LD Net
1.0.0
Periksa toolkit ner baru kami
LD-NET menyediakan model pelabelan urutan yang menampilkan:
Luar biasa, model NER kami terlatih dicapai:
Detail tentang LD-Net dapat diakses di: https://arxiv.org/abs/1804.07827.
| Model untuk conll03 | #Flops | Rata -rata (f1) | STD (F1) |
|---|---|---|---|
| Vanilla ner wo lm | 3 m | 90.78 | 0.24 |
| LD-NET (pemangkasan wo) | 51 m | 91.86 | 0,15 |
| LD-NET (Asal, dipilih berdasarkan Dev F1) | 51 m | 91.95 | |
| LD-net (dipangkas) | 5 m | 91.84 | 0.14 |
| Model untuk Conll00 | #Flops | Rata -rata (f1) | STD (F1) |
|---|---|---|---|
| Vanilla np wo lm | 3 m | 94.42 | 0,08 |
| LD-NET (pemangkasan wo) | 51 m | 96.01 | 0,07 |
| LD-NET (Asal, dipilih berdasarkan Dev F1) | 51 m | 96.13 | |
| LD-net (dipangkas) | 10 m | 95.66 | 0,04 |
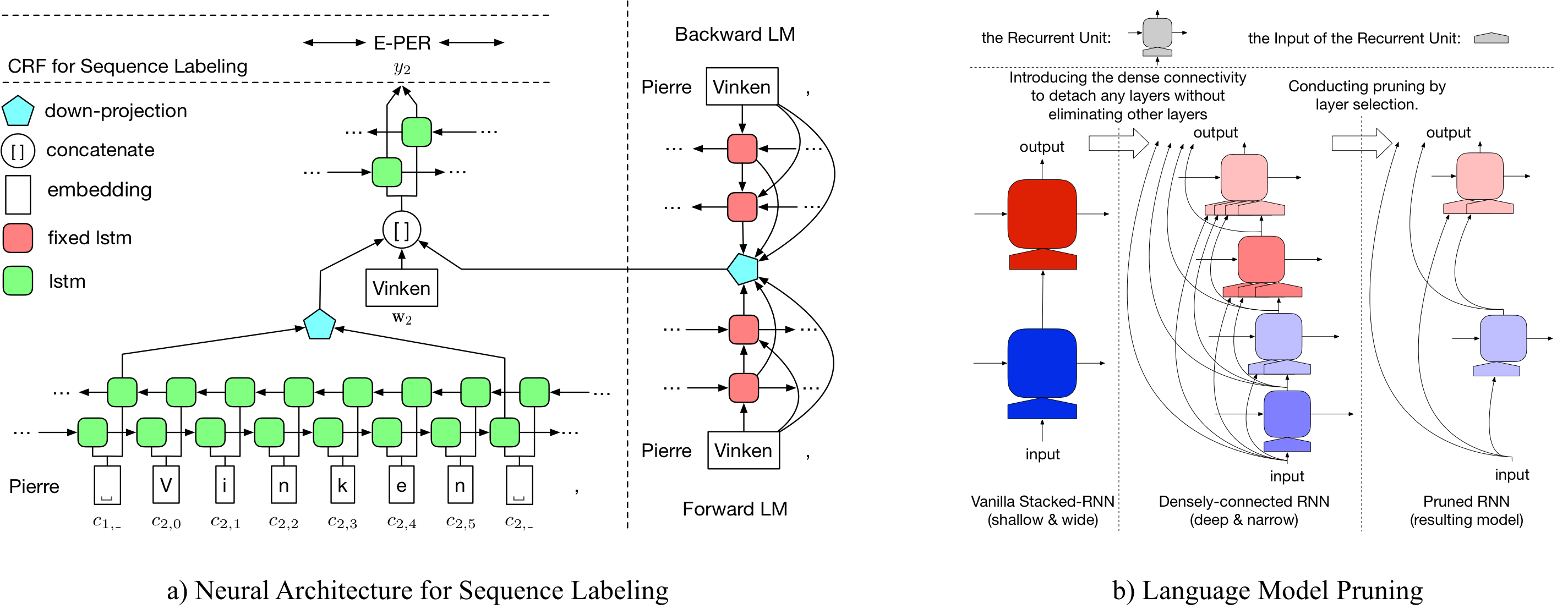
Di sini kami menyediakan model bahasa pra-terlatih dan model pelabelan urutan pra-terlatih.
Model bahasa pretrained kami berisi kata embedding, 10-lapis LSTM yang terhubung padat dan softmax adive, dan mencapai ppl rata-rata 50,06 pada satu miliar dataset tolok ukur.
| Model Bahasa Maju | Model bahasa terbelakang |
|---|---|
| Tautan unduh | Tautan unduh |
Entity Tagger yang bernama pra-terlatih asli mencapai 91.95 F1, tag yang dipangkas mencapai 92.08 F1.
| Tagger asli | Tagger yang dipangkas |
|---|---|
| Tautan unduh | Tautan unduh |
Entity Tagger yang bernama pra-terlatih asli mencapai 96.13 F1, tag yang dipangkas mencapai 95,79 F1.
| Tagger asli | Tagger yang dipangkas |
|---|---|
| Tautan unduh | Tautan unduh |
Untuk memangkas LD-net asli untuk Conll03 ner, silakan jalankan:
bash ldnet_ner_prune.sh
Untuk memangkas LD-net asli untuk conll00 chunking, silakan jalankan:
bash ldnet_np_prune.sh
Paket kami didasarkan pada Python 3.6 dan paket berikut:
numpy
tqdm
torch-scope
torch==0.4.1
Script pra-proses tersedia di pre_seq dan pre_word_ada , sedangkan data pra-diproses telah disimpan dalam:
| Ner | Chunking |
|---|---|
| Tautan unduh | Tautan unduh |
Implementasi kami tersedia di model_seq dan model_word_ada , dan dokumentasi di -host di readthedoc
| Ner | Chunking |
|---|---|
| Tautan unduh | Tautan unduh |
Untuk inferensi model, silakan periksa paket Lightner kami
Jika Anda menemukan implementasinya bermanfaat, silakan kutip makalah berikut: Representasi kontekstual yang efisien: Pemangkasan model bahasa untuk pelabelan urutan
@inproceedings{liu2018efficient,
title = "{Efficient Contextualized Representation: Language Model Pruning for Sequence Labeling}",
author = {Liu, Liyuan and Ren, Xiang and Shang, Jingbo and Peng, Jian and Han, Jiawei},
booktitle = {EMNLP},
year = 2018,
}


