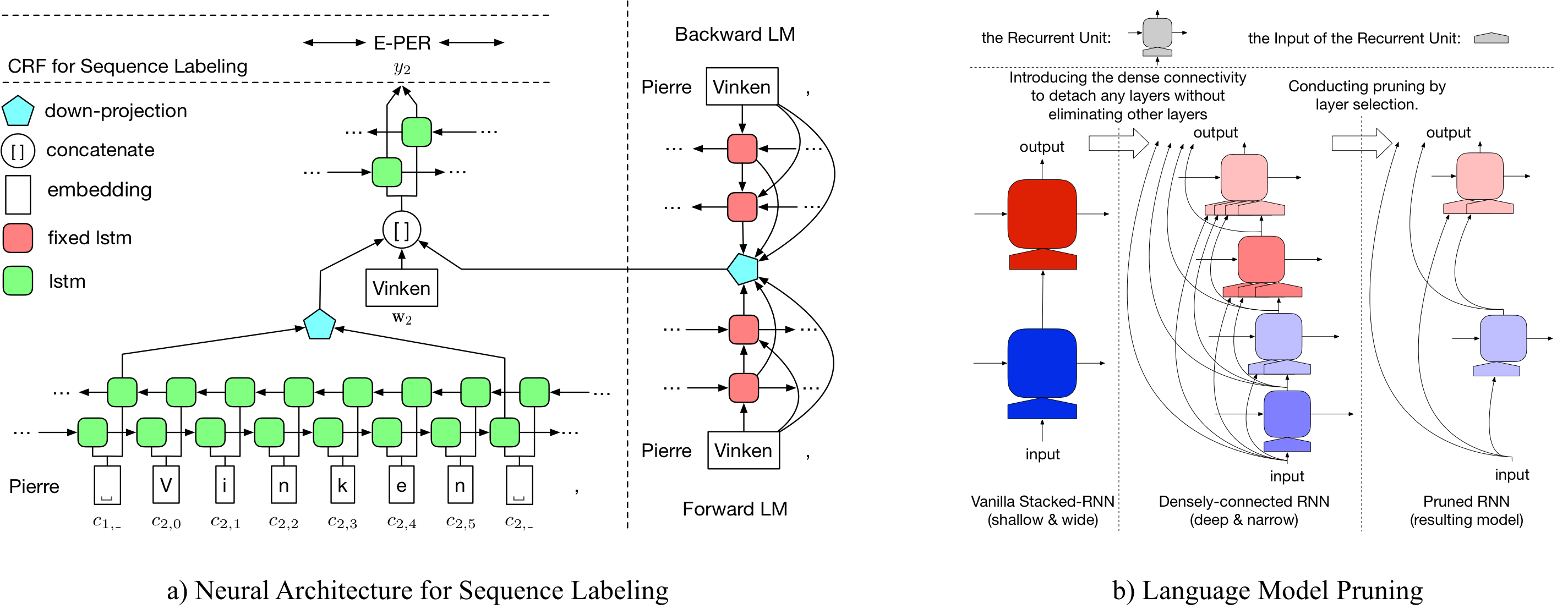
LD Net
1.0.0
Vérifiez notre nouvelle boîte à outils NER
LD-NET fournit des modèles d'étiquetage de séquence avec:
Remarquable, notre modèle NER pré-formé a obtenu:
Les détails sur LD-Net sont accessibles à: https://arxiv.org/abs/1804.07827.
| Modèle pour conll03 | #Flops | Moyenne (F1) | Std (F1) |
|---|---|---|---|
| Vanilla ner wo lm | 3 m | 90,78 | 0,24 |
| LD-NET (WO TUNING) | 51 m | 91.86 | 0,15 |
| LD-NET (Origin, choisi basé sur Dev F1) | 51 m | 91,95 | |
| LD-net (taillé) | 5 m | 91.84 | 0,14 |
| Modèle pour Conll00 | #Flops | Moyenne (F1) | Std (F1) |
|---|---|---|---|
| Vanille np wo lm | 3 m | 94.42 | 0,08 |
| LD-NET (WO TUNING) | 51 m | 96.01 | 0,07 |
| LD-NET (Origin, choisi basé sur Dev F1) | 51 m | 96.13 | |
| LD-net (taillé) | 10 m | 95.66 | 0,04 |
Ici, nous fournissons à la fois des modèles de langage pré-formés et des modèles de marquage de séquence pré-formés.
Notre modèle de langage pré-entraîné contient une incorporation de mots, un LSTM et un softmax adatifs densément connectés à 10 couches, et réalisent un PPL moyen de 50,06 sur l'ensemble de données de référence d'un milliard de milliards de dollars.
| Modèle de langue avant | Modèle de langue arrière |
|---|---|
| Lien de téléchargement | Lien de téléchargement |
Le tagueur d'entité nommé pré-formé d'origine atteint 91,95 F1, le tagué élagué a atteint 92,08 F1.
| Étiqueteur d'origine | Étiqueteur taillé |
|---|---|
| Lien de téléchargement | Lien de téléchargement |
Le tagueur d'entité nommé pré-formé d'origine atteint 96,13 F1, le tagué élagué a atteint 95,79 F1.
| Étiqueteur d'origine | Étiqueteur taillé |
|---|---|
| Lien de téléchargement | Lien de téléchargement |
Pour élaguer le LD-NET d'origine pour le conll03 NER, veuillez exécuter:
bash ldnet_ner_prune.sh
Pour élagage du LD-NET d'origine pour le CONLL00 Chunking, veuillez exécuter:
bash ldnet_np_prune.sh
Notre package est basé sur Python 3.6 et les packages suivants:
numpy
tqdm
torch-scope
torch==0.4.1
Les scripts de prétraitement sont disponibles en pre_seq et pre_word_ada , tandis que les données prétraitées ont été stockées:
| Nervure | Se déchaîner |
|---|---|
| Lien de téléchargement | Lien de téléchargement |
Nos implémentations sont disponibles dans model_seq et model_word_ada , et les documentations sont hébergées dans ReadThedoc
| Nervure | Se déchaîner |
|---|---|
| Lien de téléchargement | Lien de téléchargement |
Pour l'inférence du modèle, veuillez vérifier notre package Lightner
Si vous trouvez la mise en œuvre utile, veuillez citer l'article suivant: Représentation contextualisée efficace: élagage du modèle linguistique pour l'étiquetage des séquences
@inproceedings{liu2018efficient,
title = "{Efficient Contextualized Representation: Language Model Pruning for Sequence Labeling}",
author = {Liu, Liyuan and Ren, Xiang and Shang, Jingbo and Peng, Jian and Han, Jiawei},
booktitle = {EMNLP},
year = 2018,
}


