RAG based Intelligent Conversational AI Agent for Knowledge Extraction Using LangChain Gemini LLM
1.0.0
La génération (RAG) (RAG) de la récupération est un cadre qui combine la recherche d'informations avec une IA générative. Il permet aux modèles de récupérer des informations pertinentes à partir de sources ou de bases de données externes et d'utiliser ces données pour générer des réponses plus précises et contextuellement pertinentes. En tirant parti de la récupération et de la génération, RAG améliore la précision et la fiabilité des modèles d'IA, en particulier en fournissant des informations à jour ou en manipulant des questions complexes.
Ce projet fournit un assistant conversationnel basé sur l'IA qui exploite la génération (RAG) de la récupération (RAG) pour extraire les connaissances des documents PDF. Le système combine des incorporations de texte, une recherche de vecteur et un LLM pour fournir des réponses aux questions des utilisateurs. Vous trouverez ci-dessous un flux de travail détaillé étape par étape du fonctionnement de l'application:
pdfplumber , une bibliothèque Python pour extraire du texte de PDFS.pdfplumber pour extraire du texte brut du PDF téléchargé. Chaque page du document est analysée et le texte résultant est préparé pour un traitement ultérieur.RecursiveCharacterTextSplitter . Cela garantit que le contenu est gérable pour les intégres et la récupération, généralement avec une taille de 500 caractères et un chevauchement de 50 caractères.SpacyEmbeddings . Ces intégres représentent la signification sémantique des morceaux, permettant une recherche efficace. 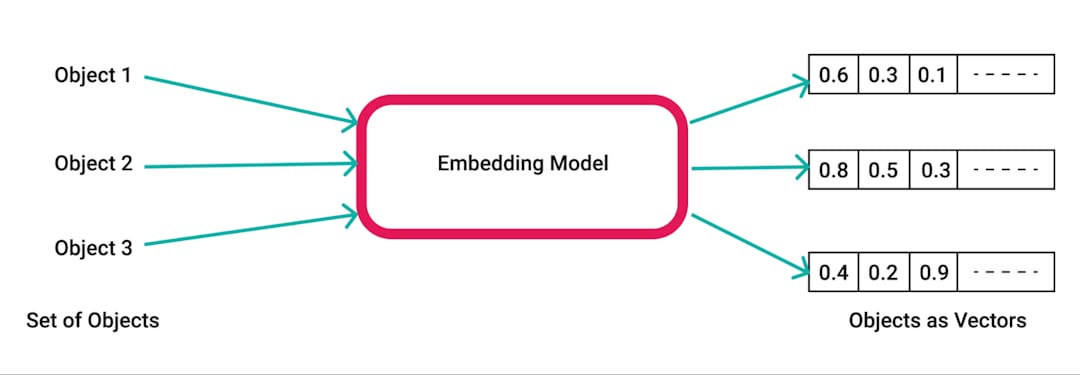
Chroma , où les intérêts sont stockés. La base de données vectorielle permet une récupération rapide et efficace des informations pertinentes en fonction des requêtes utilisateur.ConversationalRetrievalChain est établie à l'aide LangChain , combinant les intégres stockés dans le chroma avec un tampon de mémoire conversationnel pour suivre l'historique et le contexte du chat.ChatGoogleGenerativeAI (Google's Gemini LLM) pour générer des réponses pertinentes et intelligentes aux questions de l'utilisateur en fonction des morceaux de texte récupérés du magasin vectoriel.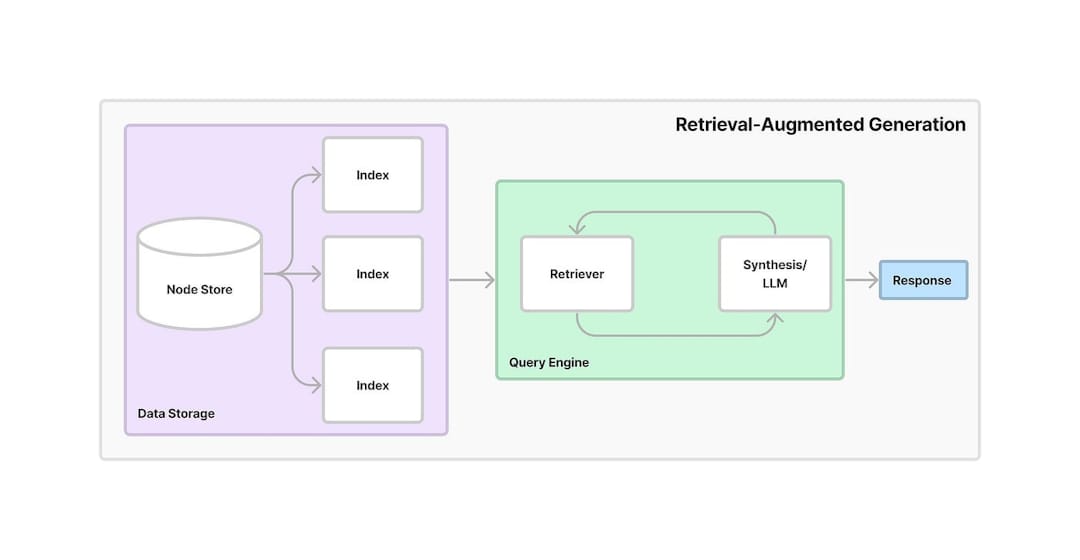
Récupération efficace des connaissances : en tirant parti de la puissance du chiffon, le système combine la récupération et la génération pour répondre à des questions spécifiques avec précision en fonction du contenu des documents PDF téléchargés.
Évolutivité et flexibilité : avec la chasse au texte et les intégres, l'application peut gérer de grands documents tout en garantissant une récupération rapide et précise des informations.
AI conversationnel : la mémoire de l'historique de conversation rend le système plus interactif, car il maintient une trace des questions et réponses précédentes, en maintenant le contexte sur de longues conversations.
Intégration des outils d'IA modernes : ce projet démontre l'utilisation d'outils avancés comme Chroma pour le stockage vectoriel, LangChain pour la gestion de la conversation et Gemini LLM de Google pour générer des réponses humaines.


