紹介します。
合計72ペアのNL説明-Python関数を含む関数レベルの説明のみを含めました。
依存関係をインストールします:
pip install -r requirements.txt --userサブセット抽出:
create_subset.pyスクリプトを実行します。 python create_subset.pyreference.inおよびreference.outファイルを含むscripts/resultsサブフォルダーを作成します。reference.inファイルには、10のランダムに抽出されたNL説明が含まれています。reference.outファイルには、対応する10個のPython関数が含まれており、評価のための基本真理として機能します。次に、ChATGPTやClaude Sonnetなどの生成AIモデルを使用して10の出力を生成します。
注意
コードスニペットの構造に注意してください。ご覧のとおり、Pythonコードはすべてシングルラインです。実際、マルチラインの命令はnで互いに分離されています。
出力の生成:
reference.inファイルに保存されているNL説明を使用して、AIモデルを使用して10の出力を生成します。output.outという名前のファイルに保存します。 resultsフォルダー。プロンプトの例:
Generate Python 10 functions starting from the following 10 natural language (NL) descriptions:
1. [NL description]
2. [NL description]
...
10. [NL description]
Each function should be generated in a single line, for a total of 10 lines.
Different instructions of the same function should be separated by the special character "n".
Do not use empty lines to separate functions.
出力の類似性メトリックを計算します。
scriptsフォルダーで、Pythonスクリプトoutput_similarity_metrics.pyを実行して、モデル予測( output.out )とグラウンドトゥルースリファレンス( reference.out )の間の出力類似性メトリックを計算します。 python output_similarity_metrics.py hypothesis_filehypothesis_file results/output.outファイルです。メトリックは、 results/output_metrics.txtファイルで生成されます。
scriptsフォルダーで、スクリプトboxplot_metrics.pyを実行して、ファイルのresults/output_metrics.txtに保存されたメトリックの変動性を視覚化します: python boxplot_metrics.py以下は、ボックスプロットを使用した出力類似性メトリックの変動性を示す画像です。
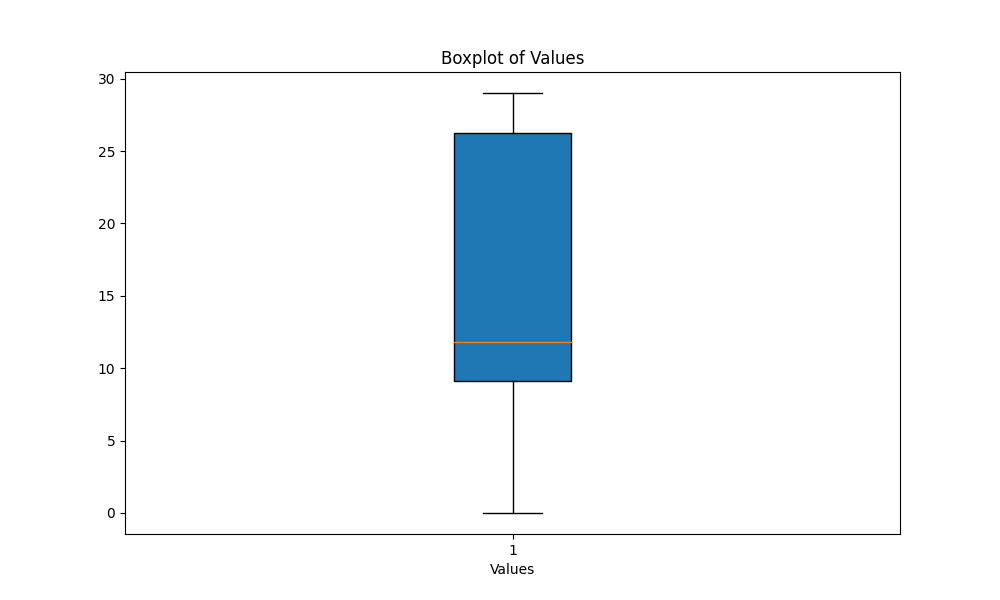
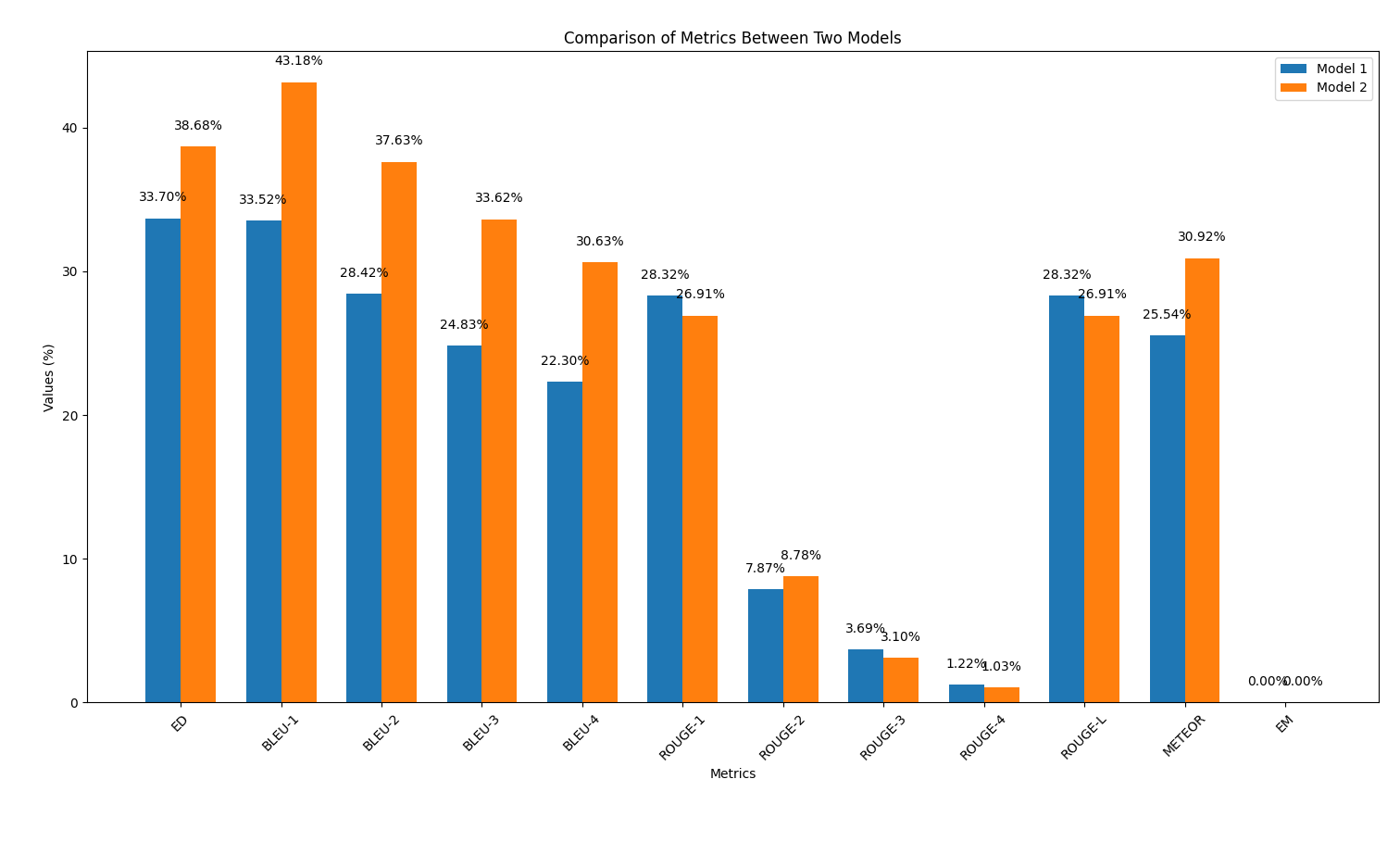
results/output2.outファイルにモデルの予測を保存してください。output_similarity_metrics.py再度実行して、モデル予測( output2.out )とグラウンドトゥルースリファレンス( reference.out )の間の出力類似性メトリックを計算します。 python output_similarity_metrics.py results/output2.outcompare_models.py 2つのメトリックにわたって2つのモデルパフォーマンスの比較を表示するには python compare_models.py以下は出力の例です。
この部分では、AIモデルを使用してコード生成プロセスを繰り返しますが、今回は講演中に議論された迅速なエンジニアリング手法を適用します。目標は、この手法が生成されたコードの品質を改善するかどうかを観察することです。
迅速なエンジニアリングを適用します:
reference.inファイルに保存されているのと同じNL説明を使用します。プロンプトの例はscripts/prompt_examplesフォルダーにあります。
出力の生成:
output_prompt_pattern.outという名前のファイルにscripts/resultsフォルダーになります。ここでは、 prompt_patternは採用されたパターン( output_persona.out 、 output_few_shot.out )を指定するために使用する識別子です。出力の類似性メトリックを計算します。
scriptsフォルダーで、スクリプトを実行して、モデル予測( output_prompt_pattern.out )とグラウンドトゥルースリファレンス( reference.out )の間の出力類似性メトリックを計算します。 python output_similarity_metrics.py hypothesis_fileここで、 hypothesis_fileプロンプトパターンで生成されたファイルです(例: results/output_few_shot.outファイル)。
scripts/results/output_prompt_engineering_metrics.txtファイル(たとえば、 scripts/results/output_few_shot_metrics.txtファイル)で生成されます。結果を比較してください:
scriptsフォルダーで、スクリプトplot_metrics_comparison.pyを実行して結果を比較します。 python plot_metrics_comparison.py file_metricsfile_metricsはscripts/results/output_prompt_engineering_metrics.txtファイルです。以下は、迅速なエンジニアリングなしで生成された出力間および少数の迅速なエンジニアリングとの間のメトリックの比較を示す画像です。
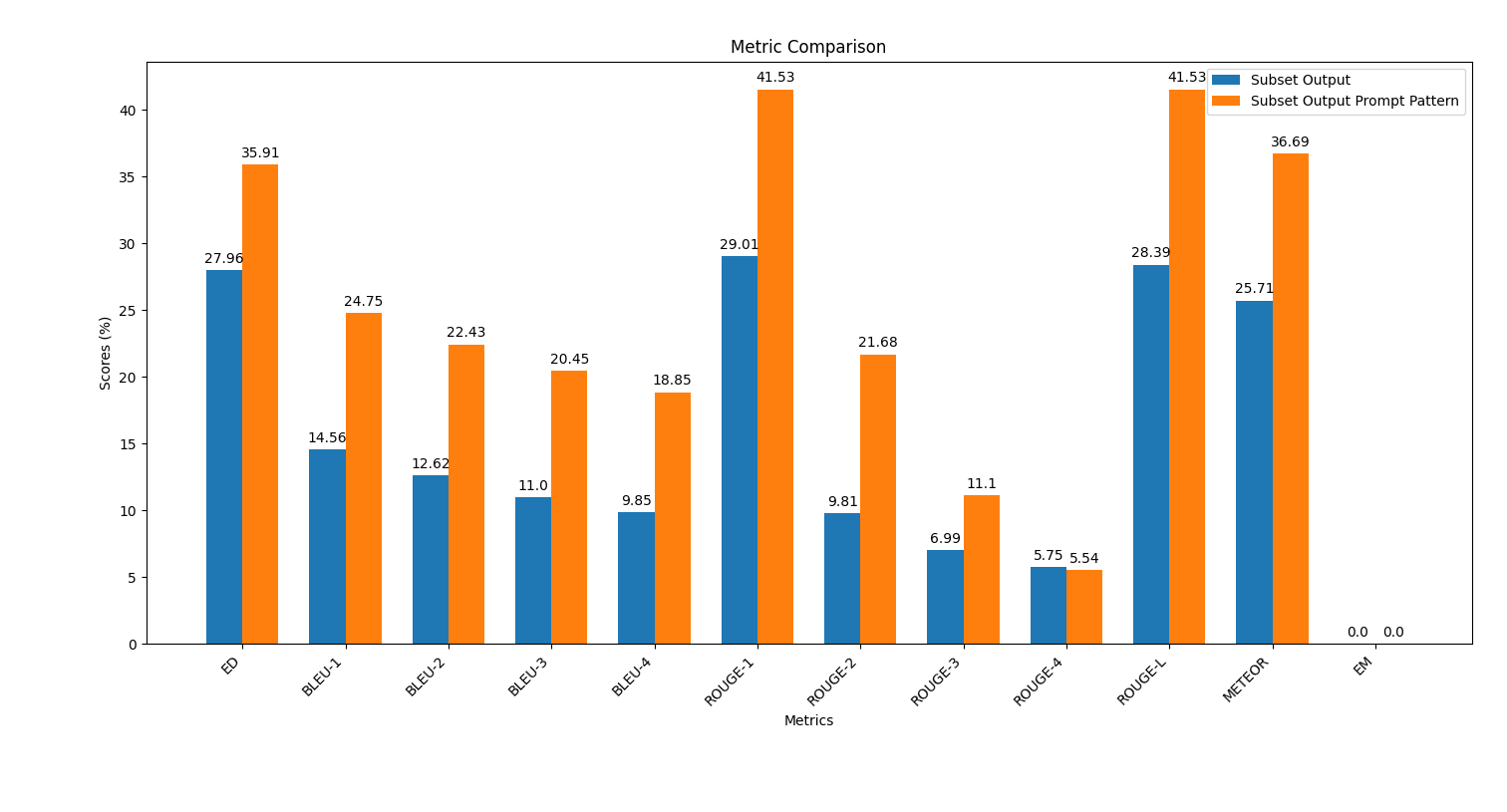
次の手順に従って、迅速なエンジニアリングを適用し、コード生成品質への影響を評価します。
saved_outputsフォルダーには、chatgpt-4oで生成された例があります。これらの例は、さまざまな迅速なエンジニアリング技術が適用された場合のモデルの出力がどのように見えるかを示しています。
このリポジトリと材料は以下によって開発されました。


