Na era do rápido desenvolvimento da inteligência artificial, a tecnologia de síntese e conversão de voz está a tornar-se cada vez mais madura, mas também traz riscos de segurança, como a falsificação de voz. Para enfrentar esse desafio e garantir a privacidade do usuário e a segurança das informações, o Laboratório de Segurança de Sistemas Inteligentes da Universidade de Zhejiang e a Universidade de Tsinghua colaboraram para desenvolver uma estrutura revolucionária de detecção de falsificação de voz - SafeEar. O editor do Downcodes explicará detalhadamente a inovação do SafeEar e sua contribuição revolucionária no campo da segurança de voz.
Hoje, com o rápido desenvolvimento da inteligência artificial, a tecnologia de síntese e conversão de fala avança a cada dia que passa, trazendo-nos uma experiência de áudio extremamente realista e natural. No entanto, o avanço destas tecnologias também traz potenciais riscos de segurança. Em particular, a tecnologia de clonagem de voz pode ser utilizada por criminosos, ameaçando a privacidade pessoal e a estabilidade social.
Em resposta a este desafio, o Laboratório de Segurança de Sistemas Inteligentes da Universidade de Zhejiang e a Universidade de Tsinghua lançaram conjuntamente uma estrutura revolucionária de detecção de falsificação de voz - SafeEar. Esta estrutura pode não apenas detectar áudio falsificado com eficiência, mas também proteger a privacidade da voz do usuário durante o processo de detecção, alcançando garantias duplas de segurança e privacidade.
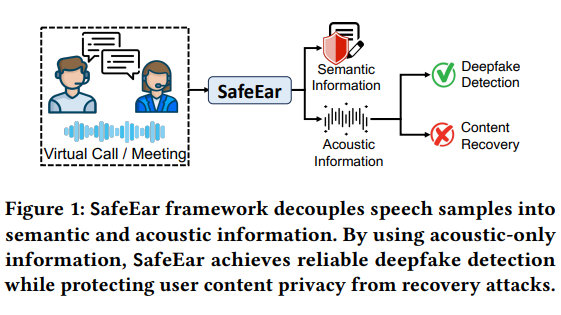
A tecnologia central do SafeEar reside em seu modelo desacoplado baseado em codecs de áudio neurais. Este design inovador pode separar as características acústicas da fala das informações semânticas e confiar apenas nas características acústicas para detecção de falsificações. Isso não apenas melhora muito a precisão da detecção, mas, mais importante ainda, o conteúdo de voz não vazará durante o processo de detecção, protegendo efetivamente a privacidade do usuário.
A estrutura da estrutura inclui vários módulos, como modelo de dissociação front-end, camada de gargalo, camada de confusão, detector de falsificação e aprimoramento do ambiente real. Através do trabalho colaborativo destes módulos, o SafeEar demonstra excelentes capacidades de detecção face a diversas tecnologias de falsificação, com uma taxa de falsos alarmes tão baixa como 2,02%, quase atingindo o nível da tecnologia de ponta actual. O que é ainda mais gratificante é que o experimento provou que o invasor não consegue recuperar o conteúdo original da fala a partir das informações acústicas, o que comprova plenamente o excelente desempenho do SafeEar na proteção da privacidade.
O módulo front-end do SafeEar usa um modelo de desacoplamento inovador que pode distinguir com eficácia informações acústicas e semânticas no processo de separação e reconstrução de recursos de fala. Posteriormente, a camada de gargalo e a camada de confusão protegem ainda mais as informações de fala por meio da redução da dimensionalidade e da confusão aleatória, o que pode efetivamente impedir que as informações reais sejam extraídas, mesmo diante dos modelos de reconhecimento de fala mais avançados.
Em termos de detecção de falsificações, o SafeEar usa um classificador Transformer baseado em entrada acústica para melhorar a precisão e eficiência da detecção. Além disso, o SafeEar também melhora a adaptabilidade ambiental do modelo, simulando condições de áudio em diferentes ambientes por meio de múltiplos codecs de áudio.
Após uma série de testes experimentais rigorosos, o SafeEar não apenas superou muitos métodos tradicionais de detecção, mas também estabeleceu um novo padrão no campo da detecção de falsificação de áudio. Mais importante ainda, o SafeEar pode proteger a privacidade da voz dos usuários em tempo real em aplicações práticas, fornecendo forte suporte para o desenvolvimento seguro de serviços de voz inteligentes.
Com esta tecnologia, a Universidade de Zhejiang e a Universidade de Tsinghua não apenas foram pioneiras em um novo campo de detecção de falsificação de fala, mas também construíram um rico conjunto de dados de áudio que inclui vários idiomas e codificadores de voz. Isto estabelece uma base sólida para pesquisas e aplicações futuras, permitindo que os usuários desfrutem de melhor proteção de privacidade enquanto desfrutam de serviços de voz convenientes.
O advento do SafeEar, sem dúvida, nos fornece uma ferramenta poderosa para lidar com os desafios de privacidade na era da IA, permitindo-nos proteger melhor nossa segurança de privacidade enquanto desfrutamos das conveniências tecnológicas.
Endereço do artigo: https://safeearweb.github.io/Project/files/SafeEar_CCS2024.pdf
A pesquisa e o desenvolvimento bem-sucedidos do SafeEar fornecem novas direções e ideias para a aplicação segura da tecnologia de inteligência artificial e também estabelecem uma base sólida para a construção de um ecossistema de voz inteligente mais seguro e confiável no futuro. Acredito que com o desenvolvimento contínuo da tecnologia, o SafeEar desempenhará um papel importante em mais campos.