In the era of rapid development of artificial intelligence, speech synthesis and conversion technology is becoming increasingly mature, but it also brings security risks such as speech forgery. In order to meet this challenge and ensure user privacy and information security, Zhejiang University Intelligent System Security Laboratory and Tsinghua University collaborated to develop a revolutionary voice forgery detection framework - SafeEar. The editor of Downcodes will explain in detail the innovation of SafeEar and its breakthrough contribution in the field of voice security.
Today, with the rapid development of artificial intelligence, speech synthesis and conversion technology are advancing with each passing day, bringing us an extremely realistic and natural audio experience. However, the advancement of these technologies also brings potential security risks. In particular, voice cloning technology may be used by criminals, threatening personal privacy and social stability.
In response to this challenge, Zhejiang University Intelligent System Security Laboratory and Tsinghua University jointly launched a revolutionary voice forgery detection framework - SafeEar. This framework can not only efficiently detect forged audio, but also protect the user's voice privacy during the detection process, achieving dual guarantees of security and privacy.
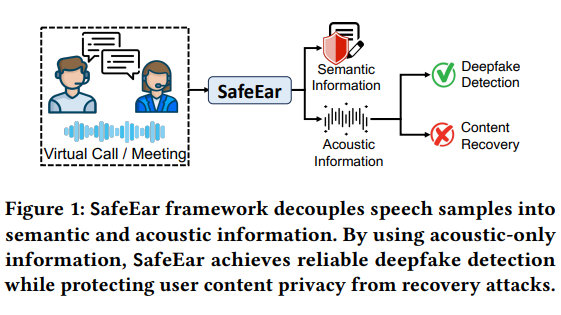
SafeEar’s core technology lies in its decoupled model based on neural audio codecs. This innovative design can separate the acoustic features of speech from semantic information and rely only on acoustic features for forgery detection. This not only greatly improves the detection accuracy, but more importantly, the voice content will not be leaked during the detection process, effectively protecting user privacy.
The structure of the framework includes multiple modules such as front-end decoupling model, bottleneck layer, confusion layer, forgery detector, and real environment enhancement. Through the collaborative work of these modules, SafeEar demonstrates excellent detection capabilities in the face of various counterfeiting technologies, with a false alarm rate as low as 2.02%, almost reaching the level of the current state-of-the-art technology. What's even more gratifying is that the experiment proved that the attacker cannot recover the original speech content from the acoustic information, which fully proves SafeEar's excellent performance in privacy protection.
SafeEar's front-end module uses an innovative decoupling model that can effectively distinguish acoustic and semantic information in the process of separating and reconstructing speech features. Subsequently, the bottleneck layer and confusion layer further protect the speech information through dimensionality reduction and random confusion, which can effectively prevent the real information from being extracted even in the face of the most advanced speech recognition models.
In terms of counterfeit detection, SafeEar uses a Transformer classifier based on acoustic input to improve detection accuracy and efficiency. In addition, SafeEar also enhances the model's environmental adaptability by simulating audio conditions in different environments through multiple audio codecs.
After a series of rigorous experimental tests, SafeEar not only surpassed many traditional detection methods, but also set a new standard in the field of audio forgery detection. More importantly, SafeEar can protect users' voice privacy in real time in practical applications, providing strong support for the safe development of intelligent voice services.
With this technology, Zhejiang University and Tsinghua University not only pioneered a new field of speech forgery detection, but also built a rich audio data set that includes multiple languages and vocoders. This lays a solid foundation for future research and applications, allowing users to enjoy better privacy protection while enjoying convenient voice services.
The advent of SafeEar undoubtedly provides us with a powerful tool to deal with privacy challenges in the AI era, allowing us to better protect our privacy security while enjoying technological conveniences.
Paper address: https://safeearweb.github.io/Project/files/SafeEar_CCS2024.pdf
The successful research and development of SafeEar provides new directions and ideas for the safe application of artificial intelligence technology, and also lays a solid foundation for building a safer and more reliable intelligent voice ecosystem in the future. I believe that with the continuous development of technology, SafeEar will play an important role in more fields.