t2t tuner
1.0.0
การฝึกอบรมข้อความเป็นข้อความที่สะดวกสำหรับหม้อแปลง
pip install t2t-tunerต้องใช้ Pytorch: ทำตามคำแนะนำการติดตั้ง Pytorch หรือใช้คอนเทนเนอร์ Pytorch
ขึ้นอยู่กับห้องสมุด Transformers HuggingFace ที่ยอดเยี่ยม ทดสอบกับรุ่น T5 และ GPT ในทางทฤษฎีมันควรทำงานร่วมกับรุ่นอื่น ๆ ที่รองรับ AutomodelForSeq2Seqlm หรือ AutomodelForCausAllm เช่นกัน
ผู้ฝึกสอนในห้องสมุดนี้ที่นี่เป็นอินเทอร์เฟซระดับที่สูงขึ้นในการทำงานตาม Run_translation.py ของ HuggingFace สำหรับงานสร้างข้อความเป็นข้อความ ฉันตัดสินใจว่าฉันต้องการอินเทอร์เฟซที่สะดวกยิ่งขึ้นสำหรับการฝึกอบรมและการอนุมานพร้อมกับการเข้าถึงสิ่งต่าง ๆ เช่นจุดตรวจการไล่ระดับสีและแบบจำลองขนานเพื่อให้พอดีกับรุ่นที่ใหญ่กว่า - สิ่งเหล่านี้อยู่ในไลบรารี HuggingFace แต่ไม่ได้เปิดเผยในสคริปต์ ฉันยังเพิ่มในคุณสมบัติบางอย่างที่ฉันต้องการ (การปรับจูนการสรุปแบบจำลอง) รวมเข้ากับการฝึกอบรม LM แบบอัตโนมัติและห่อเป็นไลบรารีเดียวที่สามารถติดตั้ง PIP ได้
import t2t
trainer_arguments = t2t . TrainerArguments ( model_name_or_path = "t5-small" ,
train_file = YOUR_DATASET )
trainer = t2t . Trainer ( arguments = trainer_arguments )
# train without validation
trainer . train ( valid = False )สำหรับตัวอย่างที่เป็นรูปธรรมเพิ่มเติมลองดูสมุดบันทึกที่เชื่อมโยงด้านล่าง:
การฝึกอบรม SEQ2SEQ
{ "translation" : { "s" : " TEXT " , "t" : " LABEL " }}TrainingArguments.source_id และ TrainingArguments.target_id (ค่าเริ่มต้นเป็น s และ t )TrainingArguments.prefixการฝึก LM อัตโนมัติ
ส่วนนี้จะร่างวิธีการฝึกอบรมแบบจำลองภาษาขนาดใหญ่ (> 1 พารามิเตอร์ bil) ในการตั้งค่าที่ค่อนข้างง่าย
บันทึกบางอย่างสำหรับการกำหนดค่าที่รายงานด้านล่าง:
TrainerArguments.gradient_checkpointing )trainer.freeze(embeddings=True) )TrainingArguments.gradient_accumulation_steps ) เพื่อสร้างขนาดแบทช์ที่ใหญ่กว่าหากจำเป็น ขนาดแบทช์ที่รายงานโดย ไม่มี การสะสมการไล่ระดับสีการกำหนดค่า GPT บางอย่างที่ทดสอบเพื่อฝึกการ์ด RTX 3090 (24GB) เดียว (ไม่มี DeepSpeed):
| แบบอย่าง | พารามิเตอร์ | ความแม่นยำ | การเพิ่มประสิทธิภาพ | อินพุต | batchsize | อื่น |
|---|---|---|---|---|---|---|
| GPT2 | 1.5B | FP16 | เครื่องดื่ม | 128 | 4 | ไม่มี |
| GPT2 | 1.5B | FP16 | เครื่องดื่ม | 512 | 1 | ไม่มี |
| GPT2 | 1.5B | FP16 | เครื่องดื่ม | 1024 | 4 | Gradcheckpoint |
| Gpt-neo | 1.3b | FP16 | เครื่องดื่ม | 1024 | 1 | ไม่มี |
| Gpt-neo | 1.3b | FP16 | เครื่องดื่ม | 2048 | 4 | Gradcheckpoint |
| Gpt-neo | 2.7B | FP16 | เครื่องดื่ม | 2048 | 4 | Gradcheckpoint, freezeembeds |
การกำหนดค่า T5 บางตัวที่ทดสอบเพื่อฝึกการ์ด RTX 3090 (24GB) เดียว (ไม่มี DeepSpeed):
| แบบอย่าง | พารามิเตอร์ | ความแม่นยำ | การเพิ่มประสิทธิภาพ | seq2seqlen | batchsize | อื่น |
|---|---|---|---|---|---|---|
| T5 | 3B | fp32 | เครื่องดื่ม | 128-> 128 | 1 | freezeembeds |
| T5 | 3B | fp32 | เครื่องดื่ม | 128-> 128 | 1 | Gradcheckpoint |
| T5 | 3B | fp32 | เครื่องดื่ม | 128-> 128 | 128 | Gradcheckpoint, freezeembeds |
| T5 | 3B | fp32 | เครื่องดื่ม | 512-> 512 | 32 | Gradcheckpoint, freezeembeds |
แบบจำลองความเท่าเทียมสำหรับรุ่น T5-11B
การใช้ไลบรารีนี้คุณสามารถปรับจุดตรวจ T5-11B ได้อย่างง่ายดาย (โหนดเดี่ยว) ด้วยการตั้งค่าต่อไปนี้ (โดยไม่ต้องลึก):
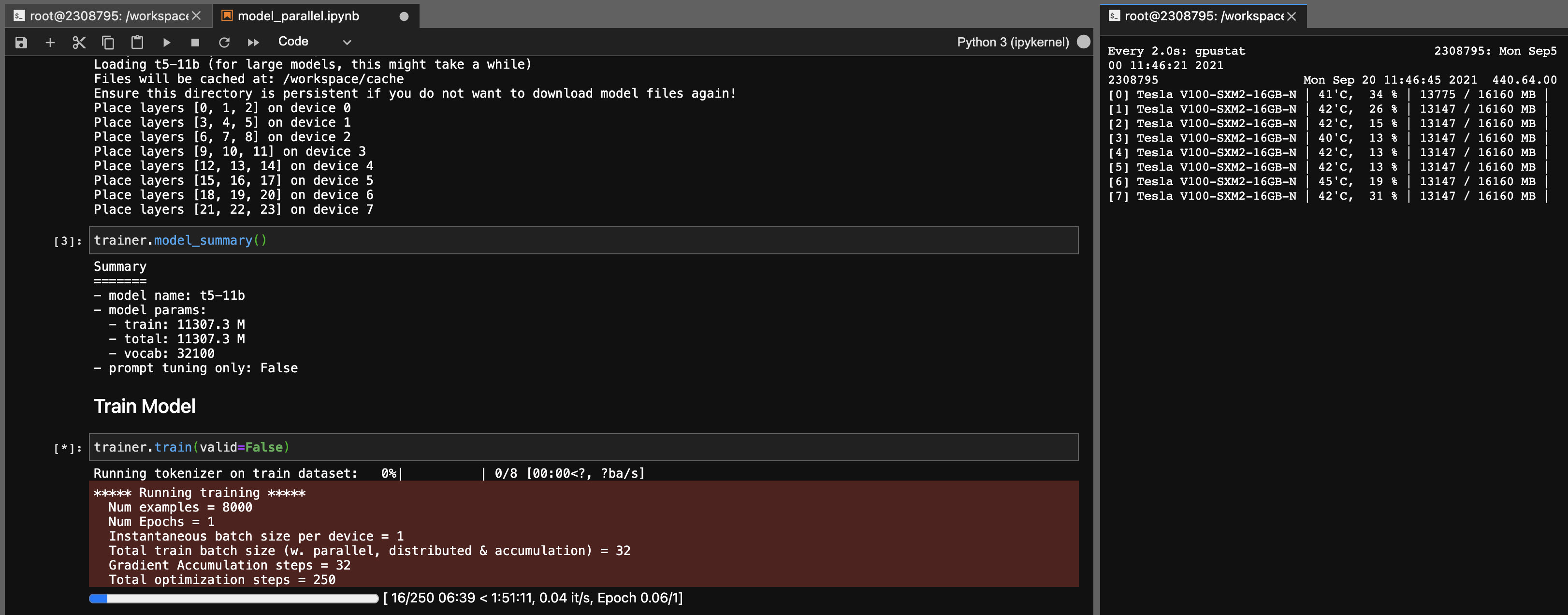
โปรดทราบว่าขึ้นอยู่กับระบบของคุณเวลาในการโหลดสำหรับจุดตรวจ (46GB) อาจยาวมาก คุณจะต้องใช้ CPU RAM ที่เพียงพอ (อย่างน้อย ~ 90GB) เพื่อโหลดได้สำเร็จ
ONNX RT ทำงานร่วมกับบางรุ่น (ไม่ใช่ T5 แต่) และสามารถเพิ่มความเร็วในการเพิ่มขึ้นเล็กน้อย
ติดตั้ง ORT จากนั้นตั้งค่า TrainingArguments.torch_ort=True
pip install torch-ort -f https://onnxruntimepackages.z14.web.core.windows.net/onnxruntime_stable_torch190.cu111.html
python -m torch_ort.configureแพ็คเกจอาคาร
python3 -m pip install --upgrade build twine
python3 -m build
python3 -m twine upload dist/ * ห้องสมุดนี้พัฒนาเป็นโครงการส่วนบุคคลสำหรับการใช้งานของฉันเอง โปรดอย่าลังเลที่จะแยกหรือใช้เพื่อจุดประสงค์ของคุณเองเช่นกัน ฉันจะไม่รับผิดชอบต่อความผิดพลาดใด ๆ ที่เกิดขึ้นอันเป็นผลมาจากการใช้งานของห้องสมุดนี้
หมายเหตุสำหรับการ์ด 3090 FE หากแฟน ๆ ของคุณตี 100%หมายความว่าอุณหภูมิ VRAM ของคุณสูง (> 100 องศาเซลเซียส) การฝึกอบรมเป็นเวลานานที่อุณหภูมิเหล่านี้ในทางทฤษฎีน่าจะดี แต่ถ้าคุณต้องการความอุ่นใจ (เช่นฉัน) คุณสามารถลดขีด จำกัด พลังงานที่มีผลกระทบเล็กน้อยต่อความเร็วในการฝึกอบรม ตราบใดที่แฟน ๆ ของคุณไม่เคยตี 100%อุณหภูมิ VRAM ของคุณก็ควรจะดี ตัวอย่างเช่นเพื่อลดขีด จำกัด พลังงานเป็น 300W (จาก 350W):
sudo nvidia-smi -pl 300

