En la era del rápido desarrollo de la inteligencia artificial, la tecnología de conversión y síntesis de voz se está volviendo cada vez más madura, pero también conlleva riesgos de seguridad como la falsificación de voz. Para afrontar este desafío y garantizar la privacidad del usuario y la seguridad de la información, el Laboratorio de Seguridad de Sistemas Inteligentes de la Universidad de Zhejiang y la Universidad de Tsinghua colaboraron para desarrollar un marco revolucionario de detección de falsificación de voz: SafeEar. El editor de Downcodes explicará en detalle la innovación de SafeEar y su revolucionaria contribución en el campo de la seguridad de la voz.
Hoy en día, con el rápido desarrollo de la inteligencia artificial, la tecnología de conversión y síntesis de voz avanza cada día, brindándonos una experiencia de audio extremadamente realista y natural. Sin embargo, el avance de estas tecnologías también conlleva riesgos potenciales para la seguridad. En particular, los delincuentes pueden utilizar la tecnología de clonación de voz, lo que amenaza la privacidad personal y la estabilidad social.
En respuesta a este desafío, el Laboratorio de Seguridad de Sistemas Inteligentes de la Universidad de Zhejiang y la Universidad de Tsinghua lanzaron conjuntamente un marco revolucionario de detección de falsificación de voz: SafeEar. Este marco no solo puede detectar de manera eficiente audio falsificado, sino también proteger la privacidad de la voz del usuario durante el proceso de detección, logrando doble garantía de seguridad y privacidad.
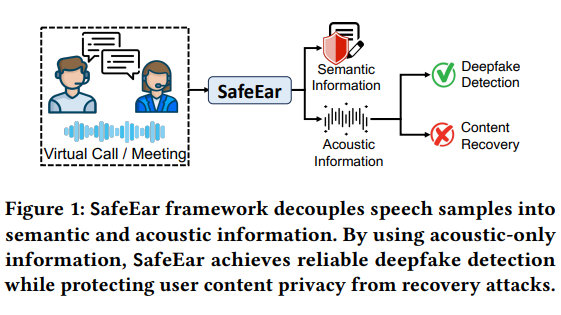
La tecnología central de SafeEar radica en su modelo desacoplado basado en códecs de audio neuronales. Este diseño innovador puede separar las características acústicas del habla de la información semántica y basarse únicamente en características acústicas para la detección de falsificaciones. Esto no sólo mejora en gran medida la precisión de la detección, sino que, lo que es más importante, el contenido de voz no se filtrará durante el proceso de detección, lo que protege eficazmente la privacidad del usuario.
La estructura del marco incluye múltiples módulos, como el modelo de desacoplamiento de front-end, la capa de cuello de botella, la capa de confusión, el detector de falsificaciones y la mejora del entorno real. A través del trabajo colaborativo de estos módulos, SafeEar demuestra excelentes capacidades de detección frente a diversas tecnologías de falsificación, con una tasa de falsas alarmas tan baja como 2,02%, casi alcanzando el nivel de la tecnología de punta actual. Lo que es aún más gratificante es que el experimento demostró que el atacante no puede recuperar el contenido de la voz original a partir de la información acústica, lo que demuestra plenamente el excelente desempeño de SafeEar en la protección de la privacidad.
El módulo frontal de SafeEar utiliza un modelo de desacoplamiento innovador que puede distinguir eficazmente la información acústica y semántica en el proceso de separación y reconstrucción de las características del habla. Posteriormente, la capa de cuello de botella y la capa de confusión protegen aún más la información del habla mediante la reducción de dimensionalidad y la confusión aleatoria, lo que puede evitar de manera efectiva que se extraiga información real incluso frente a los modelos de reconocimiento de voz más avanzados.
En términos de detección de falsificaciones, SafeEar utiliza un clasificador Transformer basado en entrada acústica para mejorar la precisión y eficiencia de la detección. Además, SafeEar también mejora la adaptabilidad ambiental del modelo al simular condiciones de audio en diferentes entornos a través de múltiples códecs de audio.
Después de una serie de rigurosas pruebas experimentales, SafeEar no solo superó muchos métodos de detección tradicionales, sino que también estableció un nuevo estándar en el campo de la detección de falsificaciones de audio. Más importante aún, SafeEar puede proteger la privacidad de voz de los usuarios en tiempo real en aplicaciones prácticas, proporcionando un fuerte apoyo para el desarrollo seguro de servicios de voz inteligentes.
Con esta tecnología, la Universidad de Zhejiang y la Universidad de Tsinghua no solo fueron pioneras en un nuevo campo de detección de falsificación de voz, sino que también crearon un rico conjunto de datos de audio que incluye múltiples idiomas y codificadores de voz. Esto sienta una base sólida para futuras investigaciones y aplicaciones, permitiendo a los usuarios disfrutar de una mejor protección de la privacidad mientras disfrutan de convenientes servicios de voz.
La llegada de SafeEar sin duda nos proporciona una herramienta poderosa para enfrentar los desafíos de privacidad en la era de la IA, lo que nos permite proteger mejor la seguridad de nuestra privacidad mientras disfrutamos de las comodidades tecnológicas.
Dirección del artículo: https://safeearweb.github.io/Project/files/SafeEar_CCS2024.pdf
La exitosa investigación y desarrollo de SafeEar proporciona nuevas direcciones e ideas para la aplicación segura de la tecnología de inteligencia artificial y también sienta una base sólida para construir un ecosistema de voz inteligente más seguro y confiable en el futuro. Creo que con el desarrollo continuo de la tecnología, SafeEar desempeñará un papel importante en más campos.