t2t tuner
1.0.0
Treinamento conveniente de texto para texto para transformadores
pip install t2t-tunerRequer Pytorch: siga as instruções de instalação do Pytorch ou use um contêiner Pytorch.
Baseado na maravilhosa biblioteca de Transformers Huggingface. Testado em modelos T5 e GPT. Em teoria, deve funcionar com outros modelos que suportam o AutomodelForseq2Seqlm ou o AutomodelCorcausAllm também.
O treinador nesta biblioteca aqui está uma interface de nível superior para funcionar com base nas scripts Run_translation.py do Huggingface para tarefas de geração de texto em texto. Decidi que quero uma interface mais conveniente para treinamento e inferência, juntamente com o acesso a coisas como verificação de gradiente e modelo paralelo para encaixar modelos maiores - eles já estão na biblioteca Huggingface, mas não expostos no script. Eu também adicionei alguns recursos que eu queria (ajuste rápido, resumo do modelo), o integrava ao treinamento de LM autoregressivo e o embrulhei como uma única biblioteca que pode ser instalada PIP.
import t2t
trainer_arguments = t2t . TrainerArguments ( model_name_or_path = "t5-small" ,
train_file = YOUR_DATASET )
trainer = t2t . Trainer ( arguments = trainer_arguments )
# train without validation
trainer . train ( valid = False )Para exemplos mais concretos, consulte os notebooks vinculados abaixo:
Treinamento SEQ2SEQ
{ "translation" : { "s" : " TEXT " , "t" : " LABEL " }}TrainingArguments.source_id e TrainingArguments.target_id (Padrões para s e t ).TrainingArguments.prefix .Treinamento autoregressivo de LM
Esta seção descreverá como treinar grandes modelos de idiomas (> 1 parâmetros BIL) em configurações relativamente simples.
Algumas notas para as configurações relatadas abaixo:
TrainerArguments.gradient_checkpointing ).trainer.freeze(embeddings=True) ).TrainingArguments.gradient_accumulation_steps ) para compensar um tamanho de lote maior, se necessário. Os tamanhos do lote relatados não têm acumulação de gradiente.Algumas configurações GPT que foram testadas para poder treinar em um único cartão RTX 3090 (24 GB) (sem velocidade profunda):
| Modelo | Params | Precisão | Otimizador | Inputlen | BatchSize | Outro |
|---|---|---|---|---|---|---|
| GPT2 | 1.5b | FP16 | Adafactor | 128 | 4 | Nenhum |
| GPT2 | 1.5b | FP16 | Adafactor | 512 | 1 | Nenhum |
| GPT2 | 1.5b | FP16 | Adafactor | 1024 | 4 | Gradcheckpoint |
| GPT-Neo | 1.3b | FP16 | Adafactor | 1024 | 1 | Nenhum |
| GPT-Neo | 1.3b | FP16 | Adafactor | 2048 | 4 | Gradcheckpoint |
| GPT-Neo | 2.7b | FP16 | Adafactor | 2048 | 4 | Gradcheckpoint, congelamento |
Algumas configurações T5 que foram testadas para poder treinar em um único cartão RTX 3090 (24 GB) (sem velocidade DeepSpeed):
| Modelo | Params | Precisão | Otimizador | SEQ2SEQLEN | BatchSize | Outro |
|---|---|---|---|---|---|---|
| T5 | 3b | Fp32 | Adafactor | 128-> 128 | 1 | Congelados |
| T5 | 3b | Fp32 | Adafactor | 128-> 128 | 1 | Gradcheckpoint |
| T5 | 3b | Fp32 | Adafactor | 128-> 128 | 128 | Gradcheckpoint, congelamento |
| T5 | 3b | Fp32 | Adafactor | 512-> 512 | 32 | Gradcheckpoint, congelamento |
Paralelismo do modelo para modelos T5-11b
Usando esta biblioteca, você também pode ajustar os pontos de verificação T5-11B com bastante facilidade (nó único) com as seguintes configurações (sem velocidade profunda):
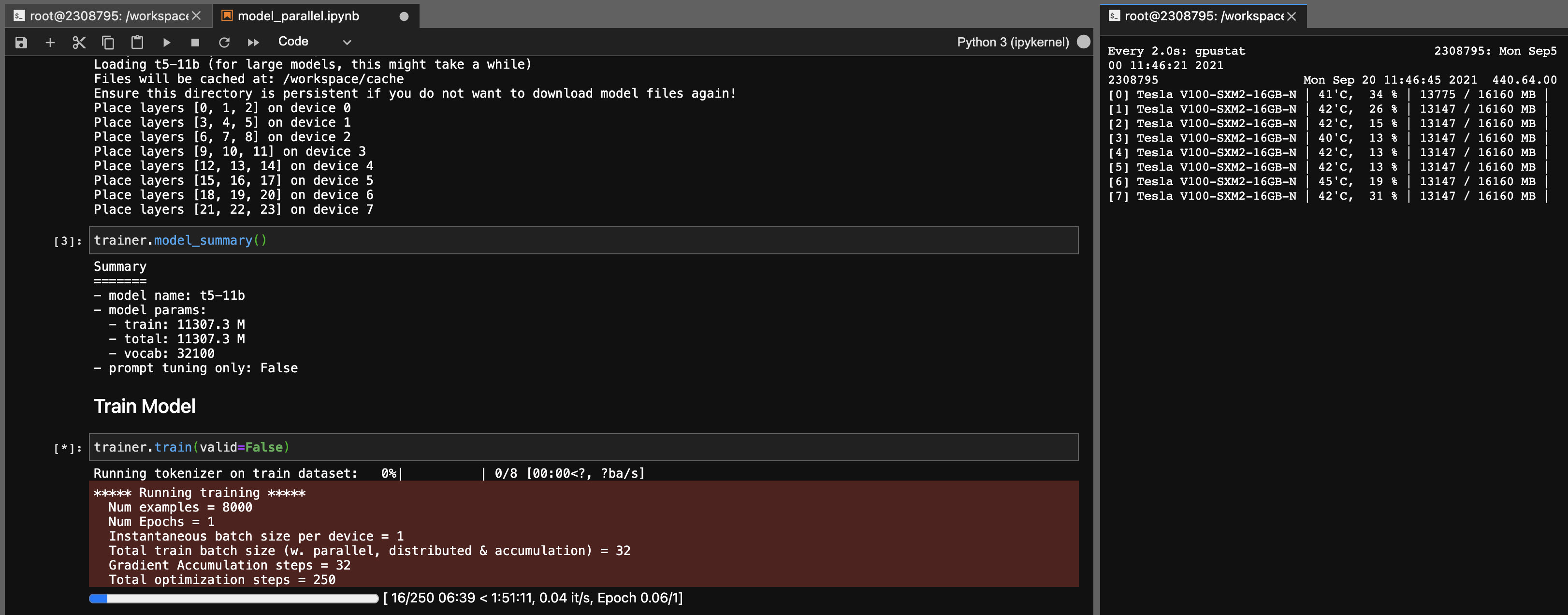
Observe que, dependendo do seu sistema, o tempo de carregamento para o ponto de verificação (46 GB) pode ser muito longo. Você precisará de uma ampla RAM da CPU (pelo menos ~ 90 GB) para carregá -la com sucesso.
O Onnx RT funciona com alguns modelos (ainda não T5) e pode fornecer um pequeno impulso na velocidade.
Instale o ORT e defina TrainingArguments.torch_ort=True
pip install torch-ort -f https://onnxruntimepackages.z14.web.core.windows.net/onnxruntime_stable_torch190.cu111.html
python -m torch_ort.configurePacote de construção
python3 -m pip install --upgrade build twine
python3 -m build
python3 -m twine upload dist/ * Esta biblioteca desenvolveu como um projeto pessoal para meu próprio uso. Por favor, sinta -se à vontade para bifurcar ou usá -lo para seus próprios propósitos também. Não assumirei a responsabilidade por contratempos que ocorram como resultado do uso desta biblioteca.
Nota para os cartões de 3090 FE, se seus fãs atingirem 100%, significa que suas temperaturas VRAM são altas (> 100 graus C). O treinamento por longas horas nessas temperaturas em teoria deve ser bom, mas se você quiser uma paz de espírito (como eu), pode diminuir o limite de potência incorrer um impacto menor nas velocidades de treinamento. Enquanto seus fãs nunca atingirem 100%, as temperaturas de VRAM devem ser boas. Por exemplo, para reduzir o limite de potência para 300W (de 350W):
sudo nvidia-smi -pl 300

