RAG based Intelligent Conversational AI Agent for Knowledge Extraction Using LangChain Gemini LLM
1.0.0
Retrieval-Agusted Generation (RAG) adalah kerangka kerja yang menggabungkan pengambilan informasi dengan AI generatif. Ini memungkinkan model untuk mengambil informasi yang relevan dari sumber atau basis data eksternal dan menggunakan data itu untuk menghasilkan respons yang lebih akurat dan relevan secara kontekstual. Dengan memanfaatkan pengambilan dan generasi, RAG meningkatkan akurasi dan keandalan model AI, terutama dalam memberikan informasi terkini atau menangani pertanyaan kompleks.
Proyek ini menyediakan asisten percakapan berbasis AI yang memanfaatkan generasi Pengambilan-Pengambilan (RAG) untuk mengekstraksi pengetahuan dari dokumen PDF. Sistem ini menggabungkan embeddings teks, pencarian vektor, dan LLM untuk memberikan jawaban atas pertanyaan pengguna. Di bawah ini adalah alur kerja langkah demi langkah terperinci tentang bagaimana aplikasi beroperasi:
pdfplumber , pustaka Python untuk mengekstraksi teks dari PDFS.pdfplumber untuk mengekstrak teks mentah dari PDF yang diunggah. Setiap halaman dokumen diuraikan, dan teks yang dihasilkan disiapkan untuk pemrosesan lebih lanjut.RecursiveCharacterTextSplitter . Ini memastikan konten dapat dikelola untuk embeddings dan pengambilan, biasanya dengan ukuran chunk 500 karakter dan tumpang tindih 50 karakter.SpacyEmbeddings . Embeddings ini mewakili makna semantik dari potongan -potongan, memungkinkan pencarian yang efisien. 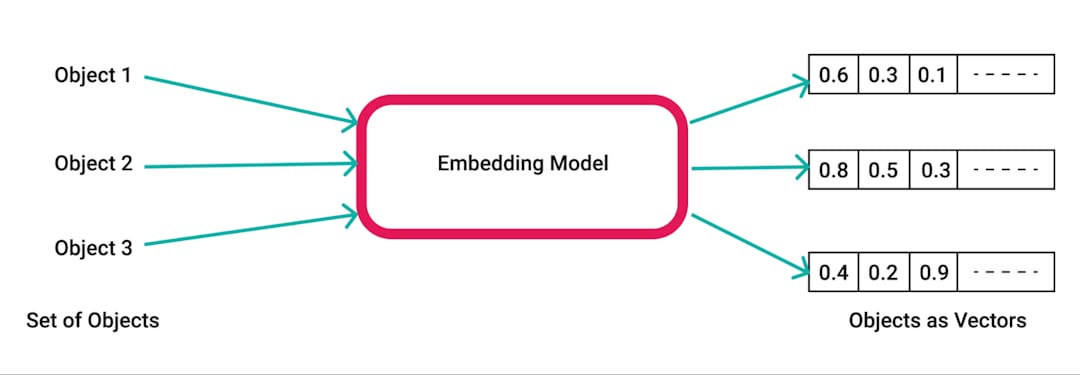
Chroma , di mana embeddings disimpan. Basis data vektor memungkinkan pengambilan informasi yang relevan dengan cepat dan efisien berdasarkan kueri pengguna.ConversationalRetrievalChain didirikan menggunakan LangChain , menggabungkan embeddings yang disimpan di Chroma dengan buffer memori percakapan untuk melacak riwayat dan konteks obrolan.ChatGoogleGenerativeAI (Google Gemini LLM) untuk menghasilkan respons yang relevan dan cerdas terhadap pertanyaan pengguna berdasarkan potongan teks yang diambil dari toko vektor.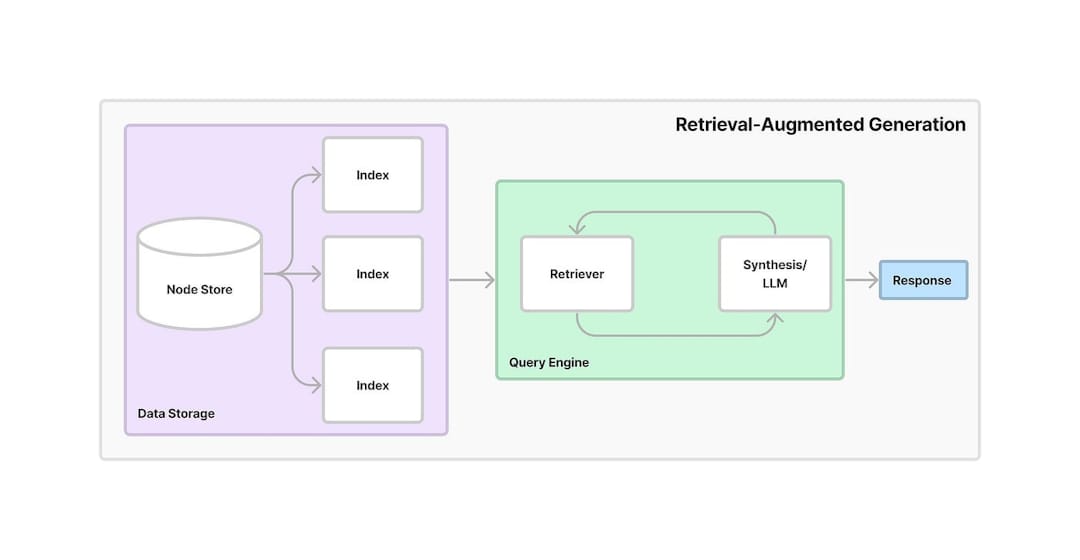
Pengambilan Pengetahuan yang Efisien : Dengan memanfaatkan kekuatan Rag, sistem menggabungkan pengambilan dan generasi untuk menjawab pertanyaan spesifik secara akurat berdasarkan konten dokumen PDF yang diunggah.
Skalabilitas dan fleksibilitas : Dengan teks chunking dan embeddings, aplikasi ini dapat menangani dokumen besar sambil memastikan pengambilan informasi yang cepat dan tepat.
AI Conversational : Memori sejarah percakapan membuat sistem lebih interaktif, karena melacak pertanyaan dan jawaban sebelumnya, mempertahankan konteks selama percakapan yang panjang.
Integrasi Alat AI Modern : Proyek ini menunjukkan penggunaan alat canggih seperti Chroma untuk penyimpanan vektor, LangChain untuk manajemen percakapan, dan Google Gemini LLM untuk menghasilkan jawaban seperti manusia.


