RAG based Intelligent Conversational AI Agent for Knowledge Extraction Using LangChain Gemini LLM
1.0.0
La generación de recuperación aumentada (RAG) es un marco que combina la recuperación de información con IA generativa. Permite que los modelos recuperen información relevante de fuentes o bases de datos externas y usen esos datos para generar respuestas más precisas y contextualmente relevantes. Al aprovechar tanto la recuperación como la generación, RAG mejora la precisión y confiabilidad de los modelos de IA, particularmente en proporcionar información actualizada o manejar preguntas complejas.
Este proyecto proporciona un asistente de conversación basado en IA que aprovecha la generación de recuperación acuática (RAG) para extraer conocimiento de los documentos PDF. El sistema combina insertos de texto, búsqueda vectorial y un LLM para proporcionar respuestas a las preguntas del usuario. A continuación se muestra un flujo de trabajo detallado paso a paso de cómo funciona la aplicación:
pdfplumber , una biblioteca de Python para extraer texto de PDFS.pdfplumber para extraer texto sin procesar del PDF cargado. Cada página del documento se analiza y el texto resultante se prepara para su posterior procesamiento.RecursiveCharacterTextSplitter . Esto asegura que el contenido sea manejable para incrustaciones y recuperación, generalmente con un tamaño de fragmento de 500 caracteres y una superposición de 50 caracteres.SpacyEmbeddings . Estas incrustaciones representan el significado semántico de los trozos, lo que permite una búsqueda eficiente. 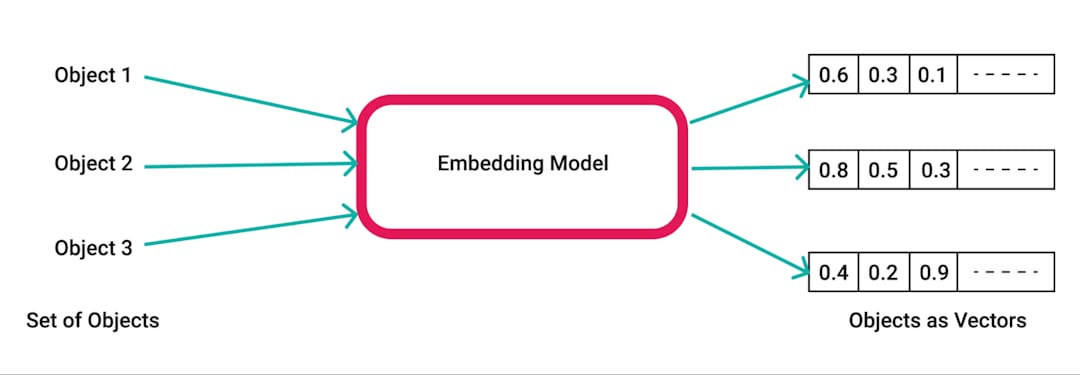
Chroma , donde se almacenan los incrustaciones. La base de datos de Vector permite una recuperación rápida y eficiente de la información relevante basada en consultas de usuarios.ConversationalRetrievalChain se establece utilizando LangChain , combinando los incrustaciones almacenados en Chroma con un búfer de memoria conversacional para rastrear el historial y el contexto del chat.ChatGoogleGenerativeAI (Gemini LLM de Google) para generar respuestas relevantes e inteligentes a las preguntas del usuario basadas en los fragmentos de texto recuperados de la tienda Vector.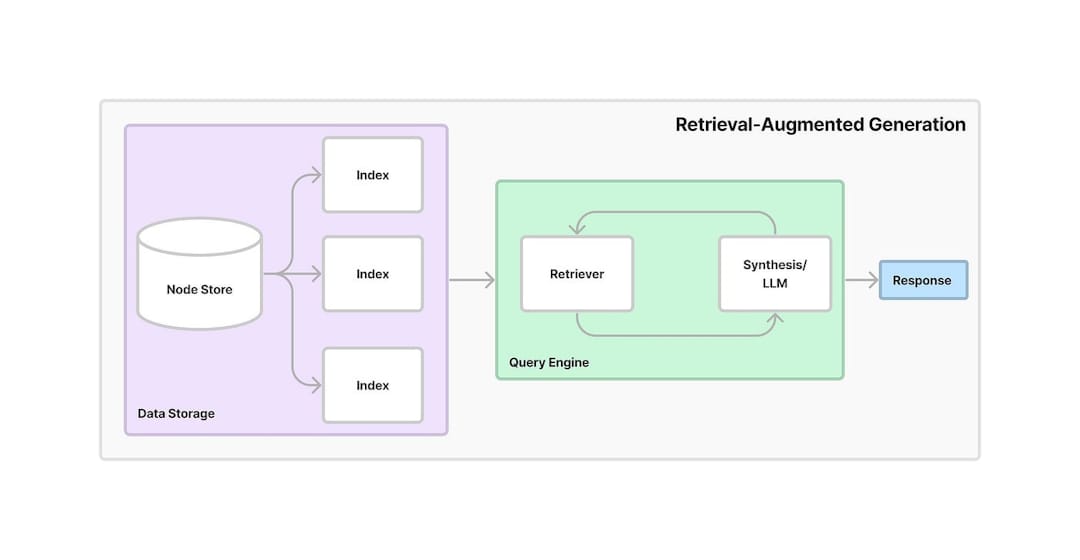
Recuperación de conocimiento eficiente : al aprovechar el poder del RAG, el sistema combina recuperación y generación para responder preguntas específicas con precisión en función del contenido de los documentos PDF cargados.
Escalabilidad y flexibilidad : con la fragmentación de texto e incrustaciones, la aplicación puede manejar documentos grandes al tiempo que garantiza la recuperación de información rápida y precisa.
AI conversacional : la memoria del historial de conversación hace que el sistema sea más interactivo, ya que realiza un seguimiento de las preguntas y respuestas anteriores, manteniendo el contexto durante largas conversaciones.
Integración de herramientas de IA modernas : este proyecto demuestra el uso de herramientas avanzadas como Chroma para el almacenamiento vectorial, LangChain para la gestión de la conversación y Gemini LLM de Google para generar respuestas humanas.


