في عصر التطور السريع للذكاء الاصطناعي، أصبحت تكنولوجيا تركيب الكلام وتحويله ناضجة بشكل متزايد، ولكنها تجلب أيضًا مخاطر أمنية مثل تزوير الكلام. من أجل مواجهة هذا التحدي وضمان خصوصية المستخدم وأمن المعلومات، تعاون مختبر أمان النظام الذكي بجامعة Zhejiang وجامعة Tsinghua لتطوير إطار عمل ثوري للكشف عن تزوير الصوت - SafeEar. سيشرح محرر Downcodes بالتفصيل ابتكار SafeEar ومساهمته الرائعة في مجال الأمن الصوتي.
اليوم، مع التطور السريع للذكاء الاصطناعي، تتقدم تكنولوجيا تركيب الكلام وتحويله مع مرور كل يوم، مما يقدم لنا تجربة صوتية واقعية وطبيعية للغاية. ومع ذلك، فإن تقدم هذه التقنيات يجلب أيضًا مخاطر أمنية محتملة، على وجه الخصوص، قد يستخدم المجرمون تقنية استنساخ الصوت، مما يهدد الخصوصية الشخصية والاستقرار الاجتماعي.
واستجابة لهذا التحدي، أطلق مختبر أمن النظام الذكي بجامعة تشجيانغ وجامعة تسينغهوا بشكل مشترك إطار عمل ثوريًا للكشف عن تزوير الصوت - SafeEar. لا يستطيع هذا الإطار اكتشاف الصوت المزيف بكفاءة فحسب، بل يمكنه أيضًا حماية خصوصية صوت المستخدم أثناء عملية الكشف، مما يحقق ضمانات مزدوجة للأمان والخصوصية.
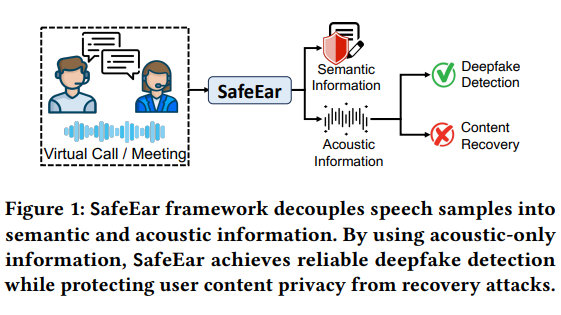
تكمن تقنية SafeEar الأساسية في نموذجها المنفصل المعتمد على برامج الترميز الصوتية العصبية. يمكن لهذا التصميم المبتكر فصل السمات الصوتية للكلام عن المعلومات الدلالية والاعتماد فقط على الميزات الصوتية للكشف عن التزوير. وهذا لا يؤدي إلى تحسين دقة الكشف بشكل كبير فحسب، بل الأهم من ذلك، لن يتم تسريب المحتوى الصوتي أثناء عملية الكشف، مما يحمي خصوصية المستخدم بشكل فعال.
يتضمن هيكل الإطار وحدات متعددة مثل نموذج فصل الواجهة الأمامية وطبقة عنق الزجاجة وطبقة الارتباك وكاشف التزوير وتحسين البيئة الحقيقية. من خلال العمل التعاوني لهذه الوحدات، تُظهر SafeEar قدرات اكتشاف ممتازة في مواجهة تقنيات التزييف المختلفة، مع معدل إنذار كاذب منخفض يصل إلى 2.02%، وهو ما يصل تقريبًا إلى مستوى التكنولوجيا الحديثة الحالية. والأمر الأكثر إرضاءً هو أن التجربة أثبتت أن المهاجم لا يمكنه استعادة محتوى الكلام الأصلي من المعلومات الصوتية، مما يثبت تمامًا أداء SafeEar الممتاز في حماية الخصوصية.
تستخدم الوحدة الأمامية لـ SafeEar نموذجًا مبتكرًا للفصل يمكنه التمييز بشكل فعال بين المعلومات الصوتية والدلالية في عملية فصل ميزات الكلام وإعادة بنائها. بعد ذلك، تعمل طبقة عنق الزجاجة وطبقة الارتباك على حماية معلومات الكلام من خلال تقليل الأبعاد والارتباك العشوائي، مما يمكن أن يمنع بشكل فعال استخراج المعلومات الحقيقية حتى في مواجهة نماذج التعرف على الكلام الأكثر تقدمًا.
فيما يتعلق باكتشاف المنتجات المزيفة، تستخدم SafeEar مصنفًا يعتمد على المدخلات الصوتية لتحسين دقة الكشف وكفاءته. بالإضافة إلى ذلك، تعمل SafeEar أيضًا على تحسين قدرة النموذج على التكيف البيئي من خلال محاكاة الظروف الصوتية في بيئات مختلفة من خلال برامج ترميز صوتية متعددة.
بعد سلسلة من الاختبارات التجريبية الصارمة، لم تتجاوز SafeEar العديد من طرق الكشف التقليدية فحسب، بل وضعت أيضًا معيارًا جديدًا في مجال اكتشاف تزوير الصوت. والأهم من ذلك، يمكن لـ SafeEar حماية خصوصية صوت المستخدمين في الوقت الفعلي في التطبيقات العملية، مما يوفر دعمًا قويًا للتطوير الآمن للخدمات الصوتية الذكية.
باستخدام هذه التكنولوجيا، لم تكن جامعة تشجيانغ وجامعة تسينغهوا رائدة في مجال جديد لاكتشاف تزوير الكلام فحسب، بل قامتا أيضًا ببناء مجموعة بيانات صوتية غنية تتضمن لغات متعددة ومشفرات صوتية. وهذا يضع أساسًا متينًا للأبحاث والتطبيقات المستقبلية، مما يسمح للمستخدمين بالاستمتاع بحماية أفضل للخصوصية مع الاستمتاع بخدمات صوتية مريحة.
لا شك أن ظهور SafeEar يوفر لنا أداة قوية للتعامل مع تحديات الخصوصية في عصر الذكاء الاصطناعي، مما يسمح لنا بحماية أمان خصوصيتنا بشكل أفضل مع الاستمتاع بوسائل الراحة التكنولوجية.
عنوان الورقة: https://safeearweb.github.io/Project/files/SafeEar_CCS2024.pdf
يوفر البحث والتطوير الناجح لـ SafeEar اتجاهات وأفكارًا جديدة للتطبيق الآمن لتكنولوجيا الذكاء الاصطناعي، ويضع أيضًا أساسًا متينًا لبناء نظام صوتي ذكي أكثر أمانًا وموثوقية في المستقبل. أعتقد أنه مع التطور المستمر للتكنولوجيا، سوف تلعب SafeEar دورًا مهمًا في المزيد من المجالات.