RAG based Intelligent Conversational AI Agent for Knowledge Extraction Using LangChain Gemini LLM
1.0.0
Поигрывательный поколение (RAG)-это структура, которая сочетает в себе поиск информации с генеративным ИИ. Это позволяет моделям извлекать соответствующую информацию из внешних источников или баз данных и использовать эти данные для генерации более точных и контекстуально соответствующих ответов. Используя как поиск, так и поколение, RAG повышает точность и надежность моделей искусственного интеллекта, особенно в предоставлении актуальной информации или обработке сложных вопросов.
Этот проект предоставляет ассистенту по разговору на основе ИИ, который использует поколение поиска-августа (RAG) для извлечения знаний из PDF-документов. Система объединяет текстовые вставки, векторный поиск и LLM для предоставления ответов на вопросы пользователя. Ниже приведен подробный пошаговый рабочий процесс того, как работает приложение:
pdfplumber , библиотеки Python для извлечения текста из PDFS.pdfplumber для извлечения необработанного текста из загруженного PDF. Каждая страница документа анализируется, и полученный текст подготовлен для дальнейшей обработки.RecursiveCharacterTextSplitter . Это гарантирует, что контент будет управляемым для внедрений и поиска, как правило, с размером куски 500 символов и перекрытием 50 символов.SpacyEmbeddings . Эти встраивания представляют собой семантическое значение кусков, что обеспечивает эффективный поиск. 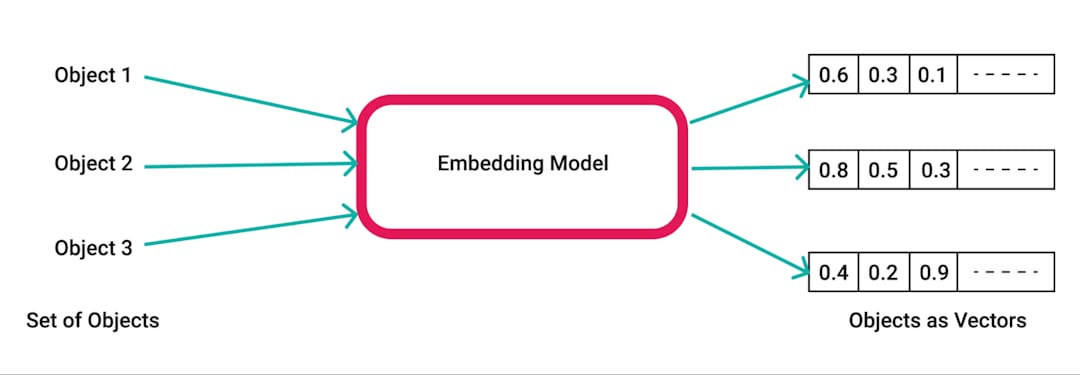
Chroma , где хранятся вставки. Векторная база данных позволяет быстро и эффективно извлекать соответствующую информацию на основе запросов пользователей.ConversationalRetrievalChain создается с использованием LangChain , объединяя встраивания, хранящиеся в Chroma, с разговорным буфером памяти для отслеживания истории и контекста ЧАТА.ChatGoogleGenerativeAI (Google Gemini LLM), чтобы генерировать соответствующие и интеллектуальные ответы на вопросы пользователя на основе полученных кусков текста из векторного магазина.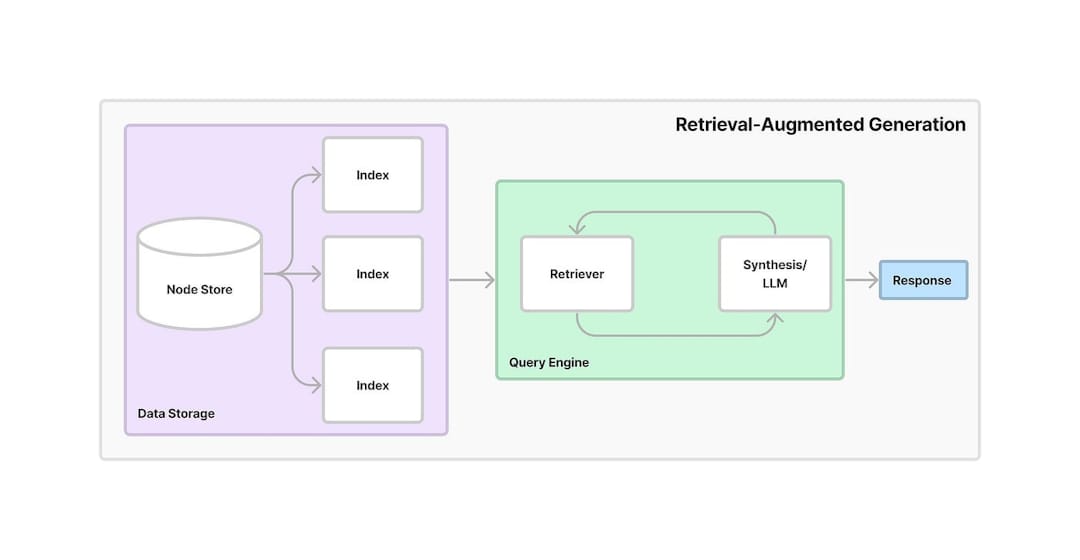
Эффективный поиск знаний : используя силу RAG, система объединяет поиск и поколение, чтобы точно ответить на конкретные вопросы на основе содержания загруженных документов PDF.
Масштабируемость и гибкость : с помощью текстового кунгинга и внедрения приложение может обрабатывать большие документы, обеспечивая быстрый и точный поиск информации.
Разговорная ИИ : Память истории разговора делает систему более интерактивной, поскольку она отслеживает предыдущие вопросы и ответы, поддержание контекста в течение долгих разговоров.
Интеграция современных инструментов искусственного интеллекта : этот проект демонстрирует использование современных инструментов, таких как Chroma для векторного хранилища, LangChain для управления разговорами и Gemini LLM Google для получения человеческих ответов.


