À l'ère du développement rapide de l'intelligence artificielle, la technologie de synthèse et de conversion vocale devient de plus en plus mature, mais elle entraîne également des risques de sécurité tels que la falsification de parole. Afin de relever ce défi et de garantir la confidentialité des utilisateurs et la sécurité des informations, le laboratoire de sécurité des systèmes intelligents de l'université du Zhejiang et l'université de Tsinghua ont collaboré pour développer un cadre révolutionnaire de détection de contrefaçon vocale : SafeEar. L'éditeur de Downcodes expliquera en détail l'innovation de SafeEar et son apport révolutionnaire dans le domaine de la sécurité vocale.
Aujourd’hui, avec le développement rapide de l’intelligence artificielle, les technologies de synthèse et de conversion vocales progressent chaque jour, nous offrant une expérience audio extrêmement réaliste et naturelle. Cependant, les progrès de ces technologies comportent également des risques potentiels en matière de sécurité. En particulier, la technologie de clonage vocal peut être utilisée par des criminels, menaçant ainsi la vie privée et la stabilité sociale.
En réponse à ce défi, le laboratoire de sécurité des systèmes intelligents de l'université du Zhejiang et l'université de Tsinghua ont lancé conjointement un cadre révolutionnaire de détection de contrefaçon vocale : SafeEar. Ce cadre peut non seulement détecter efficacement les faux sons, mais également protéger la confidentialité vocale de l'utilisateur pendant le processus de détection, offrant ainsi une double garantie de sécurité et de confidentialité.
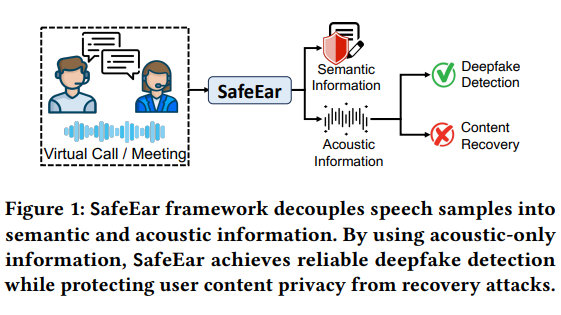
La technologie de base de SafeEar réside dans son modèle découplé basé sur des codecs audio neuronaux. Cette conception innovante peut séparer les caractéristiques acoustiques de la parole des informations sémantiques et s'appuyer uniquement sur les caractéristiques acoustiques pour la détection des contrefaçons. Cela améliore non seulement considérablement la précision de la détection, mais plus important encore, le contenu vocal ne sera pas divulgué pendant le processus de détection, protégeant ainsi efficacement la confidentialité des utilisateurs.
La structure du framework comprend plusieurs modules tels que le modèle de découplage frontal, la couche de goulot d'étranglement, la couche de confusion, le détecteur de contrefaçon et l'amélioration de l'environnement réel. Grâce au travail collaboratif de ces modules, SafeEar démontre d'excellentes capacités de détection face à diverses technologies de contrefaçon, avec un taux de fausses alarmes aussi bas que 2,02 %, atteignant presque le niveau de la technologie de pointe actuelle. Ce qui est encore plus gratifiant, c'est que l'expérience a prouvé que l'attaquant ne peut pas récupérer le contenu vocal original à partir des informations acoustiques, ce qui prouve pleinement les excellentes performances de SafeEar en matière de protection de la vie privée.
Le module frontal de SafeEar utilise un modèle de découplage innovant capable de distinguer efficacement les informations acoustiques et sémantiques dans le processus de séparation et de reconstruction des caractéristiques vocales. Par la suite, la couche de goulot d'étranglement et la couche de confusion protègent davantage les informations vocales grâce à une réduction de dimensionnalité et une confusion aléatoire, ce qui peut efficacement empêcher l'extraction des informations réelles, même face aux modèles de reconnaissance vocale les plus avancés.
En termes de détection des contrefaçons, SafeEar utilise un classificateur Transformer basé sur une entrée acoustique pour améliorer la précision et l'efficacité de la détection. De plus, SafeEar améliore également l'adaptabilité environnementale du modèle en simulant les conditions audio dans différents environnements via plusieurs codecs audio.
Après une série de tests expérimentaux rigoureux, SafeEar a non seulement surpassé de nombreuses méthodes de détection traditionnelles, mais a également établi une nouvelle norme dans le domaine de la détection de contrefaçon audio. Plus important encore, SafeEar peut protéger la confidentialité vocale des utilisateurs en temps réel dans des applications pratiques, offrant ainsi un soutien solide au développement sécurisé de services vocaux intelligents.
Grâce à cette technologie, l'Université du Zhejiang et l'Université Tsinghua ont non seulement été pionnières dans un nouveau domaine de détection de contrefaçon vocale, mais ont également construit un riche ensemble de données audio comprenant plusieurs langues et vocodeurs. Cela constitue une base solide pour les recherches et applications futures, permettant aux utilisateurs de bénéficier d’une meilleure protection de la vie privée tout en bénéficiant de services vocaux pratiques.
L'avènement de SafeEar nous fournit sans aucun doute un outil puissant pour faire face aux défis de confidentialité à l'ère de l'IA, nous permettant de mieux protéger la sécurité de notre vie privée tout en bénéficiant des commodités technologiques.
Adresse papier : https://safeearweb.github.io/Project/files/SafeEar_CCS2024.pdf
La recherche et le développement réussis de SafeEar fournissent de nouvelles orientations et idées pour l'application sûre de la technologie de l'intelligence artificielle, et jettent également des bases solides pour la construction d'un écosystème vocal intelligent plus sûr et plus fiable à l'avenir. Je crois qu'avec le développement continu de la technologie, SafeEar jouera un rôle important dans davantage de domaines.