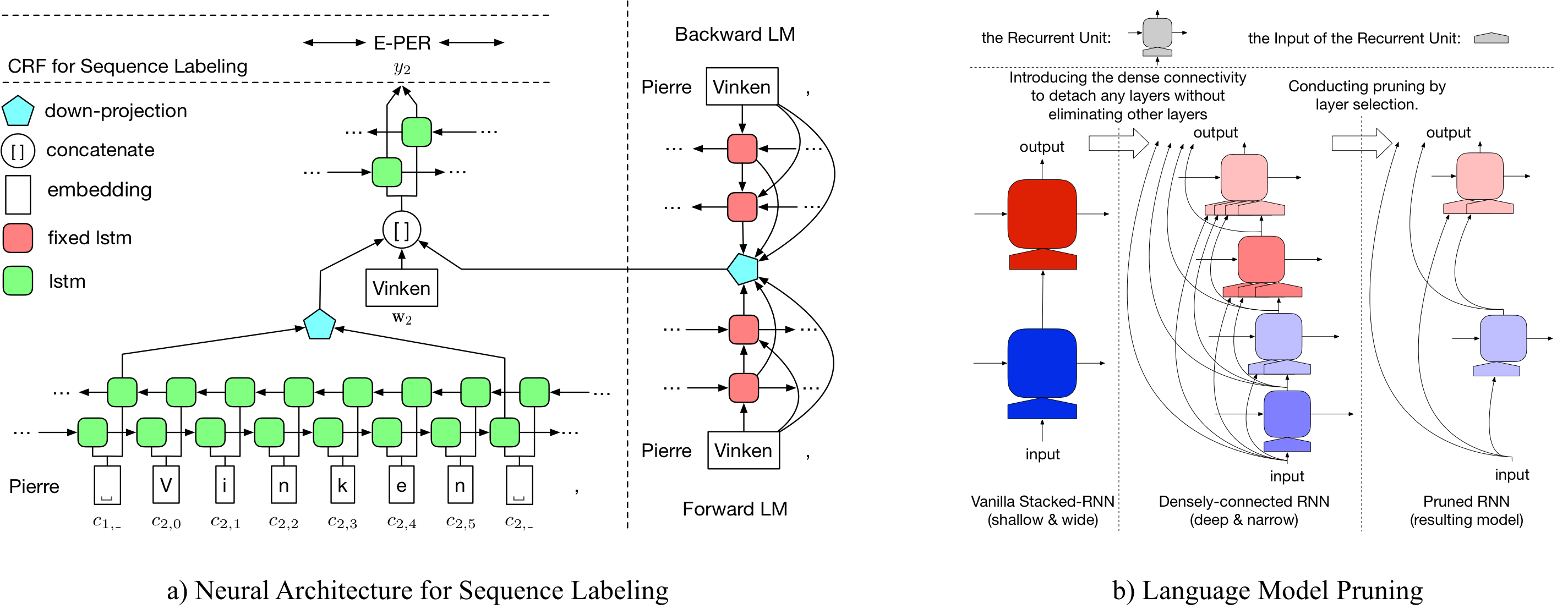
LD Net
1.0.0
檢查我們的新NER工具包
LD-NET提供的序列標籤模型具有:
顯而易見的是,我們的預訓練的NER模型達到了:
有關LD-NET的詳細信息可以通過以下網址訪問:https://arxiv.org/abs/1804.07827。
| Conll03的型號 | #Flops | 平均(F1) | 性病(F1) |
|---|---|---|---|
| 香草ner wo lm | 3 m | 90.78 | 0.24 |
| LD-NET(修剪) | 51 m | 91.86 | 0.15 |
| LD-NET(原點,基於Dev F1選擇) | 51 m | 91.95 | |
| LD-NET(修剪) | 5 m | 91.84 | 0.14 |
| Conll00的型號 | #Flops | 平均(F1) | 性病(F1) |
|---|---|---|---|
| 香草np wo lm | 3 m | 94.42 | 0.08 |
| LD-NET(修剪) | 51 m | 96.01 | 0.07 |
| LD-NET(原點,基於Dev F1選擇) | 51 m | 96.13 | |
| LD-NET(修剪) | 10 m | 95.66 | 0.04 |
在這裡,我們提供預訓練的語言模型和預訓練的序列標籤模型。
我們驗證的語言模型包含單詞嵌入,10層密集連接的LSTM和Adative SoftMax,並在10億個基準數據集中達到50.06的平均PPL。
| 遠期語言模型 | 向後語言模型 |
|---|---|
| 下載鏈接 | 下載鏈接 |
原始的預訓練的命名實體Tagger達到了91.95 F1,修剪標記的標籤達到了92.08 F1。
| 原始標記器 | 修剪的標記器 |
|---|---|
| 下載鏈接 | 下載鏈接 |
原始的預訓練的命名實體Tagger達到96.13 F1,修剪標記的標籤達到了95.79 F1。
| 原始標記器 | 修剪的標記器 |
|---|---|
| 下載鏈接 | 下載鏈接 |
要修剪原始LD-NET的CONLL03 NER,請運行:
bash ldnet_ner_prune.sh
要修剪原始的LD-NET進行Conll00塊,請運行:
bash ldnet_np_prune.sh
我們的軟件包基於Python 3.6和以下包:
numpy
tqdm
torch-scope
torch==0.4.1
pre_seq和pre_word_ada中可用預處理腳本,而預處理的數據已存儲在:
| ner | 分塊 |
|---|---|
| 下載鏈接 | 下載鏈接 |
我們的實現可在model_seq和model_word_ada中獲得,並且文檔託管在readThedoc中
| ner | 分塊 |
|---|---|
| 下載鏈接 | 下載鏈接 |
有關模型推斷,請檢查我們的Lightner軟件包
如果您發現實現有用,請引用以下論文:有效上下文化表示:序列標籤的語言模型修剪
@inproceedings{liu2018efficient,
title = "{Efficient Contextualized Representation: Language Model Pruning for Sequence Labeling}",
author = {Liu, Liyuan and Ren, Xiang and Shang, Jingbo and Peng, Jian and Han, Jiawei},
booktitle = {EMNLP},
year = 2018,
}


