t2t tuner
1.0.0
變壓器方便的文本到文本培訓
pip install t2t-tuner需要Pytorch:遵循Pytorch安裝說明或使用Pytorch容器。
基於精美的擁抱面庫。在T5和GPT類型的模型上測試。從理論上講,它應該與支持AutomodelForseq2Seqlm或AutomodelForCausAllm的其他模型一起使用。
此庫中的培訓師是一個更高級別的接口,可以根據huggingface的run_translation.py腳本進行文本到文本生成任務的腳本工作。我決定我想要一個更方便的界面,用於培訓和推斷,以及訪問諸如梯度檢查點和平行模型之類的東西,以適合較大的型號 - 這些已經在HuggingFace庫中,但在腳本中不曝光。我還添加了一些我想要的功能(及時調整,型號摘要),將其與自回歸的LM培訓集成在一起,並將其包裹為可以安裝PIP的單個庫。
import t2t
trainer_arguments = t2t . TrainerArguments ( model_name_or_path = "t5-small" ,
train_file = YOUR_DATASET )
trainer = t2t . Trainer ( arguments = trainer_arguments )
# train without validation
trainer . train ( valid = False )有關更多具體示例,請查看以下鏈接的筆記本:
SEQ2SEQ培訓
{ "translation" : { "s" : " TEXT " , "t" : " LABEL " }}TrainingArguments.source_id和TrainingArguments.target_id中定義源ID和目標ID(默認為s和t )。TrainingArguments.prefix中預先添加到文本。自迴旋LM培訓
本節將概述如何在相對簡單的設置上訓練大型語言模型(> 1個BIL參數)。
有關以下報告的配置的一些註釋:
TrainerArguments.gradient_checkpointing )。trainer.freeze(embeddings=True) )。TrainingArguments.gradient_accumulation_steps )來彌補較大的批量大小,如果需要。報告的批次大小沒有梯度積累。一些GPT配置已測試,以便能夠在單個RTX 3090(24GB)卡上訓練(無deepspeed):
| 模型 | 參數 | 精確 | 優化器 | 輸入 | 批處理 | 其他 |
|---|---|---|---|---|---|---|
| GPT2 | 1.5b | FP16 | afactor | 128 | 4 | 沒有任何 |
| GPT2 | 1.5b | FP16 | afactor | 512 | 1 | 沒有任何 |
| GPT2 | 1.5b | FP16 | afactor | 1024 | 4 | gradcheckpoint |
| gpt-neo | 1.3b | FP16 | afactor | 1024 | 1 | 沒有任何 |
| gpt-neo | 1.3b | FP16 | afactor | 2048 | 4 | gradcheckpoint |
| gpt-neo | 2.7b | FP16 | afactor | 2048 | 4 | gradcheckpoint,凍結 |
一些T5配置已測試以在單個RTX 3090(24GB)卡上進行訓練(無deepspeed):
| 模型 | 參數 | 精確 | 優化器 | seq2seqlen | 批處理 | 其他 |
|---|---|---|---|---|---|---|
| T5 | 3b | fp32 | afactor | 128-> 128 | 1 | 凍結 |
| T5 | 3b | fp32 | afactor | 128-> 128 | 1 | gradcheckpoint |
| T5 | 3b | fp32 | afactor | 128-> 128 | 128 | gradcheckpoint,凍結 |
| T5 | 3b | fp32 | afactor | 512-> 512 | 32 | gradcheckpoint,凍結 |
T5-11b模型的模型並行性
使用此庫,您還可以輕鬆地(單節點)輕鬆地調整T5-11b檢查點(無需深速):
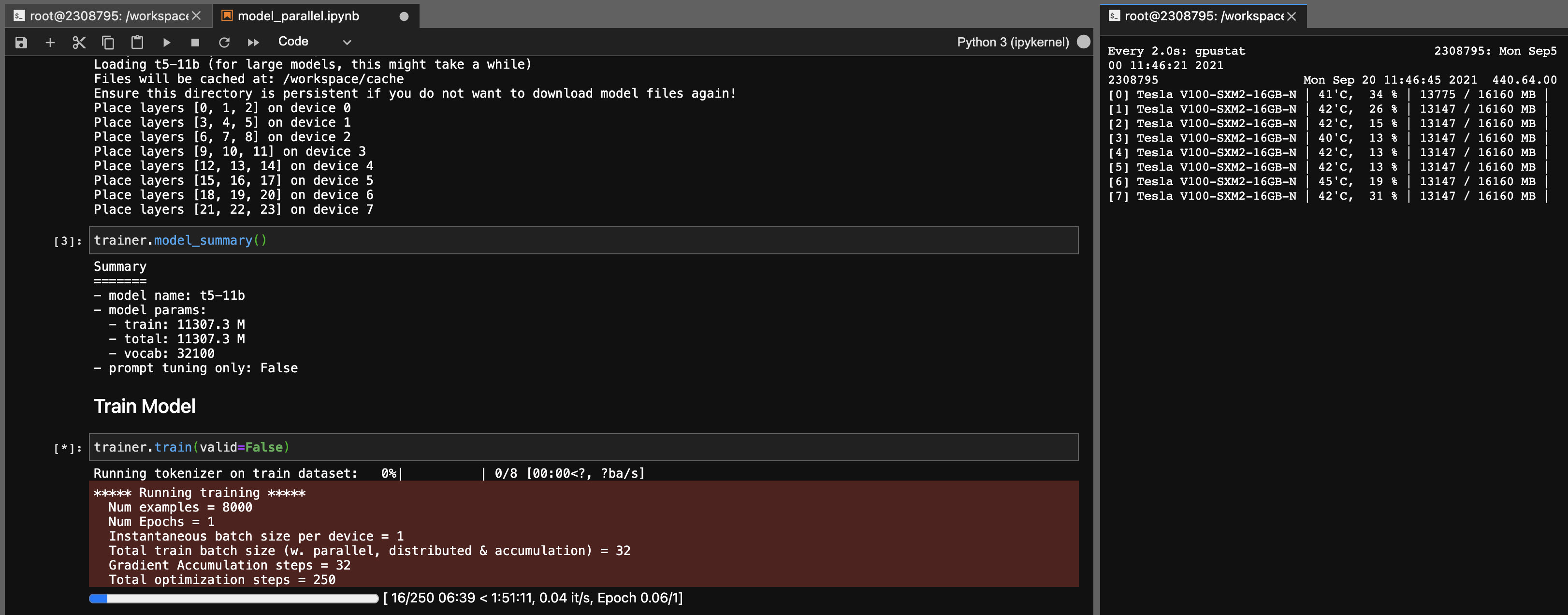
請注意,根據您的系統,檢查點(46GB)的加載時間可能很長。您需要大量的CPU RAM(至少〜90GB)才能成功加載它。
ONNX RT與某些型號(不是T5)一起使用,並且可以提供較小的速度提升。
安裝ORT,然後設置TrainingArguments.torch_ort=True
pip install torch-ort -f https://onnxruntimepackages.z14.web.core.windows.net/onnxruntime_stable_torch190.cu111.html
python -m torch_ort.configure建築包
python3 -m pip install --upgrade build twine
python3 -m build
python3 -m twine upload dist/ * 這個圖書館是作為我自己使用的個人項目開發的。請隨意叉子或將其用於您自己的目的。由於該圖書館的使用情況,我不會對發生的任何不幸負責。
注意3090 fe卡,如果您的粉絲達到100%,則意味著您的VRAM溫度很高(> 100度C)。從理論上講,在這些溫度下長時間的訓練應該很好,但是如果您想放心(像我一樣),則可以降低功率上限對訓練速度產生較小的影響。只要您的粉絲從未達到100%,您的VRAM溫度就應該很好。例如,將功率限制降至300W(從350W):
sudo nvidia-smi -pl 300

