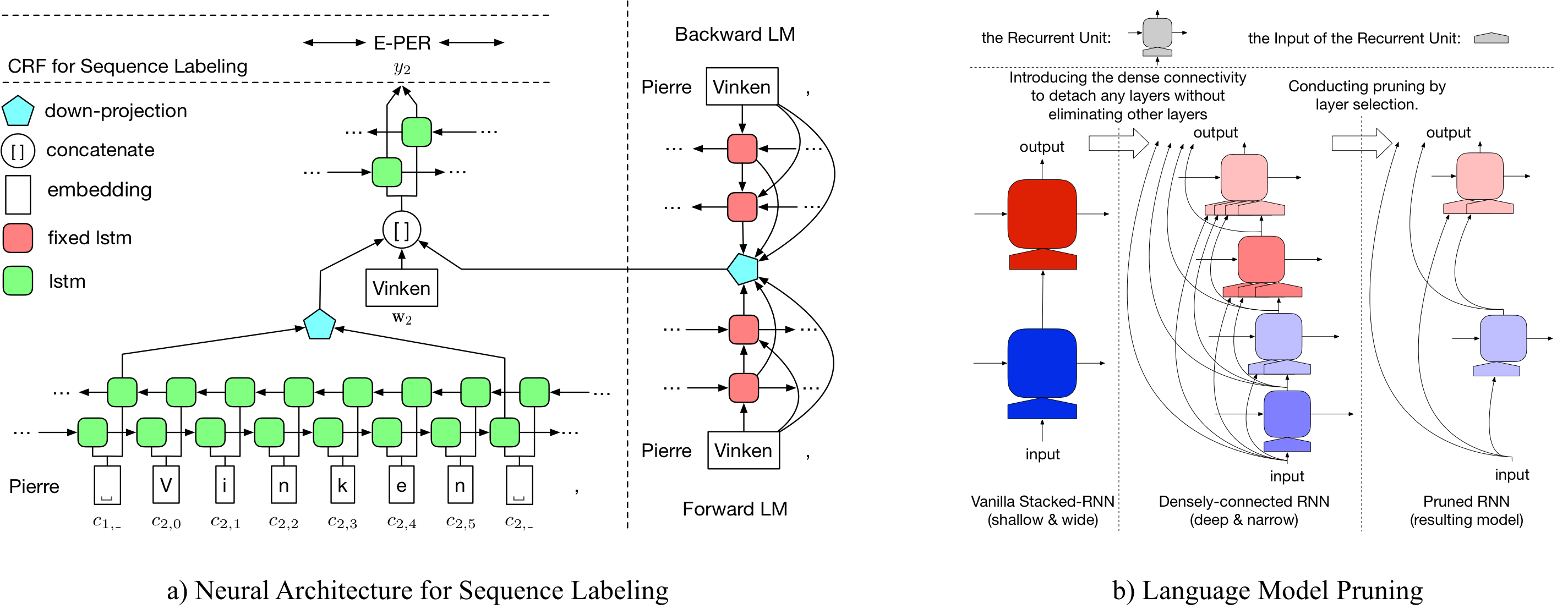
LD Net
1.0.0
Verifique nosso novo kit de ferramentas nerds
LD-NET fornece modelos de rotulagem de sequência com:
Observado, nosso modelo NER pré-treinado alcançado:
Detalhes sobre LD-Net podem ser acessados em: https://arxiv.org/abs/1804.07827.
| Modelo para CONLL03 | #Flops | Média (F1) | Std (f1) |
|---|---|---|---|
| Baunilha nerd wo lm | 3 m | 90.78 | 0,24 |
| LD-NET (WO PUNING) | 51 m | 91.86 | 0,15 |
| LD-NET (Origem, escolhido com base no dev f1) | 51 m | 91.95 | |
| LD-NET (podado) | 5 m | 91.84 | 0,14 |
| Modelo para CONLL00 | #Flops | Média (F1) | Std (f1) |
|---|---|---|---|
| Baunilha np wo lm | 3 m | 94.42 | 0,08 |
| LD-NET (WO PUNING) | 51 m | 96.01 | 0,07 |
| LD-NET (Origem, escolhido com base no dev f1) | 51 m | 96.13 | |
| LD-NET (podado) | 10 m | 95.66 | 0,04 |
Aqui, fornecemos modelos de idiomas pré-treinados e modelos de rotulagem de sequência pré-treinados.
Nosso modelo de idioma pré-treinamento contém incorporação de palavras, LSTM densamente conectadas de 10 camadas e softmax adativo, e obtém um ppl médio de 50,06 no conjunto de dados de um bilhão de benchmark.
| Modelo de linguagem para a frente | Modelo de linguagem para trás |
|---|---|
| Baixar link | Baixar link |
A entidade nomeada pré-treinada original alcança 91.95 F1, a marcada podada alcançada 92.08 F1.
| Tagger original | Tagger podado |
|---|---|
| Baixar link | Baixar link |
A entidade nomeada pré-treinada original alcança 96.13 F1, a marcada podada alcançada 95.79 F1.
| Tagger original | Tagger podado |
|---|---|
| Baixar link | Baixar link |
Para podar o LD-Net original para o NER CONLL03, execute:
bash ldnet_ner_prune.sh
Para podar o LD-Net original para o Conll00 Chunking, corra:
bash ldnet_np_prune.sh
Nosso pacote é baseado no Python 3.6 e nos seguintes pacotes:
numpy
tqdm
torch-scope
torch==0.4.1
Os scripts pré-processo estão disponíveis em pre_seq e pre_word_ada , enquanto dados pré-processados foram armazenados em:
| Ner | Chunking |
|---|---|
| Baixar link | Baixar link |
Nossas implementações estão disponíveis em model_seq e model_word_ada , e as documentações são hospedadas no ReadThedoc
| Ner | Chunking |
|---|---|
| Baixar link | Baixar link |
Para inferência do modelo, verifique nosso pacote Lightner
Se você achar útil a implementação, cite o seguinte artigo: Representação contextualizada eficiente: Modelo de idioma Pruagem para marcação de sequência
@inproceedings{liu2018efficient,
title = "{Efficient Contextualized Representation: Language Model Pruning for Sequence Labeling}",
author = {Liu, Liyuan and Ren, Xiang and Shang, Jingbo and Peng, Jian and Han, Jiawei},
booktitle = {EMNLP},
year = 2018,
}


