Im Zeitalter der rasanten Entwicklung der künstlichen Intelligenz wird die Technologie zur Sprachsynthese und -konvertierung immer ausgereifter, birgt jedoch auch Sicherheitsrisiken wie Sprachfälschung. Um dieser Herausforderung zu begegnen und die Privatsphäre und Informationssicherheit der Benutzer zu gewährleisten, haben das Intelligent System Security Laboratory der Zhejiang University und die Tsinghua University gemeinsam ein revolutionäres Framework zur Erkennung von Sprachfälschungen entwickelt – SafeEar. Der Herausgeber von Downcodes wird die Innovation von SafeEar und seinen bahnbrechenden Beitrag im Bereich der Sprachsicherheit ausführlich erläutern.
Heutzutage, mit der rasanten Entwicklung der künstlichen Intelligenz, schreiten die Sprachsynthese- und Konvertierungstechnologien jeden Tag voran und bescheren uns ein äußerst realistisches und natürliches Audioerlebnis. Allerdings birgt die Weiterentwicklung dieser Technologien auch potenzielle Sicherheitsrisiken. Insbesondere kann die Voice-Cloning-Technologie von Kriminellen genutzt werden und die Privatsphäre und die soziale Stabilität gefährden.
Als Reaktion auf diese Herausforderung haben das Intelligent System Security Laboratory der Zhejiang University und die Tsinghua University gemeinsam ein revolutionäres Framework zur Erkennung von Sprachfälschungen eingeführt – SafeEar. Dieses Framework kann nicht nur gefälschte Audiodaten effizient erkennen, sondern auch die Privatsphäre der Stimme des Benutzers während des Erkennungsprozesses schützen und so doppelte Garantien für Sicherheit und Datenschutz bieten.
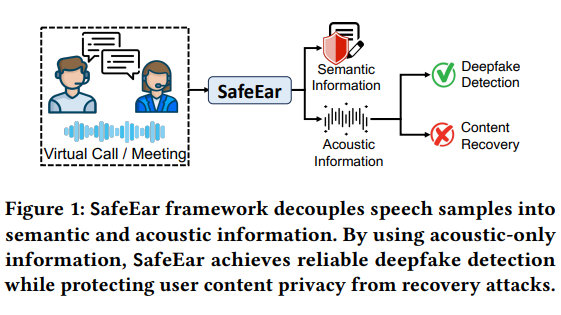
Die Kerntechnologie von SafeEar liegt in seinem entkoppelten Modell, das auf neuronalen Audio-Codecs basiert. Dieses innovative Design kann die akustischen Merkmale von Sprache von semantischen Informationen trennen und sich zur Fälschungserkennung ausschließlich auf akustische Merkmale verlassen. Dadurch wird nicht nur die Erkennungsgenauigkeit erheblich verbessert, sondern, was noch wichtiger ist, der Sprachinhalt wird während des Erkennungsprozesses nicht durchsickern, wodurch die Privatsphäre des Benutzers wirksam geschützt wird.
Die Struktur des Frameworks umfasst mehrere Module wie Front-End-Entkopplungsmodell, Engpassschicht, Verwirrungsschicht, Fälschungsdetektor und Verbesserung der realen Umgebung. Durch die Zusammenarbeit dieser Module weist SafeEar hervorragende Erkennungsfähigkeiten gegenüber verschiedenen Fälschungstechnologien auf, wobei die Fehlalarmrate nur 2,02 % beträgt und damit fast das Niveau der aktuellen Spitzentechnologie erreicht. Noch erfreulicher ist, dass das Experiment gezeigt hat, dass der Angreifer den ursprünglichen Sprachinhalt nicht aus den akustischen Informationen wiederherstellen kann, was die hervorragende Leistung von SafeEar beim Schutz der Privatsphäre voll und ganz unter Beweis stellt.
Das Frontend-Modul von SafeEar nutzt ein innovatives Entkopplungsmodell, das akustische und semantische Informationen beim Trennen und Rekonstruieren von Sprachmerkmalen effektiv unterscheiden kann. Anschließend schützen die Engpassschicht und die Verwirrungsschicht die Sprachinformationen durch Dimensionsreduzierung und zufällige Verwirrung weiter, wodurch selbst bei den fortschrittlichsten Spracherkennungsmodellen effektiv verhindert werden kann, dass echte Informationen extrahiert werden.
Im Hinblick auf die Erkennung von Fälschungen verwendet SafeEar einen Transformer-Klassifikator, der auf akustischen Eingaben basiert, um die Erkennungsgenauigkeit und -effizienz zu verbessern. Darüber hinaus verbessert SafeEar auch die Anpassungsfähigkeit des Modells an die Umgebung, indem es Audiobedingungen in verschiedenen Umgebungen durch mehrere Audio-Codecs simuliert.
Nach einer Reihe strenger experimenteller Tests übertraf SafeEar nicht nur viele herkömmliche Erkennungsmethoden, sondern setzte auch einen neuen Standard im Bereich der Erkennung von Audiofälschungen. Noch wichtiger ist, dass SafeEar in praktischen Anwendungen die Privatsphäre der Benutzer in Echtzeit schützen kann und so die sichere Entwicklung intelligenter Sprachdienste stark unterstützt.
Mit dieser Technologie haben die Universitäten Zhejiang und Tsinghua nicht nur ein neues Gebiet der Erkennung von Sprachfälschungen erschlossen, sondern auch einen umfangreichen Audiodatensatz erstellt, der mehrere Sprachen und Vocoder umfasst. Dies legt eine solide Grundlage für zukünftige Forschungen und Anwendungen und ermöglicht Benutzern einen besseren Schutz der Privatsphäre bei gleichzeitig bequemen Sprachdiensten.
Das Aufkommen von SafeEar bietet uns zweifellos ein leistungsstarkes Tool zur Bewältigung der Datenschutzherausforderungen im KI-Zeitalter, das es uns ermöglicht, unsere Privatsphäre besser zu schützen und gleichzeitig technologische Annehmlichkeiten zu genießen.
Papieradresse: https://safeearweb.github.io/Project/files/SafeEar_CCS2024.pdf
Die erfolgreiche Forschung und Entwicklung von SafeEar liefert neue Richtungen und Ideen für die sichere Anwendung der Technologie der künstlichen Intelligenz und legt außerdem eine solide Grundlage für den Aufbau eines sichereren und zuverlässigeren intelligenten Sprachökosystems in der Zukunft. Ich glaube, dass SafeEar mit der kontinuierlichen Weiterentwicklung der Technologie in mehr Bereichen eine wichtige Rolle spielen wird.