t2t tuner
1.0.0
Formation de texte à texte pratique pour Transformers
pip install t2t-tunerNécessite Pytorch: Suivez les instructions d'installation de Pytorch ou utilisez un conteneur Pytorch.
Basé sur la merveilleuse bibliothèque de transformateurs HuggingFace. Testé sur T5 et GPT de type de modèles. En théorie, il devrait fonctionner avec d'autres modèles qui prennent également en charge AutomodelforseQ2Seqlm ou AutomodelforCausallm.
Le formateur de cette bibliothèque ici est une interface de niveau supérieur à travailler en fonction du script run_translation.py.py de HuggingFace pour les tâches de génération de texte à texte. J'ai décidé que je voulais une interface plus pratique pour la formation et l'inférence, ainsi que l'accès à des choses comme le point de contrôle du gradient et le modèle parallèle à des modèles plus importants - ceux-ci sont déjà dans la bibliothèque HuggingFace mais non exposée dans le script. J'ai également ajouté dans certaines fonctionnalités que je voulais (réglage rapide, résumé de modèle), je l'ai intégré à une formation LM autorégressive et je l'ai enveloppé en une seule bibliothèque qui peut être installée PIP.
import t2t
trainer_arguments = t2t . TrainerArguments ( model_name_or_path = "t5-small" ,
train_file = YOUR_DATASET )
trainer = t2t . Trainer ( arguments = trainer_arguments )
# train without validation
trainer . train ( valid = False )Pour plus d'exemples concrets, consultez les ordinateurs portables liés ci-dessous:
Formation SEQ2SEQ
{ "translation" : { "s" : " TEXT " , "t" : " LABEL " }}TrainingArguments.source_id et TrainingArguments.target_id (par défaut à s et t ).TrainingArguments.prefix .Formation LM autorégressive
Cette section décrira comment former de grands modèles de langue (> 1 bil paramètres) sur des configurations relativement simples.
Quelques notes pour les configurations rapportées ci-dessous:
TrainerArguments.gradient_checkpointing ).trainer.freeze(embeddings=True) ).TrainingArguments.gradient_accumulation_steps ) pour compenser une taille de lot plus grande si nécessaire. Les tailles de lots rapportées sont sans accumulation de gradient.Certaines configurations GPT qui ont été testées pour pouvoir s'entraîner sur une seule carte RTX 3090 (24 Go) (sans profondeur):
| Modèle | Paramètres | Précision | Optimiseur | Entrée | Bac à lacets | Autre |
|---|---|---|---|---|---|---|
| gpt2 | 1.5b | FP16 | Adafacteur | 128 | 4 | Aucun |
| gpt2 | 1.5b | FP16 | Adafacteur | 512 | 1 | Aucun |
| gpt2 | 1.5b | FP16 | Adafacteur | 1024 | 4 | Gradcheckpoint |
| gpt-neo | 1.3b | FP16 | Adafacteur | 1024 | 1 | Aucun |
| gpt-neo | 1.3b | FP16 | Adafacteur | 2048 | 4 | Gradcheckpoint |
| gpt-neo | 2.7b | FP16 | Adafacteur | 2048 | 4 | GradCheckpoint, Freezeembeds |
Quelques configurations T5 qui ont été testées pour pouvoir s'entraîner sur une seule carte RTX 3090 (24 Go) (sans profondeur):
| Modèle | Paramètres | Précision | Optimiseur | SEQ2SEQLEN | Bac à lacets | Autre |
|---|---|---|---|---|---|---|
| t5 | 3B | Fp32 | Adafacteur | 128-> 128 | 1 | Congélations |
| t5 | 3B | Fp32 | Adafacteur | 128-> 128 | 1 | Gradcheckpoint |
| t5 | 3B | Fp32 | Adafacteur | 128-> 128 | 128 | GradCheckpoint, Freezeembeds |
| t5 | 3B | Fp32 | Adafacteur | 512-> 512 | 32 | GradCheckpoint, Freezeembeds |
Parallélisme du modèle pour les modèles T5-11B
En utilisant cette bibliothèque, vous pouvez également affiner les points de contrôle T5-11B assez facilement (nœud unique) avec les paramètres suivants (sans profondeur):
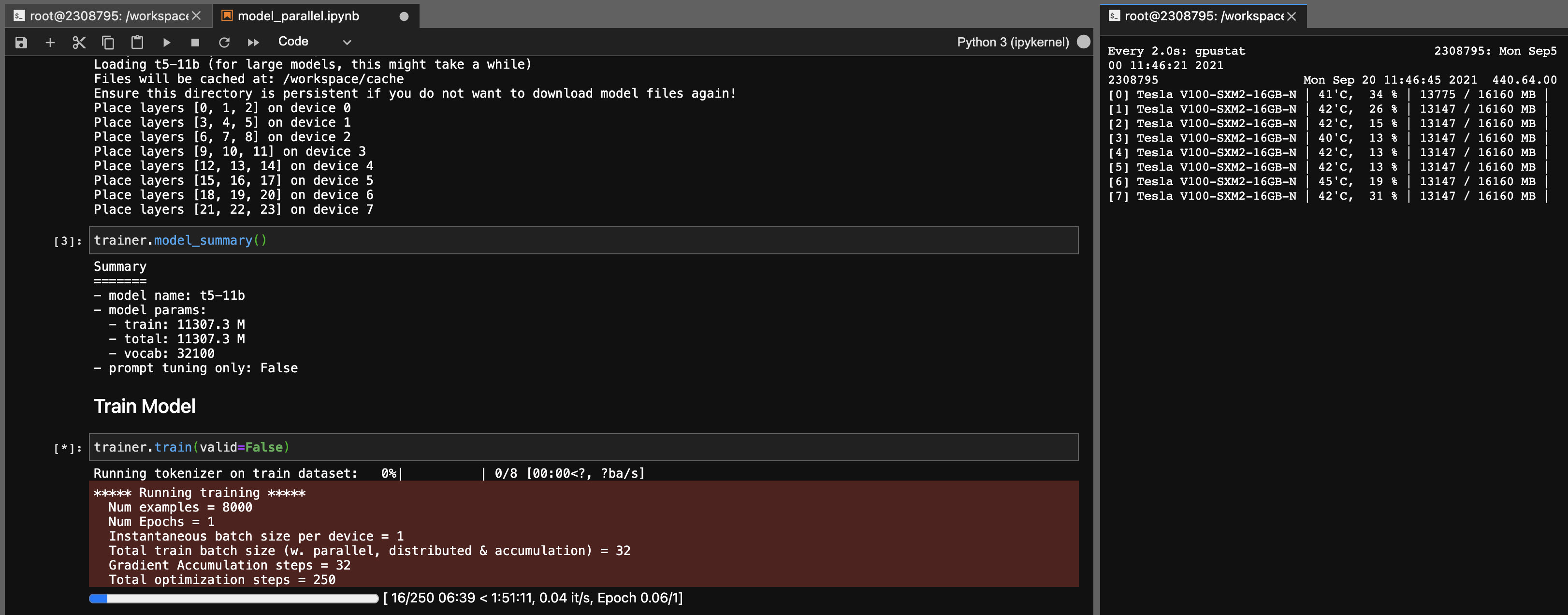
Notez que selon votre système, le temps de chargement du point de contrôle (46 Go) peut être très long. Vous aurez besoin de RAM CPU ample (au moins ~ 90 Go) pour le charger avec succès.
ONNX RT fonctionne avec certains modèles (pas T5, pourtant) et peut donner un petit coup de pouce de vitesse.
Installez ORT, puis définissez TrainingArguments.torch_ort=True
pip install torch-ort -f https://onnxruntimepackages.z14.web.core.windows.net/onnxruntime_stable_torch190.cu111.html
python -m torch_ort.configureForfait
python3 -m pip install --upgrade build twine
python3 -m build
python3 -m twine upload dist/ * Cette bibliothèque est développée comme un projet personnel pour mon propre usage. N'hésitez pas à se débarrasser ou à l'utiliser à vos propres fins. Je ne prendrai pas la responsabilité des accidents qui se produisent à la suite de l'utilisation de cette bibliothèque.
Remarque pour les cartes 3090 FE, si vos fans atteignent 100%, cela signifie que vos températures VRAM sont élevées (> 100 degrés C). L'entraînement pendant de longues heures à ces températures en théorie devrait être bien, mais si vous voulez une tranquillité d'esprit (comme moi), vous pouvez abaisser la limite de puissance, un impact mineur sur les vitesses d'entraînement. Tant que vos fans ne frappent jamais à 100%, vos températures VRAM devraient être bonnes. Par exemple, pour réduire la limite de puissance à 300W (à partir de 350W):
sudo nvidia-smi -pl 300

