t2t tuner
1.0.0
변압기를위한 편리한 텍스트-텍스트 교육
pip install t2t-tunerPytorch 필요 : Pytorch 설치 지침을 따르거나 Pytorch 컨테이너를 사용하십시오.
멋진 Huggingface Transformers 라이브러리를 기반으로합니다. T5 및 GPT 유형의 모델에서 테스트되었습니다. 이론적으로는 Automodelforseq2seqlm 또는 AutomodElforcausallm을 지원하는 다른 모델과도 작동해야합니다.
이 라이브러리의 트레이너는 텍스트-텍스트 생성 작업을위한 huggingface의 run_translation.py 스크립트를 기반으로하는 더 높은 레벨 인터페이스입니다. 나는 더 큰 모델에 맞는 그라디언트 체크 포인팅 및 모델과 같은 모델에 대한 액세스와 함께 훈련 및 추론을위한보다 편리한 인터페이스를 원한다고 결정했습니다. 이들은 이미 Huggingface 라이브러리에 있지만 스크립트에 노출되지 않았습니다. 또한 원하는 기능 (프롬프트 튜닝, 모델 요약)을 추가하고 자동 회귀 LM 교육과 통합하여 PIP 설치할 수있는 단일 라이브러리로 포장했습니다.
import t2t
trainer_arguments = t2t . TrainerArguments ( model_name_or_path = "t5-small" ,
train_file = YOUR_DATASET )
trainer = t2t . Trainer ( arguments = trainer_arguments )
# train without validation
trainer . train ( valid = False )더 구체적인 예를 보려면 아래 링크 된 노트북을 확인하십시오.
SEQ2SEQ 교육
{ "translation" : { "s" : " TEXT " , "t" : " LABEL " }}TrainingArguments.source_id 및 TrainingArguments.target_id 에서 소스 및 대상 ID를 정의하십시오 (기본값으로 s 및 t ).TrainingArguments.prefix 에서 텍스트로 Prepend 접두사를 정의하십시오.자동 회귀 LM 훈련
이 섹션에서는 비교적 간단한 설정에서 대형 언어 모델 (> 1 bil 매개 변수)을 훈련시키는 방법을 개괄합니다.
아래에보고 된 구성에 대한 몇 가지 메모는 다음과 같습니다.
TrainerArguments.gradient_checkpointing 세트).trainer.freeze(embeddings=True) ).TrainingArguments.gradient_accumulation_steps )을 사용하여 필요한 경우 더 큰 배치 크기를 구성 할 수 있습니다. 보고 된 배치 크기는 그라디언트 축적이 없습니다 .단일 RTX 3090 (24GB) 카드를 훈련시킬 수 있도록 테스트 된 일부 GPT 구성 (DeepSpeed없이) :
| 모델 | 매개 변수 | 정도 | 최적화 | 입력 | 배치 크기 | 다른 |
|---|---|---|---|---|---|---|
| GPT2 | 1.5b | FP16 | 아파 팩터 | 128 | 4 | 없음 |
| GPT2 | 1.5b | FP16 | 아파 팩터 | 512 | 1 | 없음 |
| GPT2 | 1.5b | FP16 | 아파 팩터 | 1024 | 4 | GradCheckPoint |
| gpt-neo | 1.3b | FP16 | 아파 팩터 | 1024 | 1 | 없음 |
| gpt-neo | 1.3b | FP16 | 아파 팩터 | 2048 | 4 | GradCheckPoint |
| gpt-neo | 2.7b | FP16 | 아파 팩터 | 2048 | 4 | Gradcheckpoint, Freezeembeds |
단일 RTX 3090 (24GB) 카드 (DeepSpeed없이)를 훈련시킬 수 있도록 테스트 된 일부 T5 구성 :
| 모델 | 매개 변수 | 정도 | 최적화 | seq2seqlen | 배치 크기 | 다른 |
|---|---|---|---|---|---|---|
| T5 | 3B | FP32 | 아파 팩터 | 128-> 128 | 1 | 동결 |
| T5 | 3B | FP32 | 아파 팩터 | 128-> 128 | 1 | GradCheckPoint |
| T5 | 3B | FP32 | 아파 팩터 | 128-> 128 | 128 | Gradcheckpoint, Freezeembeds |
| T5 | 3B | FP32 | 아파 팩터 | 512-> 512 | 32 | Gradcheckpoint, Freezeembeds |
T5-11B 모델에 대한 모델 병렬 처리
이 라이브러리를 사용하면 다음 설정 (DeepSpeed없이)으로 T5-11B 체크 포인트를 아주 쉽게 (단일 노드) 미세 조정할 수 있습니다.
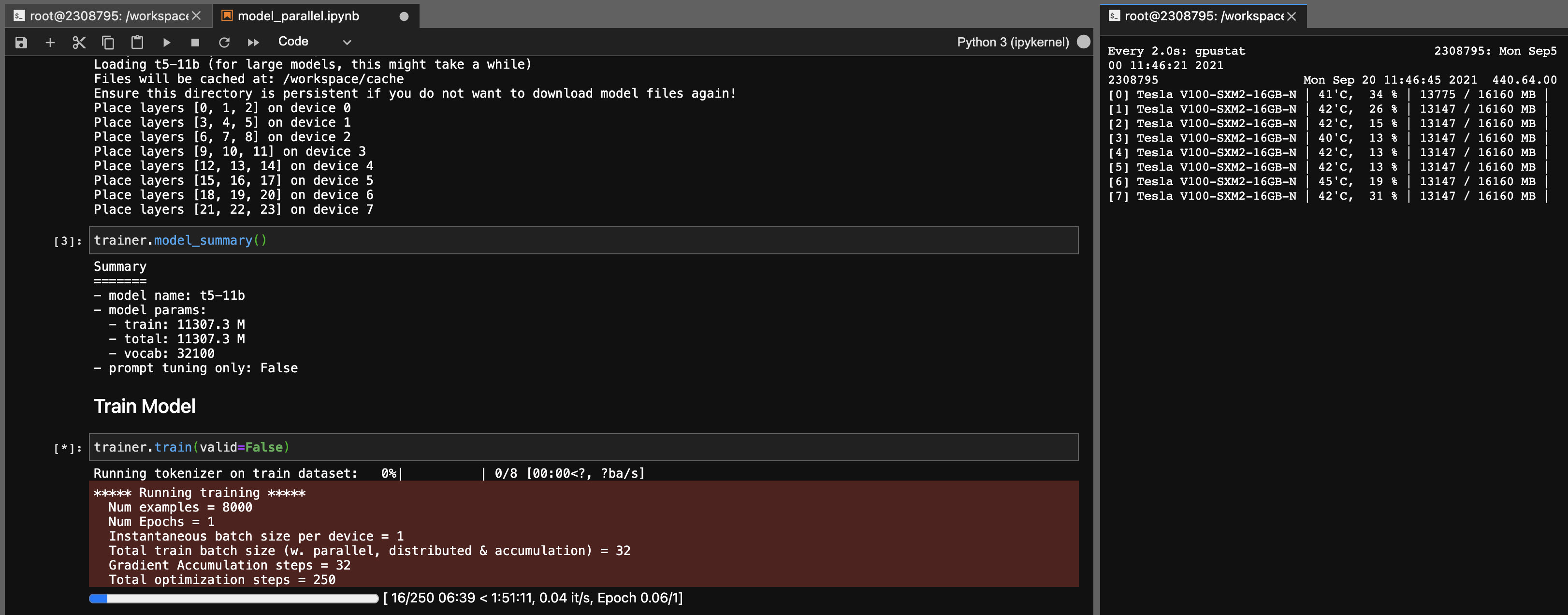
시스템에 따라 체크 포인트 (46GB)의 로딩 시간이 매우 길을 수 있습니다. 성공적으로로드하려면 충분한 CPU RAM (~ 90GB 이상)이 필요합니다.
Onnx RT는 일부 모델 (아직 T5가 아님)에서 작동하며 속도가 약간 높아질 수 있습니다.
ort를 설치 한 다음 TrainingArguments.torch_ort=True 설정하십시오
pip install torch-ort -f https://onnxruntimepackages.z14.web.core.windows.net/onnxruntime_stable_torch190.cu111.html
python -m torch_ort.configure건물 패키지
python3 -m pip install --upgrade build twine
python3 -m build
python3 -m twine upload dist/ * 이 라이브러리는 저의 사용을위한 개인 프로젝트로 개발되었습니다. 자신의 목적을 위해 자유롭게 포크하거나 사용하십시오. 이 라이브러리의 사용으로 인해 발생하는 사고에 대해서는 책임을지지 않습니다.
참고 3090 FE 카드의 경우 팬이 100%에 도달하면 VRAM 온도가 높음 (> 100 ℃)을 의미합니다. 이론적 으로이 온도에서 오랜 시간 동안 훈련하는 것은 괜찮을 것이지만, 나와 같은 마음의 평화를 원한다면, 당신은 훈련 속도에 약간의 영향을 미치는 전력 제한을 낮출 수 있습니다. 팬이 100%에 도달하지 않는 한 VRAM 온도가 좋을 것입니다. 예를 들어, 전력 제한을 300W로 낮추기 위해 (350W에서) :
sudo nvidia-smi -pl 300

