t2t tuner
1.0.0
トランス向けのテキストからテキストへの便利なトレーニング
pip install t2t-tunerPytorchが必要です。Pytorchのインストール手順に従うか、Pytorchコンテナを使用します。
Wonderful Huggingface Transformers Libraryに基づいています。 T5およびGPTタイプのモデルでテストされました。理論的には、AutomodElforseq2SeqlmまたはAutomodelforcausallmをサポートする他のモデルと連携する必要があります。
ここのこのライブラリのトレーナーは、テキストからテキストの生成タスクのHuggingfaceのrun_translation.pyスクリプトに基づいて、より高いレベルのインターフェイスです。勾配チェックポイントやモデルの並行してより大きなモデルに合わせてアクセスするとともに、トレーニングと推測のために、より便利なインターフェイスが必要になりたいと思いました。これらはすでにハグFaceライブラリにありますが、スクリプトには公開されていません。また、私が望んでいたいくつかの機能(プロンプトチューニング、モデルの概要)を追加し、それをオートレーフレフなLMトレーニングと統合し、PIPインストールできる単一のライブラリとしてラップしました。
import t2t
trainer_arguments = t2t . TrainerArguments ( model_name_or_path = "t5-small" ,
train_file = YOUR_DATASET )
trainer = t2t . Trainer ( arguments = trainer_arguments )
# train without validation
trainer . train ( valid = False )より具体的な例については、以下にリンクしたノートブックをご覧ください。
seq2seqトレーニング
{ "translation" : { "s" : " TEXT " , "t" : " LABEL " }}TrainingArguments.source_idおよびTrainingArguments.target_id (デフォルトはsとt )のソースとターゲットIDを定義します。TrainingArguments.prefixのテキストにプレップするプレフィックスを定義します。オートレーフレフLMトレーニング
このセクションでは、比較的単純なセットアップで大規模な言語モデル(> 1 BILパラメーター)をトレーニングする方法の概要を説明します。
以下に報告された構成に関するいくつかのメモ:
TrainerArguments.gradient_checkpointing )。trainer.freeze(embeddings=True) )。TrainingArguments.gradient_accumulation_steps )を使用して、必要に応じて大きなバッチサイズまで補うことができます。報告されているバッチサイズは、勾配蓄積なしです。単一のRTX 3090(24GB)カード(ディープスピードなし)でトレーニングできるようにテストされたいくつかのGPT構成:
| モデル | パラメージ | 精度 | オプティマイザ | inputlen | バッチサイズ | 他の |
|---|---|---|---|---|---|---|
| GPT2 | 1.5b | FP16 | AdaFactor | 128 | 4 | なし |
| GPT2 | 1.5b | FP16 | AdaFactor | 512 | 1 | なし |
| GPT2 | 1.5b | FP16 | AdaFactor | 1024 | 4 | GradCheckpoint |
| gpt-neo | 1.3b | FP16 | AdaFactor | 1024 | 1 | なし |
| gpt-neo | 1.3b | FP16 | AdaFactor | 2048 | 4 | GradCheckpoint |
| gpt-neo | 2.7b | FP16 | AdaFactor | 2048 | 4 | GradCheckpoint、凍結式 |
単一のRTX 3090(24GB)カード(ディープスピードなし)でトレーニングできるようにテストされたいくつかのT5構成:
| モデル | パラメージ | 精度 | オプティマイザ | seq2seqlen | バッチサイズ | 他の |
|---|---|---|---|---|---|---|
| T5 | 3b | FP32 | AdaFactor | 128-> 128 | 1 | フリーズベッド |
| T5 | 3b | FP32 | AdaFactor | 128-> 128 | 1 | GradCheckpoint |
| T5 | 3b | FP32 | AdaFactor | 128-> 128 | 128 | GradCheckpoint、凍結式 |
| T5 | 3b | FP32 | AdaFactor | 512-> 512 | 32 | GradCheckpoint、凍結式 |
T5-11Bモデルのモデル並列性
このライブラリを使用すると、T5-11Bチェックポイントを次の設定(DeepSpeedなし)で非常に簡単に(単一ノード)微調整することもできます。
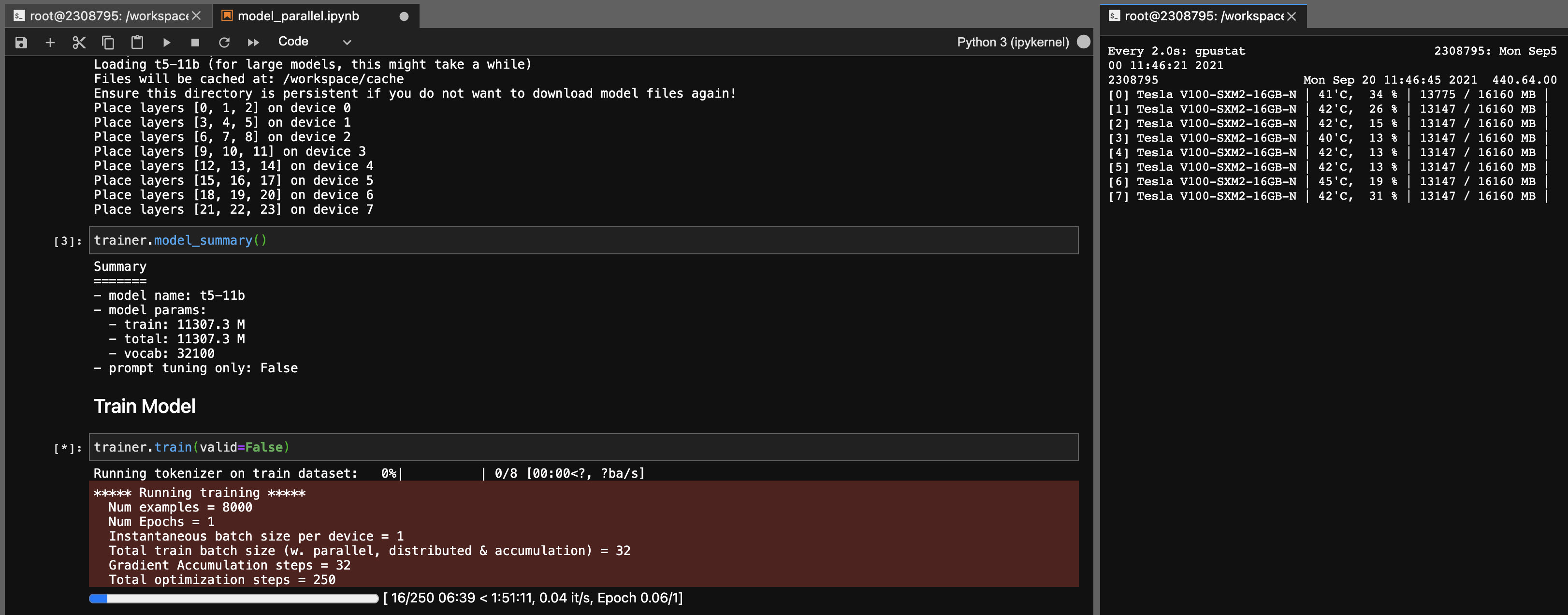
システムによっては、チェックポイント(46GB)の読み込み時間は非常に長くなる可能性があることに注意してください。正常にロードするには、十分なCPU RAM(少なくとも90GB)が必要です。
ONNX RTは、一部のモデル(T5ではなく)で動作し、速度がわずかにブーストを提供できます。
ORTをインストールしてから、 TrainingArguments.torch_ort=Trueを設定します
pip install torch-ort -f https://onnxruntimepackages.z14.web.core.windows.net/onnxruntime_stable_torch190.cu111.html
python -m torch_ort.configure建物パッケージ
python3 -m pip install --upgrade build twine
python3 -m build
python3 -m twine upload dist/ * 私自身の使用のための個人的なプロジェクトとして開発されたこのライブラリ。お気軽にフォークするか、自分の目的にも使用してください。私は、この図書館の使用の結果として発生する事故に責任を負いません。
3090 FE Cardsの注。ファンが100%ヒットした場合、VRAM温度が高い(> 100 deg C)を意味します。理論のこれらの温度での長時間のトレーニングは問題ありませんが、心の安心(私のように)が必要な場合は、トレーニング速度にわずかな影響を与える電力制限を下げることができます。ファンが100%に達していない限り、VRAMの温度は良いはずです。たとえば、電力制限を300W(350Wから)に減らすには:
sudo nvidia-smi -pl 300

