LD Net
1.0.0
Consulte nuestro nuevo kit de herramientas NER
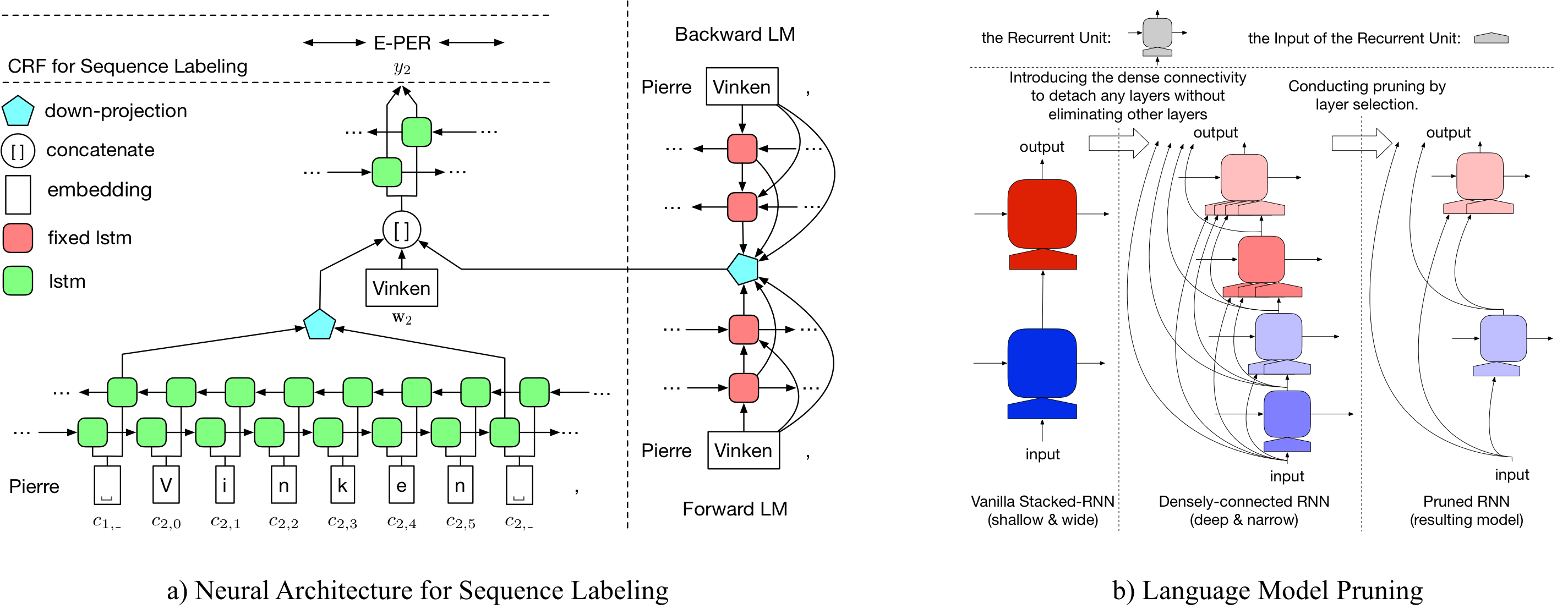
LD-Net proporciona modelos de etiquetado de secuencia con:
Observablemente, nuestro modelo NER previamente capacitado logrado:
Se pueden acceder a los detalles sobre LD-NET en: https://arxiv.org/abs/1804.07827.
| Modelo para Conll03 | #Flops | Media (F1) | STD (F1) |
|---|---|---|---|
| Vainilla ner wo lm | 3 m | 90.78 | 0.24 |
| LD-NET (poda) | 51 m | 91.86 | 0.15 |
| LD-NET (origen, seleccionado basado en Dev F1) | 51 m | 91.95 | |
| LD-NET (podado) | 5 m | 91.84 | 0.14 |
| Modelo para Conll00 | #Flops | Media (F1) | STD (F1) |
|---|---|---|---|
| Vainilla np wo lm | 3 m | 94.42 | 0.08 |
| LD-NET (poda) | 51 m | 96.01 | 0.07 |
| LD-NET (origen, seleccionado basado en Dev F1) | 51 m | 96.13 | |
| LD-NET (podado) | 10 m | 95.66 | 0.04 |
Aquí proporcionamos modelos de lenguaje previamente capacitados y modelos de etiquetado de secuencia previamente capacitados.
Nuestro modelo de lenguaje previo a la aparición contiene una incrustación de palabras, LSTM densamente conectada de 10 capas y Softmax adatoso, y alcanza una PPL promedio de 50.06 en el conjunto de datos de referencia de un mil millones.
| Modelo de lenguaje avanzado | Modelo de idioma atrasado |
|---|---|
| Enlace de descarga | Enlace de descarga |
El etiqueta de entidad con nombre previamente entrenado original logra 91.95 F1, el etiquetado podado logró 92.08 F1.
| Etiqueta original | Etiquete podinado |
|---|---|
| Enlace de descarga | Enlace de descarga |
El etiqueta de entidad con nombre previamente entrenado original logra 96.13 F1, el etiquetado podado logró 95.79 F1.
| Etiqueta original | Etiquete podinado |
|---|---|
| Enlace de descarga | Enlace de descarga |
Para podar el LD-Net original para el conll03 ner, ejecute:
bash ldnet_ner_prune.sh
Para podar el LD-Net original para la fragmentación de Conll00, ejecute:
bash ldnet_np_prune.sh
Nuestro paquete se basa en Python 3.6 y en los siguientes paquetes:
numpy
tqdm
torch-scope
torch==0.4.1
Los scripts de preprocesos están disponibles en pre_seq y pre_word_ada , mientras que los datos preprocesados se han almacenado en:
| Ner | Fragmento |
|---|---|
| Enlace de descarga | Enlace de descarga |
Nuestras implementaciones están disponibles en model_seq y model_word_ada , y las documentos están alojadas en readthedoc
| Ner | Fragmento |
|---|---|
| Enlace de descarga | Enlace de descarga |
Para la inferencia del modelo, consulte nuestro paquete Lightner
Si encuentra útil la implementación, cita el siguiente documento: Representación contextualizada eficiente: poda del modelo de lenguaje para el etiquetado de secuencia
@inproceedings{liu2018efficient,
title = "{Efficient Contextualized Representation: Language Model Pruning for Sequence Labeling}",
author = {Liu, Liyuan and Ren, Xiang and Shang, Jingbo and Peng, Jian and Han, Jiawei},
booktitle = {EMNLP},
year = 2018,
}


