t2t tuner
1.0.0
تدريب مريح نص إلى النص للمحولات
pip install t2t-tunerيتطلب Pytorch: إما اتبع تعليمات تثبيت Pytorch أو استخدم حاوية Pytorch.
استنادا إلى مكتبة المحولات Huggingface الرائعة. تم اختباره على نوع النماذج T5 و GPT. من الناحية النظرية ، يجب أن تعمل مع نماذج أخرى تدعم AutomodelforseQ2SeqLM أو Automodelforcausallm أيضًا.
يوجد المدرب في هذه المكتبة هنا واجهة مستوى أعلى للعمل على أساس البرنامج النصي Run_translation's Run_translation الخاص بـ HuggingFace لمهام توليد النص إلى نص. قررت أنني أريد واجهة أكثر ملاءمة للتدريب والاستدلال ، إلى جانب الوصول إلى أشياء مثل تحديد التدرج والنموذج الموازي لتناسب النماذج الأكبر - هذه موجودة بالفعل في مكتبة Huggingface ولكن لا تتعرض في البرنامج النصي. لقد أضفت أيضًا في بعض الميزات التي أردت (ضبط موجه ، ملخص النموذج) ، ودمجته مع تدريب LM التلقائي ولفه كمكتبة واحدة يمكن تثبيتها.
import t2t
trainer_arguments = t2t . TrainerArguments ( model_name_or_path = "t5-small" ,
train_file = YOUR_DATASET )
trainer = t2t . Trainer ( arguments = trainer_arguments )
# train without validation
trainer . train ( valid = False )لمزيد من الأمثلة الملموسة ، تحقق من دفاتر الملاحظات المرتبطة أدناه:
SEQ2SEQ التدريب
{ "translation" : { "s" : " TEXT " , "t" : " LABEL " }}t TrainingArguments.target_id في TrainingArguments.source_id sTrainingArguments.prefix .تدريب LM التلقائي
سيوضح هذا القسم كيفية تدريب نماذج اللغة الكبيرة (> 1 معلمات BIL) على إعدادات بسيطة نسبيًا.
بعض الملاحظات للتكوينات الواردة أدناه:
TrainerArguments.gradient_checkpointing ).trainer.freeze(embeddings=True) ).TrainingArguments.gradient_accumulation_steps ) لتعقد حجم دفعة أكبر إذا لزم الأمر. أحجام الدُفعات المبلغ عنها بدون تراكم التدرج.بعض تكوينات GPT التي تم اختبارها لتمكنت من التدريب على بطاقة RTX 3090 (24 جيجابايت) (بدون سرعة عميقة):
| نموذج | params | دقة | مُحسّن | inputlen | BatchSize | آخر |
|---|---|---|---|---|---|---|
| GPT2 | 1.5 ب | FP16 | adafactor | 128 | 4 | لا أحد |
| GPT2 | 1.5 ب | FP16 | adafactor | 512 | 1 | لا أحد |
| GPT2 | 1.5 ب | FP16 | adafactor | 1024 | 4 | GradCheckPoint |
| GPT-NEO | 1.3 ب | FP16 | adafactor | 1024 | 1 | لا أحد |
| GPT-NEO | 1.3 ب | FP16 | adafactor | 2048 | 4 | GradCheckPoint |
| GPT-NEO | 2.7 ب | FP16 | adafactor | 2048 | 4 | GradCheckPoint ، تجميد |
بعض تكوينات T5 التي تم اختبارها لتمكنت من التدريب على بطاقة RTX 3090 (24 جيجابايت) (بدون سرعات عميقة):
| نموذج | params | دقة | مُحسّن | Seq2Seqlen | BatchSize | آخر |
|---|---|---|---|---|---|---|
| T5 | 3 ب | FP32 | adafactor | 128-> 128 | 1 | تجميد |
| T5 | 3 ب | FP32 | adafactor | 128-> 128 | 1 | GradCheckPoint |
| T5 | 3 ب | FP32 | adafactor | 128-> 128 | 128 | GradCheckPoint ، تجميد |
| T5 | 3 ب | FP32 | adafactor | 512-> 512 | 32 | GradCheckPoint ، تجميد |
نموذج التوازي لنماذج T5-11B
باستخدام هذه المكتبة ، يمكنك أيضًا ضبط نقاط التفتيش T5-11B بسهولة تامة (عقدة واحدة) مع الإعدادات التالية (بدون سرعة عميقة):
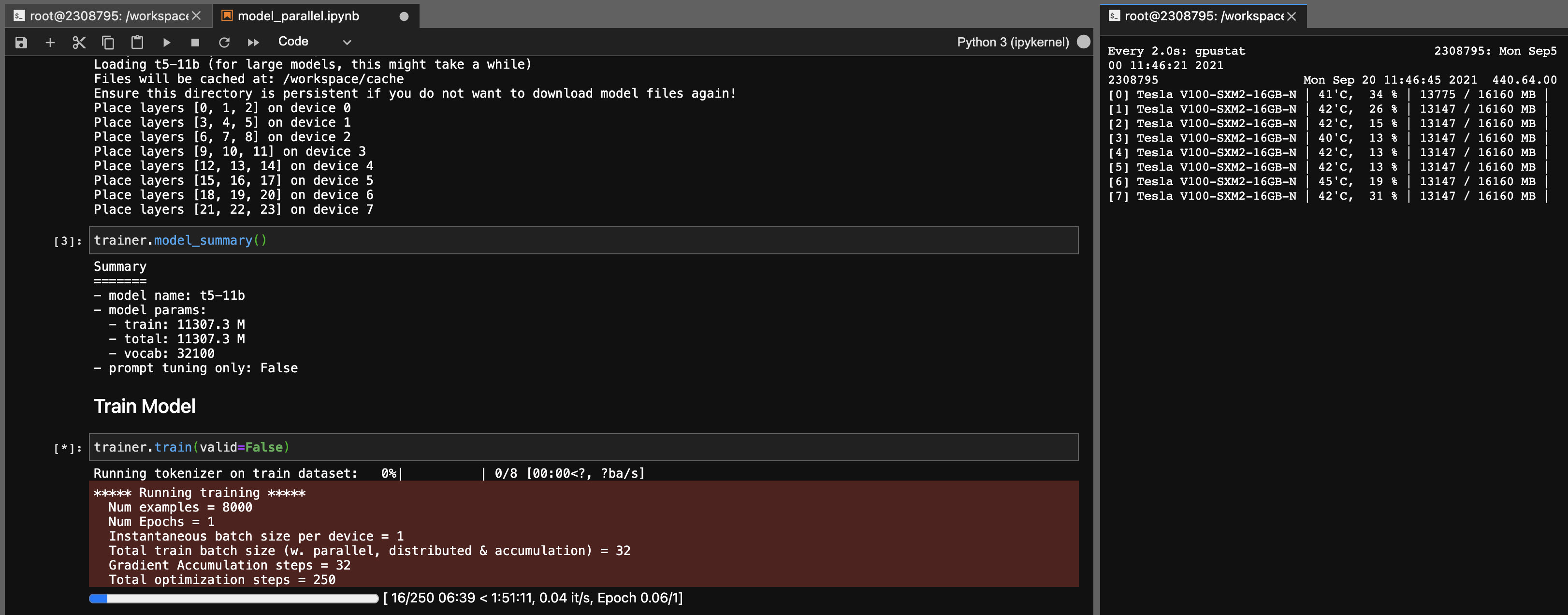
لاحظ أنه بناءً على نظامك ، يمكن أن يكون وقت التحميل لنقطة التفتيش (46 جيجابايت) طويلة جدًا. ستحتاج إلى ذاكرة الوصول العشوائي للوحدة المعالجة المركزية (ما لا يقل عن 90 جيجا بايت) لتحميلها بنجاح.
يعمل ONNX RT مع بعض النماذج (وليس T5 ، حتى الآن) ويمكن أن توفر دفعة صغيرة في السرعة.
قم بتثبيت ORT ، ثم قم بتعيين TrainingArguments.torch_ort=True
pip install torch-ort -f https://onnxruntimepackages.z14.web.core.windows.net/onnxruntime_stable_torch190.cu111.html
python -m torch_ort.configureحزمة البناء
python3 -m pip install --upgrade build twine
python3 -m build
python3 -m twine upload dist/ * تم تطوير هذه المكتبة كمشروع شخصي لاستخدامي الخاص. لا تتردد في شوكة أو استخدامه لأغراضك أيضًا. لن أتحمل مسؤولية أي حوادث تحدث نتيجة لاستخدام هذه المكتبة.
ملاحظة لبطاقات 3090 FE ، إذا بلغت المعجبين بك 100 ٪ ، فهذا يعني أن TEMPS VRAM عالية (> 100 درجة مئوية). يجب أن يكون التدريب لساعات طويلة في درجات الحرارة هذه من الناحية النظرية أمرًا جيدًا ، ولكن إذا كنت تريد راحة البال (مثلي) ، فيمكنك خفض تأثير الطاقة البسيط على سرعات التدريب. طالما أن معجبيك لم يصلوا إلى 100 ٪ ، يجب أن تكون درجات حرارة VRAM جيدة. على سبيل المثال ، لخفض حد الطاقة إلى 300W (من 350W):
sudo nvidia-smi -pl 300

