t2t tuner
1.0.0
变压器方便的文本到文本培训
pip install t2t-tuner需要Pytorch:遵循Pytorch安装说明或使用Pytorch容器。
基于精美的拥抱面库。在T5和GPT类型的模型上测试。从理论上讲,它应该与支持AutomodelForseq2Seqlm或AutomodelForCausAllm的其他模型一起使用。
此库中的培训师是一个更高级别的接口,可以根据huggingface的run_translation.py脚本进行文本到文本生成任务的脚本工作。我决定我想要一个更方便的界面,用于培训和推断,以及访问诸如梯度检查点和平行模型之类的东西,以适合较大的型号 - 这些已经在HuggingFace库中,但在脚本中不曝光。我还添加了一些我想要的功能(及时调整,型号摘要),将其与自回归的LM培训集成在一起,并将其包裹为可以安装PIP的单个库。
import t2t
trainer_arguments = t2t . TrainerArguments ( model_name_or_path = "t5-small" ,
train_file = YOUR_DATASET )
trainer = t2t . Trainer ( arguments = trainer_arguments )
# train without validation
trainer . train ( valid = False )有关更多具体示例,请查看以下链接的笔记本:
SEQ2SEQ培训
{ "translation" : { "s" : " TEXT " , "t" : " LABEL " }}TrainingArguments.source_id和TrainingArguments.target_id中定义源ID和目标ID(默认为s和t )。TrainingArguments.prefix中预先添加到文本。自回旋LM培训
本节将概述如何在相对简单的设置上训练大型语言模型(> 1个BIL参数)。
有关以下报告的配置的一些注释:
TrainerArguments.gradient_checkpointing )。trainer.freeze(embeddings=True) )。TrainingArguments.gradient_accumulation_steps )来弥补较大的批量大小,如果需要。报告的批次大小没有梯度积累。一些GPT配置已测试,以便能够在单个RTX 3090(24GB)卡上训练(无deepspeed):
| 模型 | 参数 | 精确 | 优化器 | 输入 | 批处理 | 其他 |
|---|---|---|---|---|---|---|
| GPT2 | 1.5b | FP16 | afactor | 128 | 4 | 没有任何 |
| GPT2 | 1.5b | FP16 | afactor | 512 | 1 | 没有任何 |
| GPT2 | 1.5b | FP16 | afactor | 1024 | 4 | gradcheckpoint |
| gpt-neo | 1.3b | FP16 | afactor | 1024 | 1 | 没有任何 |
| gpt-neo | 1.3b | FP16 | afactor | 2048 | 4 | gradcheckpoint |
| gpt-neo | 2.7b | FP16 | afactor | 2048 | 4 | gradcheckpoint,冻结 |
一些T5配置已测试以在单个RTX 3090(24GB)卡上进行训练(无deepspeed):
| 模型 | 参数 | 精确 | 优化器 | seq2seqlen | 批处理 | 其他 |
|---|---|---|---|---|---|---|
| T5 | 3b | fp32 | afactor | 128-> 128 | 1 | 冻结 |
| T5 | 3b | fp32 | afactor | 128-> 128 | 1 | gradcheckpoint |
| T5 | 3b | fp32 | afactor | 128-> 128 | 128 | gradcheckpoint,冻结 |
| T5 | 3b | fp32 | afactor | 512-> 512 | 32 | gradcheckpoint,冻结 |
T5-11b模型的模型并行性
使用此库,您还可以轻松地(单节点)轻松地调整T5-11b检查点(无需深速):
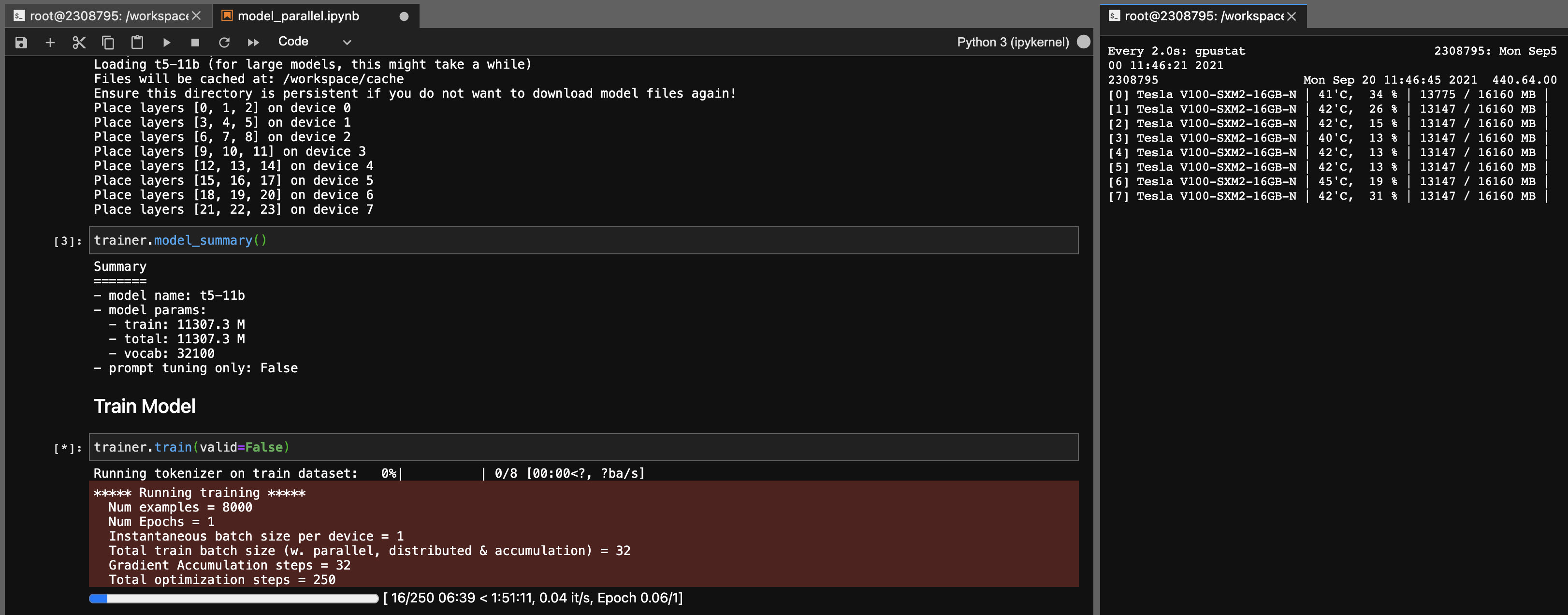
请注意,根据您的系统,检查点(46GB)的加载时间可能很长。您需要大量的CPU RAM(至少〜90GB)才能成功加载它。
ONNX RT与某些型号(不是T5)一起使用,并且可以提供较小的速度提升。
安装ORT,然后设置TrainingArguments.torch_ort=True
pip install torch-ort -f https://onnxruntimepackages.z14.web.core.windows.net/onnxruntime_stable_torch190.cu111.html
python -m torch_ort.configure建筑包
python3 -m pip install --upgrade build twine
python3 -m build
python3 -m twine upload dist/ * 这个图书馆是作为我自己使用的个人项目开发的。请随意叉子或将其用于您自己的目的。由于该图书馆的使用情况,我不会对发生的任何不幸负责。
注意3090 fe卡,如果您的粉丝达到100%,则意味着您的VRAM温度很高(> 100度C)。从理论上讲,在这些温度下长时间的训练应该很好,但是如果您想放心(像我一样),则可以降低功率上限对训练速度产生较小的影响。只要您的粉丝从未达到100%,您的VRAM温度就应该很好。例如,将功率限制降至300W(从350W):
sudo nvidia-smi -pl 300

