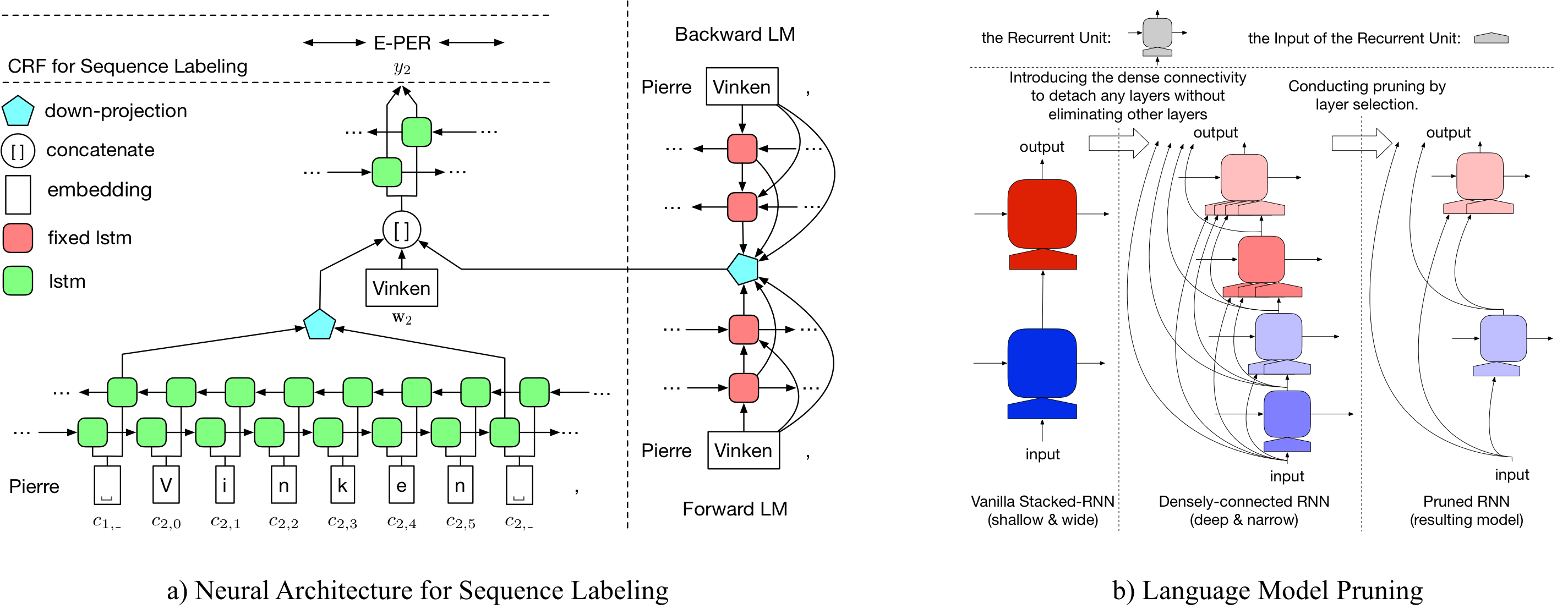
LD Net
1.0.0
Überprüfen Sie unser neues NER -Toolkit
LD-NET bietet Sequenzmarkierungsmodelle mit:
Bemerkenswert ist unser vorgebildetes NER-Modell erreicht:
Details zu Ld-Net können auf: https://arxiv.org/abs/1804.07827 zugegriffen werden.
| Modell für conll03 | #Flops | Mittelwert (F1) | STD (F1) |
|---|---|---|---|
| Vanille -ner wo lm | 3 m | 90.78 | 0,24 |
| Ld-net (wo beschnitten) | 51 m | 91.86 | 0,15 |
| Ld-net (Origin, ausgewählt auf Dev F1) | 51 m | 91.95 | |
| Ld-net (beschnitten) | 5 m | 91.84 | 0,14 |
| Modell für conll00 | #Flops | Mittelwert (F1) | STD (F1) |
|---|---|---|---|
| Vanille np wo lm | 3 m | 94.42 | 0,08 |
| Ld-net (wo beschnitten) | 51 m | 96.01 | 0,07 |
| Ld-net (Origin, ausgewählt auf Dev F1) | 51 m | 96.13 | |
| Ld-net (beschnitten) | 10 m | 95.66 | 0,04 |
Hier bieten wir sowohl vorgeborene Sprachmodelle als auch vorgebreitete Sequenzmodelle an.
Unser vorgezogenes Sprachmodell enthält eine Worteinbettung, 10-Schicht-dicht vernetzte LSTM und Adative Softmax und erreicht einen durchschnittlichen PPL von 50,06 für den einen Milliarde Benchmark-Datensatz.
| Vorwärtssprachmodell | Rückwärtssprachenmodell |
|---|---|
| Link herunterladen | Link herunterladen |
Der ursprüngliche vorgebildete named entity tagger erreicht 91.95 f1, das beschnittene Tagged erreicht 92.08 F1.
| Original -Tagger | Beschnittener Tagger |
|---|---|
| Link herunterladen | Link herunterladen |
Der ursprüngliche vorgebildete namens entity tagger erreicht 96.13 f1, das beschnittene markierte 95.79 F1.
| Original -Tagger | Beschnittener Tagger |
|---|---|
| Link herunterladen | Link herunterladen |
Um das ursprüngliche LD-Netz für den CONLL03 NER zu beschneiden, rennen Sie bitte:
bash ldnet_ner_prune.sh
Um das ursprüngliche LD-Netz für das Conll00-Chunking zu beschneiden, rennen Sie bitte:
bash ldnet_np_prune.sh
Unser Paket basiert auf Python 3.6 und den folgenden Paketen:
numpy
tqdm
torch-scope
torch==0.4.1
Vorverarbeitungsskripte sind in pre_seq und pre_word_ada verfügbar, während vorverarbeitete Daten gespeichert wurden in:
| Ner | Chunking |
|---|---|
| Link herunterladen | Link herunterladen |
Unsere Implementierungen sind in model_seq und model_word_ada verfügbar, und die Dokumentationen werden in redeTHEDOC gehostet
| Ner | Chunking |
|---|---|
| Link herunterladen | Link herunterladen |
Für Modellinferenz finden Sie in unserem Lightner -Paket
Wenn Sie die Implementierung nützlich finden, zitieren Sie das folgende Papier: Effiziente kontextualisierte Darstellung: Sprachmodell -Beschneidung für die Sequenzmarkierung
@inproceedings{liu2018efficient,
title = "{Efficient Contextualized Representation: Language Model Pruning for Sequence Labeling}",
author = {Liu, Liyuan and Ren, Xiang and Shang, Jingbo and Peng, Jian and Han, Jiawei},
booktitle = {EMNLP},
year = 2018,
}


