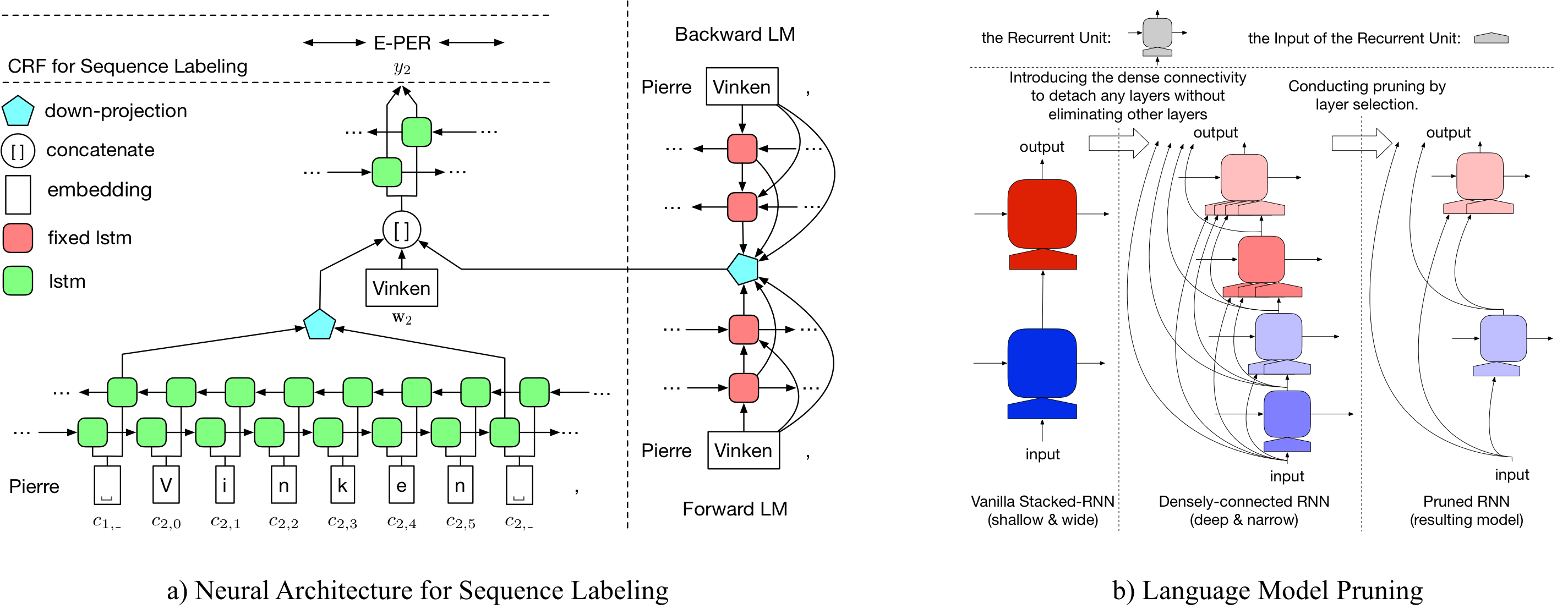
LD Net
1.0.0
ตรวจสอบชุดเครื่องมือใหม่ของเรา
LD-NET ให้แบบจำลองการติดฉลากลำดับที่มี:
รูปแบบ NER ที่ผ่านการฝึกอบรมมาก่อนของเราประสบความสำเร็จ:
รายละเอียดเกี่ยวกับ LD-NET สามารถเข้าถึงได้ที่: https://arxiv.org/abs/1804.07827
| แบบจำลองสำหรับ conll03 | #flops | ค่าเฉลี่ย (F1) | std (F1) |
|---|---|---|---|
| วานิลลา ner wo lm | 3 ม. | 90.78 | 0.24 |
| LD-NET (WO การตัดแต่ง) | 51 ม. | 91.86 | 0.15 |
| LD-NET (Origin, เลือกตาม Dev F1) | 51 ม. | 91.95 | |
| LD-NET (ตัดแต่ง) | 5 ม. | 91.84 | 0.14 |
| รุ่นสำหรับ conll00 | #flops | ค่าเฉลี่ย (F1) | std (F1) |
|---|---|---|---|
| วานิลลา np wo lm | 3 ม. | 94.42 | 0.08 |
| LD-NET (WO การตัดแต่ง) | 51 ม. | 96.01 | 0.07 |
| LD-NET (Origin, เลือกตาม Dev F1) | 51 ม. | 96.13 | |
| LD-NET (ตัดแต่ง) | 10 ม. | 95.66 | 0.04 |
ที่นี่เรามีทั้งแบบจำลองภาษาที่ผ่านการฝึกอบรมมาก่อนและแบบจำลองการติดฉลากลำดับก่อนที่ได้รับการฝึกฝนมาก่อน
แบบจำลองภาษาที่ผ่านการฝึกฝนของเรามีการฝังคำ, LSTM ที่เชื่อมต่อกันอย่างหนาแน่น 10 ชั้นและ Softmax ที่มีความหนาแน่นและได้รับ ppl เฉลี่ย 50.06 ในชุดข้อมูลเกณฑ์มาตรฐานหนึ่งพันล้าน
| รูปแบบภาษาส่งต่อ | รูปแบบภาษาย้อนหลัง |
|---|---|
| ลิงค์ดาวน์โหลด | ลิงค์ดาวน์โหลด |
เอนทิตี้ที่ได้รับการฝึกอบรมก่อนหน้านี้ได้รับการฝึกฝนมาก่อน 91.95 F1 ซึ่งเป็นแท็กที่ถูกแท็กได้รับ 92.08 F1
| Tagger ดั้งเดิม | Tagger ที่ตัดแต่ง |
|---|---|
| ลิงค์ดาวน์โหลด | ลิงค์ดาวน์โหลด |
Tagger ที่ได้รับการฝึกฝนมาก่อนที่ได้รับการฝึกฝนมาก่อนได้รับ 96.13 F1, แท็กที่ถูกแท็กตัดแต่งสำเร็จ 95.79 F1
| Tagger ดั้งเดิม | Tagger ที่ตัดแต่ง |
|---|---|
| ลิงค์ดาวน์โหลด | ลิงค์ดาวน์โหลด |
ในการตัดแต่ง LD-NET ดั้งเดิมสำหรับ conll03 ner โปรดเรียกใช้:
bash ldnet_ner_prune.sh
ในการตัดแต่ง LD-NET ดั้งเดิมสำหรับ conll00 chunking โปรดเรียกใช้:
bash ldnet_np_prune.sh
แพ็คเกจของเราขึ้นอยู่กับ Python 3.6 และแพ็คเกจต่อไปนี้:
numpy
tqdm
torch-scope
torch==0.4.1
สคริปต์ก่อนกระบวนการมีอยู่ใน pre_seq และ pre_word_ada ในขณะที่ข้อมูลที่ประมวลผลล่วงหน้าได้ถูกเก็บไว้ใน:
| คนโง่ | การตี |
|---|---|
| ลิงค์ดาวน์โหลด | ลิงค์ดาวน์โหลด |
การใช้งานของเรามีอยู่ใน model_seq และ model_word_ada และเอกสารประกอบเป็นโฮสต์ใน readthedoc
| คนโง่ | การตี |
|---|---|
| ลิงค์ดาวน์โหลด | ลิงค์ดาวน์โหลด |
สำหรับการอนุมานแบบจำลองโปรดตรวจสอบแพ็คเกจ Lightner ของเรา
หากคุณพบว่าการใช้งานมีประโยชน์โปรดอ้างอิงบทความต่อไปนี้: การเป็นตัวแทนบริบทที่มีประสิทธิภาพ: การตัดแต่งแบบจำลองภาษาสำหรับการติดฉลากลำดับ
@inproceedings{liu2018efficient,
title = "{Efficient Contextualized Representation: Language Model Pruning for Sequence Labeling}",
author = {Liu, Liyuan and Ren, Xiang and Shang, Jingbo and Peng, Jian and Han, Jiawei},
booktitle = {EMNLP},
year = 2018,
}


