t2t tuner
1.0.0
Удобное обучение текста в тексте для трансформаторов
pip install t2t-tunerТребуется Pytorch: либо следуйте инструкциям по установке Pytorch, либо используйте контейнер Pytorch.
Основана на замечательной библиотеке Transformers Transformers. Протестировано на моделях T5 и GPT. Теоретически, он должен работать с другими моделями, которые также поддерживают Automodelforseq2seqlm или Automodelforcausallm.
Тренер в этой библиотеке здесь представляет собой интерфейс более высокого уровня для работы на основе скрипта run_translation.py от run_translation.py для задач генерации текста в текст. Я решил, что хочу более удобный интерфейс для обучения и вывода, а также доступ к таким вещам, как градиент контрольно -пропускной пункт и модели, параллельная для размещения более крупных моделей - они уже находятся в библиотеке Huggingface, но не открыты в сценарии. Я также добавил в некоторые функции, которые я хотел (приглашенная настройка, краткое изложение модели), интегрировал его с авторегрессивным обучением LM и завершил его как одну библиотеку, которая может быть установлена.
import t2t
trainer_arguments = t2t . TrainerArguments ( model_name_or_path = "t5-small" ,
train_file = YOUR_DATASET )
trainer = t2t . Trainer ( arguments = trainer_arguments )
# train without validation
trainer . train ( valid = False )Для получения более конкретных примеров, посмотрите записные книжки, связанные ниже:
SEQ2SEQ Training
{ "translation" : { "s" : " TEXT " , "t" : " LABEL " }}TrainingArguments.source_id и TrainingArguments.target_id (по умолчанию s и t ).TrainingArguments.prefix .Ауторегрессивное обучение LM
В этом разделе будет описано, как обучать большие языковые модели (> 1 параметры BIL) на относительно простые настройки.
Некоторые примечания для конфигураций, представленных ниже:
TrainerArguments.gradient_checkpointing ).trainer.freeze(embeddings=True) ).TrainingArguments.gradient_accumulation_steps ), чтобы при необходимости составить больший размер партии. Размеры партий, о которых сообщается, без накопления градиента.Некоторые конфигурации GPT, которые были протестированы на возможность обучения на одной карте RTX 3090 (24 ГБ) (без DeepSpeed):
| Модель | Параметры | Точность | Оптимизатор | Inputlen | Партия | Другой |
|---|---|---|---|---|---|---|
| GPT2 | 1,5B | FP16 | Адафактор | 128 | 4 | Никто |
| GPT2 | 1,5B | FP16 | Адафактор | 512 | 1 | Никто |
| GPT2 | 1,5B | FP16 | Адафактор | 1024 | 4 | Gradcheckpoint |
| GPT-neo | 1.3b | FP16 | Адафактор | 1024 | 1 | Никто |
| GPT-neo | 1.3b | FP16 | Адафактор | 2048 | 4 | Gradcheckpoint |
| GPT-neo | 2.7b | FP16 | Адафактор | 2048 | 4 | Gradcheckpoint, Freezeembeds |
Некоторые конфигурации T5, которые были протестированы на возможность обучения на одной карте RTX 3090 (24 ГБ) (без DeepSpeed):
| Модель | Параметры | Точность | Оптимизатор | Seq2seqlen | Партия | Другой |
|---|---|---|---|---|---|---|
| T5 | 3B | FP32 | Адафактор | 128-> 128 | 1 | Freezeembeds |
| T5 | 3B | FP32 | Адафактор | 128-> 128 | 1 | Gradcheckpoint |
| T5 | 3B | FP32 | Адафактор | 128-> 128 | 128 | Gradcheckpoint, Freezeembeds |
| T5 | 3B | FP32 | Адафактор | 512-> 512 | 32 | Gradcheckpoint, Freezeembeds |
Модель параллелизма для моделей T5-11B
Используя эту библиотеку, вы также можете легко настроить контрольные точки T5-11B (один узел) со следующими настройками (без DeepSpeed):
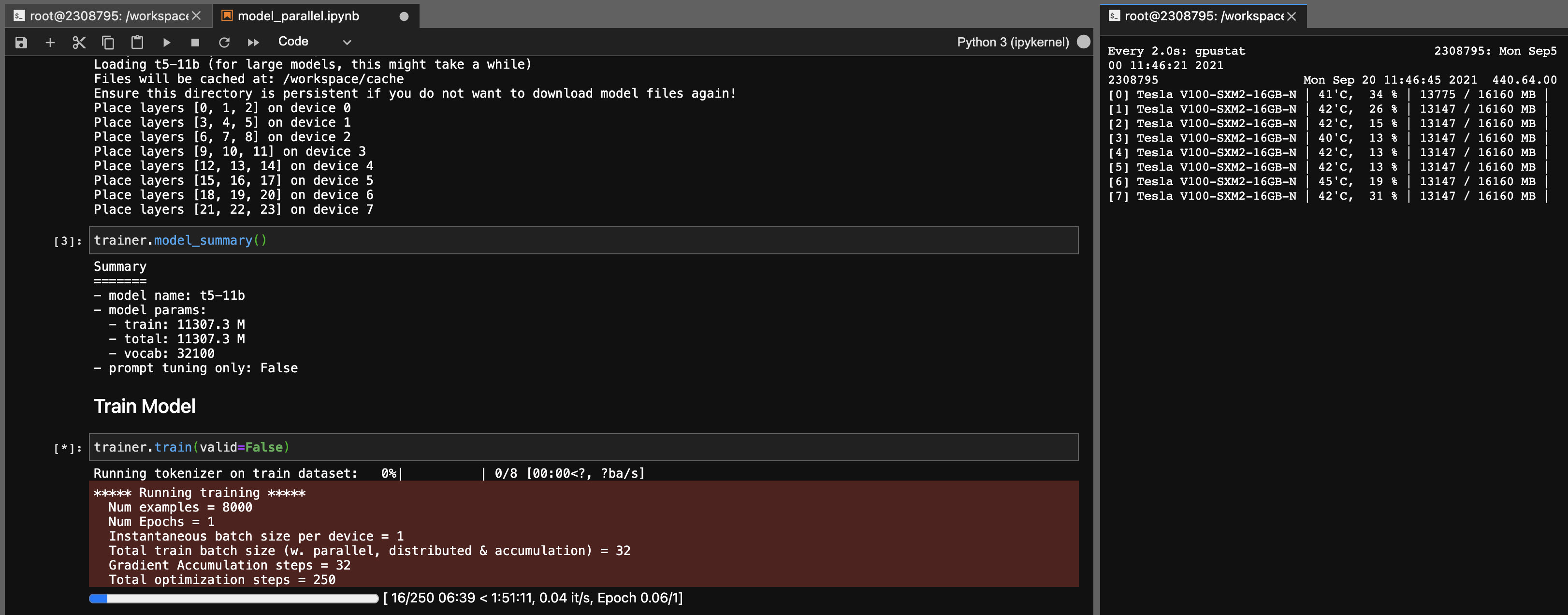
Обратите внимание, что в зависимости от вашей системы время загрузки для контрольной точки (46 ГБ) может быть очень длинным. Вам понадобится достаточная оперативная память CPU (не менее ~ 90 ГБ), чтобы успешно загрузить его.
Onnx RT работает с некоторыми моделями (а не T5) и может обеспечить небольшой импульс скорости.
Установите ORT, затем установите TrainingArguments.torch_ort=True
pip install torch-ort -f https://onnxruntimepackages.z14.web.core.windows.net/onnxruntime_stable_torch190.cu111.html
python -m torch_ort.configureСтроительный пакет
python3 -m pip install --upgrade build twine
python3 -m build
python3 -m twine upload dist/ * Эта библиотека, разработанная как личный проект для моего собственного использования. Пожалуйста, не стесняйтесь вилка или используйте ее и для своих собственных целей. Я не буду нести ответственность за любые неудачи, которые происходят в результате использования этой библиотеки.
Примечание для карт 3090 FE, если ваши поклонники достигли 100%, это означает, что ваши временные температуры VRAM высоки (> 100 градусов C). Тренировка в течение долгих часов по этим температурам в теории должно быть в порядке, но если вы хотите душевного спокойствия (как и я), вы можете снизить предел власти, оказывая незначительное влияние на скорость тренировок. Пока ваши поклонники никогда не достигают 100%, ваши температуры VRAM должны быть хорошими. Например, для снижения предела мощности до 300 Вт (от 350 Вт):
sudo nvidia-smi -pl 300

