人工知能の急速な発展の時代において、音声合成および変換技術はますます成熟していますが、音声偽造などのセキュリティリスクももたらします。この課題に対処し、ユーザーのプライバシーと情報セキュリティを確保するために、浙江大学インテリジェント システム セキュリティ研究所と清華大学は協力して、革新的な音声偽造検出フレームワークである SafeEar を開発しました。 Downcodes の編集者が、SafeEar の革新性と音声セキュリティ分野における画期的な貢献について詳しく説明します。
現在、人工知能の急速な発展に伴い、音声合成・変換技術は日進月歩で進歩しており、極めてリアルで自然な音声体験を私たちにもたらしています。しかし、これらの技術の進歩は潜在的なセキュリティリスクももたらし、特に音声クローン技術は犯罪者によって使用され、個人のプライバシーと社会の安定を脅かす可能性があります。
この課題に対応して、浙江大学インテリジェント システム セキュリティ研究所と清華大学は共同で、革新的な音声偽造検出フレームワークである SafeEar を立ち上げました。このフレームワークは、偽造音声を効率的に検出できるだけでなく、検出プロセス中にユーザーの音声プライバシーを保護し、セキュリティとプライバシーの二重の保証を実現します。
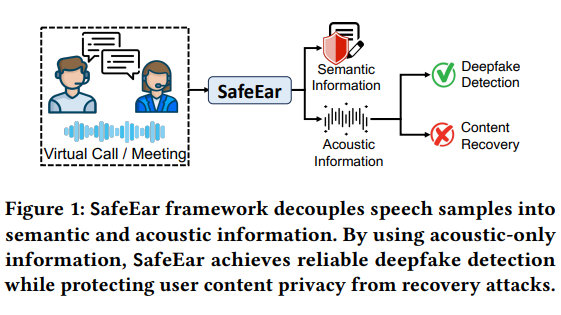
SafeEar の中核テクノロジーは、ニューラル オーディオ コーデックに基づく分離モデルにあります。この革新的な設計により、音声の音響特徴を意味情報から分離し、偽造検出を音響特徴のみに依存することができます。これにより、検出精度が大幅に向上するだけでなく、さらに重要なことに、検出プロセス中に音声コンテンツが漏洩しないため、ユーザーのプライバシーが効果的に保護されます。
フレームワークの構造には、フロントエンド分離モデル、ボトルネック層、混乱層、偽造検出器、実環境強化などの複数のモジュールが含まれています。これらのモジュールの共同作業により、SafeEar はさまざまな偽造技術に対して優れた検出能力を発揮し、誤報率は 2.02% と低く、現在の最先端技術のレベルにほぼ達しています。さらに嬉しいのは、攻撃者が音響情報から元の音声内容を復元できないことが実験で証明されたことで、プライバシー保護における SafeEar の優れた性能が完全に証明されました。
SafeEar のフロントエンド モジュールは、音声特徴の分離と再構築のプロセスで音響情報と意味情報を効果的に区別できる革新的なデカップリング モデルを使用します。その後、ボトルネック層と混乱層が次元削減とランダムな混乱を通じて音声情報をさらに保護します。これにより、最先端の音声認識モデルに直面しても実際の情報が抽出されるのを効果的に防ぐことができます。
偽造品の検出に関しては、SafeEar は音響入力に基づく Transformer 分類器を使用して、検出の精度と効率を向上させます。さらに、SafeEar は、複数のオーディオ コーデックを通じてさまざまな環境でのオーディオ条件をシミュレートすることにより、モデルの環境適応性も強化します。
一連の厳格な実験テストを経て、SafeEar は多くの従来の検出方法を上回っただけでなく、音声偽造検出の分野で新たな基準を打ち立てました。さらに重要なのは、SafeEar は実用的なアプリケーションでユーザーの音声プライバシーをリアルタイムで保護でき、インテリジェントな音声サービスの安全な開発を強力にサポートします。
この技術により、浙江大学と清華大学は音声偽造検出の新しい分野を開拓しただけでなく、複数の言語とボコーダーを含む豊富な音声データセットを構築しました。これにより、将来の研究や応用のための強固な基盤が築かれ、ユーザーは便利な音声サービスを享受しながら、より優れたプライバシー保護を享受できるようになります。
SafeEar の出現は間違いなく、AI 時代におけるプライバシーの課題に対処するための強力なツールを提供し、技術的な利便性を享受しながらプライバシーのセキュリティをより適切に保護できるようになります。
論文アドレス: https://safeearweb.github.io/Project/files/SafeEar_CCS2024.pdf
SafeEar の研究開発の成功は、人工知能テクノロジーの安全な適用のための新しい方向性とアイデアを提供し、将来的にはより安全で信頼性の高いインテリジェント音声エコシステムを構築するための強固な基盤を築きます。テクノロジーの継続的な発展により、SafeEar はより多くの分野で重要な役割を果たすことになると信じています。