在人工智慧快速發展的時代,語音合成與轉換技術日益成熟,但也帶來了語音偽造等安全隱患。為了因應這項挑戰,保障使用者隱私和資訊安全,浙江大學智慧系統安全實驗室和清華大學合作研發了一個革命性的語音偽造檢測框架-SafeEar。 Downcodes小編將為您詳細解讀SafeEar的創新之處以及其在語音安全領域的突破性貢獻。
在人工智慧快速發展的今天,語音合成和轉換技術日新月異,為我們帶來了無比真實、自然的音訊體驗。然而,這些技術的進步也帶來了潛在的安全隱患,特別是語音克隆技術可能被不法分子利用,威脅個人隱私和社會穩定。
針對這項挑戰,浙江大學智慧系統安全實驗室和清華大學攜手推出了一個革命性的語音偽造檢測框架-SafeEar。這個框架不僅能有效率地偵測偽造音頻,還能在偵測過程中保護用戶的語音隱私,實現了安全與隱私的雙重保障。
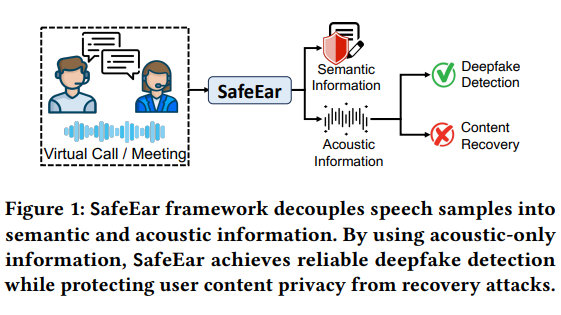
SafeEar的核心技術在於其採用的基於神經音訊編解碼器的解耦模型。這項創新設計能夠將語音的聲學特徵與語意資訊分離,僅依靠聲學特徵進行偽造檢測。這不僅大幅提升了偵測準確性,更重要的是在偵測過程中不會洩漏語音內容,有效保護了使用者隱私。
此框架的結構包括前端解耦模型、瓶頸層、混淆層、偽造檢測器以及真實環境增強等多個模組。透過這些模組的協同工作,SafeEar在面對各種偽造技術時展現出卓越的檢測能力,誤報率低至2.02%,幾乎達到了當前最先進技術的水平。更令人欣喜的是,實驗證明攻擊者無法從聲學資訊中恢復出原始語音內容,充分證明了SafeEar在隱私保護方面的出色表現。
SafeEar的前端模組採用創新的解耦模型,能在分離和重建語音特徵的過程中有效區分聲學和語義資訊。隨後,瓶頸層和混淆層透過降維和隨機混淆進一步保護語音訊息,即使面對最先進的語音辨識模型,也能有效防止真實訊息被擷取。
在偽造檢測方面,SafeEar採用了基於聲學輸入的Transformer分類器,提高了檢測的精確度和效率。此外,透過多種音訊編解碼器模擬不同環境下的音訊情況,SafeEar也增強了模型的環境適應性。
經過一系列嚴格的實驗測試,SafeEar不僅超越了許多傳統檢測方法,還在音訊偽造檢測領域樹立了新的標準。更重要的是,SafeEar能在實際應用中即時保護使用者的語音隱私,為智慧語音服務的安全發展提供了強而有力的支援。
透過這項技術,浙江大學和清華大學不僅開創了語音偽造檢測的新領域,還建構了一個包含多種語言和聲碼器的豐富音訊資料集。這為未來的研究和應用奠定了堅實的基礎,讓用戶在享受便捷語音服務的同時,也能獲得更好的隱私保護。
SafeEar的問世無疑為我們應對AI時代的隱私挑戰提供了一個強而有力的工具,讓我們在享受科技便利的同時,也能更好地保護自己的隱私安全。
論文網址:https://safeearweb.github.io/Project/files/SafeEar_CCS2024.pdf
SafeEar的成功研發,為人工智慧技術的安全應用提供了新的方向和思路,也為未來建構更安全、更可靠的智慧語音生態系統奠定了堅實基礎。相信隨著技術的不斷發展,SafeEar將在更多領域發揮其重要作用。