語言模型數據選擇的調查
此存儲庫是在培訓的所有階段中與語言模型數據選擇相關的論文列表。這是為了成為社區的資源,因此,如果您看到任何缺失的東西,請做出貢獻!
有關這些作品的更多詳細信息,以及更多信息,請參閱我們的調查論文:有關語言模型數據選擇的調查。 By this incredible team: Alon Albalak, Yanai Elazar, Sang Michael Xie, Shayne Longpre, Nathan Lambert, Xinyi Wang, Niklas Muennighoff, Bairu Hou, Liangming Pan, Haewon Jeong, Colin Raffel, Shiyu Chang, Tatsunori Hashimoto, William Yang Wang
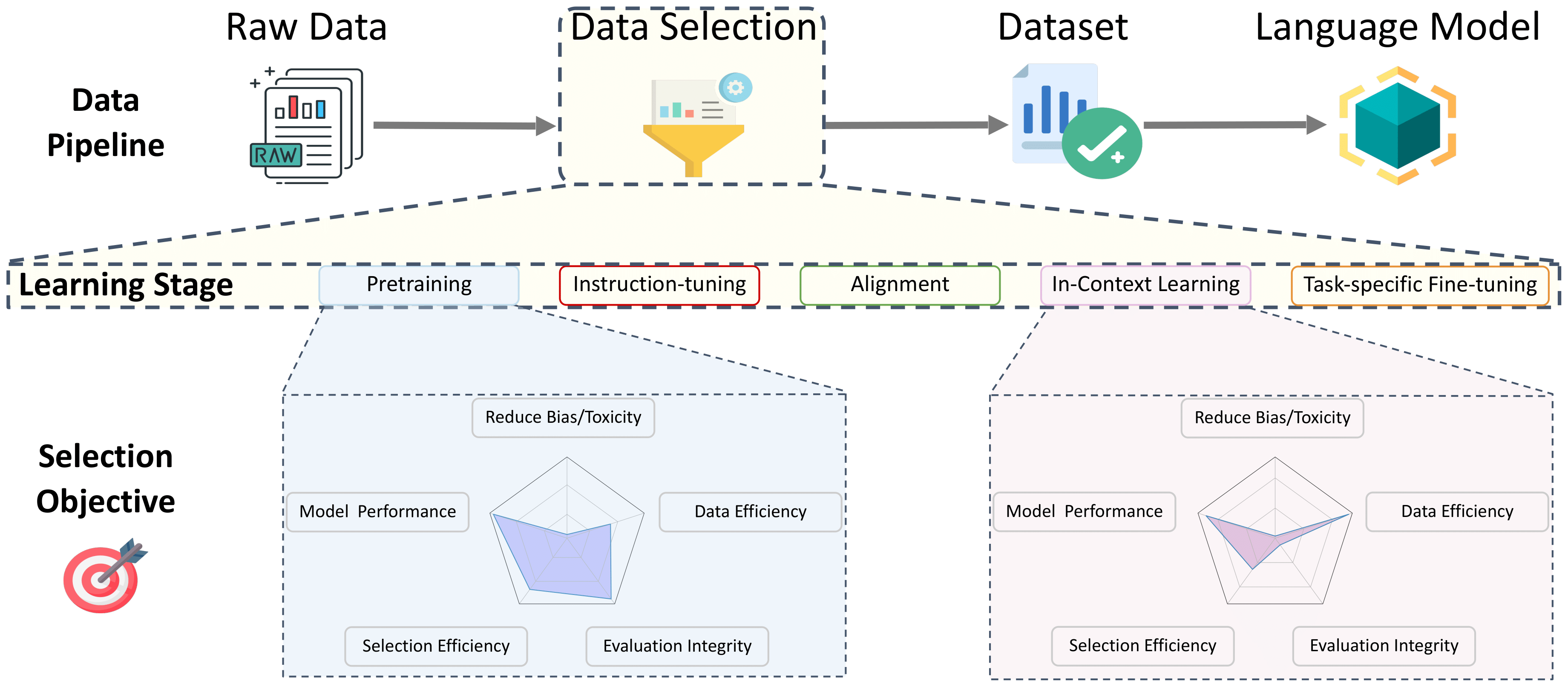
目錄
- 預處理的數據選擇
- 語言過濾
- 啟發式方法
- 數據質量
- 特定於域的選擇
- 數據刪除
- 過濾有毒和明確的內容
- 多語言模型的專業選擇
- 數據混合
- 指導調查和多任務培訓的數據選擇
- 偏好微調對齊的數據選擇
- 對秘密學習的數據選擇
- 針對特定任務的微調數據選擇
預處理的數據選擇
語言過濾
返回目錄
- fastText.zip:壓縮文本分類模型:2016
Armand Joulin和Edouard Grave和Piotr Bojanowski和Matthijs Douze和HérveJégou和Tomas Mikolov
- 157種語言的學習單詞向量:2018
Grave,Edouard和Bojanowski,Piotr和Gupta,Prakhar和Joulin,Armand和Mikolov,Tomas
- 跨語性語言模型預讀:2019年
康納,亞歷克西斯和萊姆,紀念
- 通過統一的文本到文本變壓器探索轉移學習的限制:2020
拉斐爾,科林和謝瑟,諾阿姆和羅伯茨,亞當... 3隱藏... Zhou,Yanqi和Li,Wei和Liu,Peter J.
- 野外語言ID:一千個語言網絡文本語料庫的意外挑戰:2020
Caswell,Isaac和Breiner,Theresa和Van Esch,Daan和Bapna,Ankur
- 無監督的跨語性表示學習:2020
Conneau,Alexis和Khandelwal,Kartikay和Goyal,Naman ... 4 Hidden ... Ott,Myle和Zettlemoyer,Luke和Stoyanov,Veselin
- CCNET:從Web爬網提取高質量的單語數據集:2020
Wenzek,Guillaume和Lachaux,Marie-Anne和Conneau,Alexis ... 1隱藏... Guzm'an,Francisco和Joulin,Armand and Grave,Edouard
- 蘋果雙向LSTM模型的複制在短字符串中:2021
Toftrup,Mads和Asger Sorensen,Soren和Ciosici,Manuel R.和Assent,IRA
- 評估經過代碼培訓的大型語言模型:2021
Mark Chen和Jerry Tworek和Heewoo Jun ... 52 Hidden ... Sam McCandlish和Ilya Sutskever和Wojciech Zaremba
- MT5:大規模多語言預訓練的文本到文本變壓器:2021
Xue,linting and Constant,Noah and Roberts,Adam ... 2隱藏... Siddhant,Aditya和Barua,Aditya和Raffel,Colin
- 競爭級代碼生成字母:2022
Li,Yujia和Choi,David和Chung,Junyoung ... 20 Hidden ... De Freitas,Nando和Kavukcuoglu,Koray和Vinyals,Oriol
- 棕櫚:用途徑縮放語言建模:2022
Aakanksha Chowdhery和Sharan Narang和Jacob Devlin ... 61 Hissed ... Jeff Dean和Slav Petrov和Noah Fiedel
- Bigscience根源語料庫:1.6TB複合多語言數據集:2022
Laurenccon,Hugo和Saulnier,Lucile和Wang,Thomas ... 48 Hidden ... Mitchell,Margaret和Luccioni,Sasha Alexandra和Jernite,Yacine,Yacine
- 2800多種語言品種的寫作系統和發言人元數據:2022
Van Esch,Daan和Lucassen,Tamar和Ruder,Sebastian和Caswell,Isaac和Rivera,Clara
- 指點:小語言的大型生成模型:2023
Luukkonen,Risto和Komulainen,Ville和Luoma,Jouni ... 5隱藏... Muennighoff,Niklas和Piktus,Aleksandra等
- MC^ 2:中國的多語言少數語言:2023
Zhang,Chen和Tao,Mingxu和Huang,Quzhe和Lin,Jiuheng and Chen,Zhibin和Feng,Yansong
- MADLAD-400:多語言和文檔級的大型審計數據集:2023
Kudugunta,Sneha和Caswell,Isaac和Zhang,Biao ... 5隱藏... Stella,Romi和Bapna,Ankur等
- Falcon LLM的精製網絡數據集:勝過Web數據的策劃Corpora,僅Web數據:2023
Guilherme Penedo和Quentin Malartic和Daniel Hesslow ... 3隱藏... Baptiste Pannier和Ebtesam Almazrouei和Julien Launay
- Dolma:用於語言模型預處理研究的三億代幣的開放語料庫:2024
盧卡·索爾納尼(Luca Soldaini)和羅德尼·金尼(Rodney Kinney)和阿克希塔·巴吉亞(Akshita Bhagia)... 30隱藏... Dirk Groeneveld和Jesse Dodge和Kyle Lo
啟發式方法
返回目錄
- 通過統一的文本到文本變壓器探索轉移學習的限制:2020
拉斐爾,科林和謝瑟,諾阿姆和羅伯茨,亞當... 3隱藏... Zhou,Yanqi和Li,Wei和Liu,Peter J.
- 語言模型是很少的學習者:2020
布朗,湯姆和曼恩,本傑明和萊德,尼克... 25隱藏...拉德福德,亞歷克和薩斯克弗,伊利亞和阿莫迪,達里奧
- 堆:語言建模的800GB數據集:2020
Leo Gao和Stella Biderman和Sid Black ... 6隱藏... Noa Nabeshima和Shawn Presser和Connor Leahy
- 評估經過代碼培訓的大型語言模型:2021
Mark Chen和Jerry Tworek和Heewoo Jun ... 52 Hidden ... Sam McCandlish和Ilya Sutskever和Wojciech Zaremba
- MT5:大規模多語言預訓練的文本到文本變壓器:2021
Xue,linting and Constant,Noah and Roberts,Adam ... 2隱藏... Siddhant,Aditya和Barua,Aditya和Raffel,Colin
- 縮放語言模型:訓練Gopher的方法,分析和見解:2022
傑克·W·雷(Jack W.
- Bigscience根源語料庫:1.6TB複合多語言數據集:2022
Laurenccon,Hugo和Saulnier,Lucile和Wang,Thomas ... 48 Hidden ... Mitchell,Margaret和Luccioni,Sasha Alexandra和Jernite,Yacine,Yacine
- HTLM:語言模型的超文本預培訓和提示:2022
Armen Aghajanyan和Dmytro Okhonko和Mike Lewis ... 1隱藏... Hu Xu和Gargi Ghosh和Luke Zettlemoyer
- 駱駝:開放有效的基礎語言模型:2023
Hugo Touvron和Thibaut Lavril和Gautier Izacard ... 8隱藏... Armand Joulin和Edouard Grave和Guillaume Lample
- Falcon LLM的精製網絡數據集:勝過Web數據的策劃Corpora,僅Web數據:2023
Guilherme Penedo和Quentin Malartic和Daniel Hesslow ... 3隱藏... Baptiste Pannier和Ebtesam Almazrouei和Julien Launay
- 基礎模型透明度指數:2023
Bommasani,Rishi和Klyman,Kevin和Longpre,Shayne ... 2 Hidden ... Xiong,Betty和Zhang,Daniel和Liang,Percy
- Dolma:用於語言模型預處理研究的三億代幣的開放語料庫:2024
盧卡·索爾納尼(Luca Soldaini)和羅德尼·金尼(Rodney Kinney)和阿克希塔·巴吉亞(Akshita Bhagia)... 30隱藏... Dirk Groeneveld和Jesse Dodge和Kyle Lo
數據質量
返回目錄
- Kenlm:更快,較小的語言模型查詢:2011年
肯尼斯Heafiel
- fastText.zip:壓縮文本分類模型:2016
Armand Joulin和Edouard Grave和Piotr Bojanowski和Matthijs Douze和HérveJégou和Tomas Mikolov
- 157種語言的學習單詞向量:2018
Grave,Edouard和Bojanowski,Piotr和Gupta,Prakhar和Joulin,Armand和Mikolov,Tomas
- 語言模型是無監督的多任務學習者:2019年
亞歷克·拉德福德(Alec Radford)和傑夫·吳(Jeff Wu)和雷沃(Rewon)的孩子,大衛·盧恩(David Luan)和達里奧·阿莫迪(Dario Amodei)
- 語言模型是很少的學習者:2020
布朗,湯姆和曼恩,本傑明和萊德,尼克... 25隱藏...拉德福德,亞歷克和薩斯克弗,伊利亞和阿莫迪,達里奧
- 堆:語言建模的800GB數據集:2020
Leo Gao和Stella Biderman和Sid Black ... 6隱藏... Noa Nabeshima和Shawn Presser和Connor Leahy
- CCNET:從Web爬網提取高質量的單語數據集:2020
Wenzek,Guillaume和Lachaux,Marie-Anne和Conneau,Alexis ... 1隱藏... Guzm'an,Francisco和Joulin,Armand and Grave,Edouard
- 排毒的語言模型風險將少數民族的聲音邊緣化:2021
Xu,Albert和Pathak,Eshaan和Wallace,Eric和Gururangan,Suchin和Sap,Maarten和Klein,Dan
- 棕櫚:用途徑縮放語言建模:2022
Aakanksha Chowdhery和Sharan Narang和Jacob Devlin ... 61 Hissed ... Jeff Dean和Slav Petrov和Noah Fiedel
- 縮放語言模型:訓練Gopher的方法,分析和見解:2022
傑克·W·雷(Jack W.
- 誰的語言算作高質量?衡量文本數據選擇中的語言意識形態:2022
古爾蘭加(Gururangan),Suchin and Card,Dallas和Dreier,Sarah ... 2隱藏... Wang,Zeyu和Zettlemoyer,Luke和Smith,Noah A.
- Glam:具有專家混合物的語言模型的有效縮放:2022
du,nan and huang,yanping和dai,安德魯·M ... 21隱藏...
- 訓練數據預處理指南:測量數據年齡,域覆蓋範圍,質量和毒性的影響:2023
Shayne Longpre和Gregory Yauney和Emily Reif ... 5隱藏... Kevin Robinson和David Mimno和Daphne Ippolito
- 通過重要性重採樣的語言模型數據選擇:2023
唱歌邁克爾·西(Michael Xie)和志巴尼·桑特卡(Shibani Santurkar)和坦古(Tengyu)
- Falcon LLM的精製網絡數據集:勝過Web數據的策劃Corpora,僅Web數據:2023
Guilherme Penedo和Quentin Malartic和Daniel Hesslow ... 3隱藏... Baptiste Pannier和Ebtesam Almazrouei和Julien Launay
- Dolma:用於語言模型預處理研究的三億代幣的開放語料庫:2024
盧卡·索爾納尼(Luca Soldaini)和羅德尼·金尼(Rodney Kinney)和阿克希塔·巴吉亞(Akshita Bhagia)... 30隱藏... Dirk Groeneveld和Jesse Dodge和Kyle Lo
- 編程每個示例:提升預培訓的數據質量,例如專家,規模:2024
Fan Zhou和Zengzhi Wang和Qian Liu和Junlong Li和Pengfei Liu
特定於域的選擇
返回目錄
- 特定領域的語言模型的文本數據採集:2006
Sethy,Abhinav和Georgiou,Panayiotis G.和Narayanan,Shrikanth
- 語言模型培訓的智能選擇數據:2010年
摩爾,羅伯特·C和劉易斯,威廉
- 語言模型培訓的憤世嫉俗選擇數據:2017
Amittai Axelrod
- 自動文檔選擇有效編碼器預審計:2022
Feng,Yukun和Xia,Patrick和Van Durme,Benjamin和Sedoc,Jo〜Ao
- 通過重要性重採樣的語言模型數據選擇:2023
唱歌邁克爾·西(Michael Xie)和志巴尼·桑特卡(Shibani Santurkar)和坦古(Tengyu)
- DSDM:使用DataModels選擇模型吸引數據集:2024
Logan Engstrom和Axel Feldmann和Aleksander Madry
數據刪除
返回目錄
- 帶有允許錯誤的哈希編碼中的空間/時間權衡:1970
布盧姆,伯頓H.
- 後綴陣列:一種用於在線字符串搜索的新方法:1993
Manber,Udi和Myers,Gene
- 關於文件的相似和遏制:1997
布羅德,亞利桑那州
- 圓形算法的相似性估計技術:2002
Charikar,MosesS。
- 網站刪除網頁的URL歸一化:2009年
Agarwal,Amit和Koppula,Hema Swetha和Leela,Krishna P .... 3 Hidden ... Haty,Chittaranjan和Roy,Anirban和Sasturkar,Amit
- 在中等至低資源基礎設施上處理大量語料庫的異步管道:2019年
Pedro Javier Ortiz Su'arez和Beno^IT Sagot和Laurent Romary
- 語言模型是很少的學習者:2020
布朗,湯姆和曼恩,本傑明和萊德,尼克... 25隱藏...拉德福德,亞歷克和薩斯克弗,伊利亞和阿莫迪,達里奧
- 堆:語言建模的800GB數據集:2020
Leo Gao和Stella Biderman和Sid Black ... 6隱藏... Noa Nabeshima和Shawn Presser和Connor Leahy
- CCNET:從Web爬網提取高質量的單語數據集:2020
Wenzek,Guillaume和Lachaux,Marie-Anne和Conneau,Alexis ... 1隱藏... Guzm'an,Francisco和Joulin,Armand and Grave,Edouard
- 超越神經縮放法律:通過數據修剪來擊敗功率定律縮放:2022
Ben Sorscher和Robert Geirhos和Shashank Shekhar和Surya Ganguli和Ari S. Morcos
- 重複培訓數據使語言模型更好:2022
Lee,Katherine和Ippolito,Daphne和Nystrom,Andrew ... 1 Hidden ... Eck,Douglas和Callison-Burch,Chris和Carlini,Nicholas
- MTEB:大量文本嵌入基準:2022
Muennighoff,Niklas和Tazi,Nouamane和Magne,Lo“ IC和Reimers,Nils
- 棕櫚:用途徑縮放語言建模:2022
Aakanksha Chowdhery和Sharan Narang和Jacob Devlin ... 61 Hissed ... Jeff Dean和Slav Petrov和Noah Fiedel
- 縮放語言模型:訓練Gopher的方法,分析和見解:2022
傑克·W·雷(Jack W.
- SGPT:語義搜索的GPT句子嵌入:2022
Muennighoff,Niklas
- Bigscience根源語料庫:1.6TB複合多語言數據集:2022
Laurenccon,Hugo和Saulnier,Lucile和Wang,Thomas ... 48 Hidden ... Mitchell,Margaret和Luccioni,Sasha Alexandra和Jernite,Yacine,Yacine
- C包:包裝資源以推進一般中國嵌入:2023
Xiao,Shitao和Liu,Zheng和Zhang,Peitian和Muennighoff,Niklas
- D4:通過文檔刪除和多元化改進LLM訓練:2023
Kushal Tirumala和Daniel Simig和Armen Aghajanyan和Ari S. Morcos
- 大規模大規模近二次大規模的大規模碼頭:2023
諒解備忘錄
- Paloma:評估語言模型擬合的基準:2023
Ian Magnusson和Akshita Bhagia和Valentin Hofmann ... 10隱藏... Noah A. Smith和Kyle Richardson和Jesse Dodge
- 跨神經語言模型量化記憶:2023
Nicholas Carlini和Daphne Ippolito和Matthew Jagielski和Katherine Lee以及Florian Tramer和Chiyuan Zhang
- SEMDEDUP:通過語義重複數據刪除在網絡尺度上的數據效率學習:2023
Abbas,Amro和Tirumala,Kushal和Simig,D'Aniel和Ganguli,Surya和Morcos,Ari S
- Falcon LLM的精製網絡數據集:勝過Web數據的策劃Corpora,僅Web數據:2023
Guilherme Penedo和Quentin Malartic和Daniel Hesslow ... 3隱藏... Baptiste Pannier和Ebtesam Almazrouei和Julien Launay
- 我的大數據是什麼? :2023
Elazar,Yanai和Bhagia,Akshita和Magnusson,Ian ... 5隱藏... Soldaini,Luca和Singh,Sameer等
- Dolma:用於語言模型預處理研究的三億代幣的開放語料庫:2024
盧卡·索爾納尼(Luca Soldaini)和羅德尼·金尼(Rodney Kinney)和阿克希塔·巴吉亞(Akshita Bhagia)... 30隱藏... Dirk Groeneveld和Jesse Dodge和Kyle Lo
- 生成代表性指令調整:2024
Muennighoff,Niklas和Su,Hongjin和Wang,Liang ... 2 Hidden ... Yu,Tao和Singh,Amanpreet和Kiela,Douwe
過濾有毒和明確的內容
返回目錄
- 通過統一的文本到文本變壓器探索轉移學習的限制:2020
拉斐爾,科林和謝瑟,諾阿姆和羅伯茨,亞當... 3隱藏... Zhou,Yanqi和Li,Wei和Liu,Peter J.
- MT5:大規模多語言預訓練的文本到文本變壓器:2021
Xue,linting and Constant,Noah and Roberts,Adam ... 2隱藏... Siddhant,Aditya和Barua,Aditya和Raffel,Colin
- 受到質量的困惑:一種基於困惑的成人和有害內容檢測的方法,在多語言異構網絡數據中:2022
蒂姆·詹森(Tim Jansen)和揚(Yangling Tong)和維多利亞·澤瓦洛斯(Victoria Zevallos)和佩德羅·奧爾蒂斯(Pedro Ortiz Suarez)
- 縮放語言模型:訓練Gopher的方法,分析和見解:2022
傑克·W·雷(Jack W.
- Bigscience根源語料庫:1.6TB複合多語言數據集:2022
Laurenccon,Hugo和Saulnier,Lucile和Wang,Thomas ... 48 Hidden ... Mitchell,Margaret和Luccioni,Sasha Alexandra和Jernite,Yacine,Yacine
- 誰的語言算作高質量?衡量文本數據選擇中的語言意識形態:2022
古爾蘭加(Gururangan),Suchin and Card,Dallas和Dreier,Sarah ... 2隱藏... Wang,Zeyu和Zettlemoyer,Luke和Smith,Noah A.
- 訓練數據預處理指南:測量數據年齡,域覆蓋範圍,質量和毒性的影響:2023
Shayne Longpre和Gregory Yauney和Emily Reif ... 5隱藏... Kevin Robinson和David Mimno和Daphne Ippolito
- AI圖像培訓數據集發現包括兒童性虐待圖像:2023
大衛,艾米莉亞
- 檢測培訓語料庫中的個人信息:分析:2023
Subramani,Nishant和Luccioni,Sasha和Dodge,Jesse和Mitchell,Margaret
- GPT-4技術報告:2023
Openai和:還有Josh Achiam ... 276 Hidden ... Juntang Zhuang和William Zhuk和Barret Zoph
- Santacoder:不要伸手去拿星星! :2023
Allal,Loubna Ben和Li,Raymond和Kocetkov,Denis ... 5隱藏... Gu,Alex和Dey,Manan等
- Falcon LLM的精製網絡數據集:勝過Web數據的策劃Corpora,僅Web數據:2023
Guilherme Penedo和Quentin Malartic和Daniel Hesslow ... 3隱藏... Baptiste Pannier和Ebtesam Almazrouei和Julien Launay
- 基礎模型透明度指數:2023
Bommasani,Rishi和Klyman,Kevin和Longpre,Shayne ... 2 Hidden ... Xiong,Betty和Zhang,Daniel和Liang,Percy
- 我的大數據是什麼? :2023
Elazar,Yanai和Bhagia,Akshita和Magnusson,Ian ... 5隱藏... Soldaini,Luca和Singh,Sameer等
- Dolma:用於語言模型預處理研究的三億代幣的開放語料庫:2024
盧卡·索爾納尼(Luca Soldaini)和羅德尼·金尼(Rodney Kinney)和阿克希塔·巴吉亞(Akshita Bhagia)... 30隱藏... Dirk Groeneveld和Jesse Dodge和Kyle Lo
- Olmo:加速語言模型的科學:2024
Groeneveld,Dirk和Beltagy,Iz和Walsh,Pete ... 5隱藏... Magnusson,Ian和Wang,Yizhong等人
多語言模型的專業選擇
返回目錄
- Bloom:176B參數開放式訪問多語言模型:2022
車間,Bigscience和Scao,Teven Le和Fan,Angela ... 5隱藏... Luccioni,Alexandra Sasha和Yvon,Franccois等
- 一目了然的質量:對網絡爬行的多語言數據集的審核:2022
Kreutzer,Julia和Caswell,Isaac和Wang,Lisa ... 46 Hidden ... Ahia,Oghenefego和Agrawal,Sweta和Adeyemi,Mofetoluwa
- Bigscience根源語料庫:1.6TB複合多語言數據集:2022
Laurenccon,Hugo和Saulnier,Lucile和Wang,Thomas ... 48 Hidden ... Mitchell,Margaret和Luccioni,Sasha Alexandra和Jernite,Yacine,Yacine
- 如果您有100萬個GPU小時,可以訓練哪種語言模型? :2022
Scao,Teven Le和Wang,Thomas和Hesslow,Daniel ... 5隱藏... Muennighoff,Niklas和Phang,Jason等人
- MADLAD-400:多語言和文檔級的大型審計數據集:2023
Kudugunta,Sneha和Caswell,Isaac和Zhang,Biao ... 5隱藏... Stella,Romi和Bapna,Ankur等
- 在受限數據下縮放多語言模型:2023
Scao,Teven Le
- AYA數據集:用於多語言指令調整的開放訪問集合:2024
Shivalika Singh和Freddie Vargus和Daniel Dsouza ... 27隱藏... Ahmetüstün和Marzieh Fadaee和Sara Hooker
數據混合
返回目錄
- 非策略多型強盜問題:2002
Auer,Peter和Cesa-Bianchi,Nicol`o和Freund,Yoav和Schapire,Robert E.
- 分配強大的語言建模:2019年
Oren,Yonatan和Sagawa,Shiori和Hashimoto,Tatsunori B.和Liang,Percy
- 分佈強大的神經網絡:2020
Shiori Sagawa和Pang Wei Koh和Tatsunori B. Hashimoto和Percy Liang
- 通過統一的文本到文本變壓器探索轉移學習的限制:2020
拉斐爾,科林和謝瑟,諾阿姆和羅伯茨,亞當... 3隱藏... Zhou,Yanqi和Li,Wei和Liu,Peter J.
- 堆:語言建模的800GB數據集:2020
Leo Gao和Stella Biderman和Sid Black ... 6隱藏... Noa Nabeshima和Shawn Presser和Connor Leahy
- 縮放語言模型:訓練Gopher的方法,分析和見解:2022
傑克·W·雷(Jack W.
- Glam:具有專家混合物的語言模型的有效縮放:2022
du,nan and huang,yanping和dai,安德魯·M ... 21隱藏...
- 跨語言監督改善了大型語言模型預培訓:2023
Andrea Schioppa和Xavier Garcia和Orhan Firat
- [DOGE:域重新加權估計](https://arxiv.org/abs/arxiv Preprint):2023
Simin Fan和Matteo Pagliardini和Martin Jaggi
- doremi:優化數據混合物加快語言模型預測:2023
唱歌邁克爾·西(Michael Xie)和hieu pham和xuanyi dong ... 4隱藏...
- 語言模型預培訓的有效在線數據混合:2023
阿隆·阿爾巴克(Alon Albalak)和liangming pan和Colin Raffel和William Yang Wang
- 駱駝:開放有效的基礎語言模型:2023
Hugo Touvron和Thibaut Lavril和Gautier Izacard ... 8隱藏... Armand Joulin和Edouard Grave和Guillaume Lample
- 腓熱:用於分析跨培訓和縮放的大型語言模型的套件:2023
Biderman,Stella和Schoelkopf,Hailey和Anthony,Quentin Gregory ... 7 Hidden ... Skowron,Aviya和Sutawika,Lintang和Van der Wal,Oskar
- 擴展數據受限的語言模型:2023
Niklas Muennighoff和Alexander M Rush和Boaz Barak ... 3隱藏... Sampo Pyysalo和Thomas Wolf和Colin Raffel
- 剪切駱駝:通過結構化修剪預訓練的加速語言模型:2023
Mengzhou Xia和Tianyu Gao和Zhiyuan Zeng和Danqi Chen
- 技巧!數據驅動的理解和培訓語言模型的技能框架:2023
Mayee F. Chen和Nicholas Roberts和Kush Bhatia ... 1隱藏... Ce Zhang和Frederic Sala和ChristopherRé
指導調查和多任務培訓的數據選擇
返回目錄
- 自然語言十項全能:多任務學習作為問題回答:2018
McCann,Bryan和Keskar,Nitish Shirish和Xiong,Caiming and Socher,Richard
- 通過跨度提取:2019
Keskar,Nitish Shirish和McCann,Bryan和Xiong,Caiming and Socher,Richard
- 自然語言理解的多任務深度神經網絡:2019
Liu,Xiaodong和他,Pengcheng和Chen,Weizhu和Gao,Jianfeng
- UNIFIEDQA:與單個質量檢查系統的交叉格式邊界:2020
卡沙比(Khashabi),丹尼爾(Daniel)和敏(Min),塞頓(Sewon)和霍特(Khot)
- 通過統一的文本到文本變壓器探索轉移學習的限制:2020
拉斐爾,科林和謝瑟,諾阿姆和羅伯茨,亞當... 3隱藏... Zhou,Yanqi和Li,Wei和Liu,Peter J.
- Muppet:大量的多任務表示,預注:2021
Aghajanyan,Armen和Gupta,Anchit和Shrivastava,Akshat和Chen,Xilun和Zettlemoyer,Luke和Gupta,Sonal
- 填充語言模型是零拍的學習者:2021
Wei,Jason和Bosma,Maarten和Zhao,Vincent Y .... 3 Hidden ... Du,Nan和Dai,Andrew M.和Le,Quoc V.
- 通過自然語言眾包指令的跨任務概括:2021
Mishra,Swaroop和Khashabi,Daniel和Baral,Chitta和Hajishirzi,Hannaneh
- NL-Aigmenter:任務敏感的自然語言增強框架:2021
Dhole,Kaustubh D和Gangal,Varun和Gehrmann,Sebastian ... 5隱藏... Shrivastava,Ashish and Tan,Samson等
- EXT5:邁向轉移學習的極端多任務縮放:2021
Aribandi,Vamsi和Tay,Yi和Schuster,Tal ... 5隱藏... Bahri,Dara和Ni,Jianmo等
- 超天然結構:1600+ NLP任務的聲明說明的概括:2022
王,Yizhong和Mishra,Swaroop和Alipoormolabashi,Pegah ... 29 Hidden ... Patro,Sumanta和Dixit,Tanay and Shen,Xudong
- 縮放指令 - 限制語言模型:2022
Chung,Hyung Won和Hou,Le和Longpre,Shayne ... 5隱藏... Dehghani,Mostafa和Brahma,Siddhartha等
- bloom+ 1:為零射擊提示添加語言支持:2022
Yong,Zheng-Xin和Schoelkopf,Hailey和Muennighoff,Niklas ... 5隱藏... Kasai,Jungo和Baruwa,Ahmed等人
- OPT-IML:縮放語言模型指令通過概括的鏡頭學習元學習:2022
Srinivasan Iyer和XI Victoria Lin和Ramakanth Pasunuru ... 12 Hissed ... Asli Celikyilmaz和Luke Zettlemoyer和Ves Stoyanov
- metaicl:學習在上下文中學習:2022
Min,Sewon和Lewis,Mike和Zettlemoyer,Luke和Hajishirzi,Hannaneh
- 不自然的說明:使用(幾乎)沒有人工勞動的調整語言模型:2022
Honovich,或Scialom,Thomas和Levy,Omer和Schick,Timo
- 通過多任務登錄的跨語言概括:2022
Muennighoff,Niklas和Wang,Thomas和Sutawika,Lintang ... 5隱藏... Yong,Zheng-Xin和Schoelkopf,Hailey等
- 多任務提示培訓啟用零射擊任務概括:2022
Victor Sanh和Albert Webson和Colin Raffel ... 34 Hidden ... Leo Gao和Thomas Wolf和Alexander M Rush
- Prometheus:在語言模型中誘導細粒度的評估能力:2023
Kim,Seungone和Shin,Jamin和Cho,Yejin ... 5隱藏... Kim,Sungdong和Thorne,James等人
- Slimorca:GPT-4增強Flan推理痕蹟的開放數據集,並進行驗證:2023
Wing Lian和Guan Wang和Bleys Goodson ... 1隱藏... Austin Cook和Chanvichet Vong和“ Teknium”
- AI藝術是從藝術家那裡竊取的嗎? :2023
Chayka,凱爾
- Paul Tremblay,Mona Awad vs. Openai,Inc。等:2023
Saveri,Joseph R.和Zirpoli,Cadio和Young,Christopher KL和McMahon,Kathleen J.
- 使大型語言模型更好地數據創建者:2023
Lee,Dong-Ho和Pujara,Jay和Sewak,Mohit和White,Ryen和Jauhar,Sujay
- Flan Collection:設計有效指令調整的數據和方法:2023
Shayne Longpre和Le Hou和Tu Vu ... 5隱藏... Barret Zoph和Jason Wei和Adam Roberts
- wizardlm:授權大語言模型遵循複雜說明:2023
XU,Can和Sun,Qingfeng和Zheng,Kai ... 2隱藏... Feng,Jiazhan和Tao,Chongyang和Jiang,Daxin
- 利馬:更少的對齊方式:2023
Chunting Zhou和Pengfei Liu和Puxin Xu ... 9隱藏... Mike Lewis和Luke Zettlemoyer和Omer Levy
- 駱駝在變化的氣候下:用圖盧2:2023增強LM適應
Hamish Ivison和Yizhong Wang和Valentina Pyatkin ... 5隱藏... Noah A. Smith和Iz Beltagy和Hannaneh Hajishirzi
- 自我建造:與自我生成的說明結合語言模型:2023
Wang,Yizhong和Kordi,Yeganeh和Mishra,Swaroop ... 1隱藏... Smith,Noah A.和Khashabi,Daniel和Hajishirzi,Hannaneh
- 是什麼使良好的數據保持對齊?對教學調整中自動數據選擇的全面研究:2023
Liu,Wei和Zeng,Weihao和他,Keqing和Jiang,Yong和他,Junxian
- 大型語言模型的說明調整:調查:2023
Shengyu Zhang和Linfeng Dong和Xiaoya Li ... 5隱藏... Tianwei Zhang和Fei Wu和Guoyin Wang
- 斯坦福羊駝:遵循的指導駱駝模型:2023
Rohan Taori和Ishaan Gulrajani和Tianyi Zhang ... 2隱藏... Carlos Guestrin和Percy Liang和Tatsunori B. Hashimoto
- 駱駝可以走多遠?在開放資源上探索教學狀態調整:2023
Yizhong Wang和Hamish Ivison和Pradeep Dasigi ... 5隱藏... Noah A. Smith和Iz Beltagy和Hannaneh Hajishirzi
- 開放式對話 - 大眾化大語言模型對準:2023
K“ OPF,Andreas和Kilcher,Yannic和Von R” Utte,Dimitri ... 5隱藏... Stanley,Oliver和Nagyfi,Rich'ard等人
- 章魚:指令調整代碼大語言模型:2023
Niklas Muennighoff和Qian Liu和Armel Zebaze ... 4隱藏... Xiangru Tang和Leandro von Werra和Shayne Longpre
- 自我:大語模型的語言驅動自我進化:2023
Lu,Jianqiao和Zhong,Wanjun和Huang,Wenyong ... 3隱藏... Wang,Weichao and Shang,Lifeng and Liu,Qun
- Flan Collection:設計有效指令調整的數據和方法:2023
Longpre,Shayne和Hou,Le和Vu,Tu ... 5隱藏... Zoph,Barret和Wei,Jason和Roberts,Adam
- #Instag:用於分析大語模型監督微調的指令標籤:2023
Keming Lu和Hongyi Yuan和Zheng Yuan ... 2隱藏... Chuanqi Tan和Chang Zhou和Jingren Zhou
- 指令挖掘:當數據挖掘符合大語言模型列表時:2023
Yihan Cao和Yanbin Kang和Chi Wang和Lichao Sun
- 主動說明調整:通過迅速敏感任務進行培訓改善交叉任務概括:2023
Po-nien功夫和范元,Di Wu和Kai-Wei Chang和Nanyun Peng
- 數據出處倡議:AI:2023中的數據集許可和歸因的大規模審核
Longpre,Shayne和Mahari,Robert和Chen,Anthony ... 5隱藏... Kabbara,Jad和Perisetla,Kartik等人
- AYA數據集:用於多語言指令調整的開放訪問集合:2024
Shivalika Singh和Freddie Vargus和Daniel Dsouza ... 27隱藏... Ahmetüstün和Marzieh Fadaee和Sara Hooker
- Astraios:參數效率指令調諧代碼大語言模型:2024
Zhuo,Terry Yue和Zebaze,Armel和Suppattarachai,Nitchakarn ... 1隱藏... De Vries,Harm and Liu,Qian和Muennighoff,Niklas
- AYA模型:指令固定的開放訪問多語言模型:2024
“ ust” Un,Ahmet和Aryabumi,Viraat和Yong,Zheng-Xin ... 5隱藏... ooi,Hui-Lee和Kayid,AMR,AMR等
- 較小的語言模型能夠為較大語言模型選擇指令調整培訓數據:2024
Dheeraj Mekala和Alex Nguyen和Jingbo Shang
- 可靠語言模型微調的自動數據策劃:2024
聖戰和喬納斯·穆勒
偏好微調的數據選擇:對齊
返回目錄
- Webgpt:通過人類反饋的瀏覽器協助提問:2021
中ano,瑞奇羅和希爾頓,雅各布和巴拉吉
- 通過從人類反饋中學習的有用且無害的助手培訓一位有益而無害的助手:2022
Bai,Yuntao和Jones,Andy and Ndousse,Kamal ... 5隱藏... Ganguli,Deep和Henighan,Tom和其他人
- 了解數據集難度使用$ Mathcalv $ - 可使用的信息:2022
Ethayarajh,Kawin和Choi,Yejin和Swayamdipta,Swabha
- 憲法AI:AI反饋的無害性:2022
Bai,Yuntao和Kadavath,Saurav和Kundu,Sandipan ... 5隱藏... Mirhoseini,Azalia和McKinnon,Cameron等
- Prometheus:在語言模型中誘導細粒度的評估能力:2023
Kim,Seungone和Shin,Jamin和Cho,Yejin ... 5隱藏... Kim,Sungdong和Thorne,James等人
- Notus:2023
Alvaro Bartolome和Gabriel Martin和Daniel Vila
- Ultrefeppback:具有高質量反饋的增強語言模型:2023
ganqu cui和lifan yuan和ning ding ... 3隱藏... Guotong Xie和Zhiyuan Liu和Maosong Sun
- 探索具有不同AI監督原則的探索:2023
Liu,Hao和Zaharia,Matei和Abbeel,Pieter
- wizardlm:授權大語言模型遵循複雜說明:2023
XU,Can和Sun,Qingfeng和Zheng,Kai ... 2隱藏... Feng,Jiazhan和Tao,Chongyang和Jiang,Daxin
- 利馬:更少的對齊方式:2023
Chunting Zhou和Pengfei Liu和Puxin Xu ... 9隱藏... Mike Lewis和Luke Zettlemoyer和Omer Levy
- 牧羊人:語言模型生成的評論家:2023
Tianlu Wang和Ping Yu和Xiaoqing Ellen Tan ... 4隱藏... Luke Zettlemoyer和Maryam Fazel-Zarandi和Asli Celikyilmaz
- 沒有機器人:2023
Nazneen Rajani和Lewis Tunstall和Edward Beeching和Nathan Lambert和Alexander M. Rush和Thomas Wolf
- Starling-7B:改善LLM的幫助和無害的RLAIF:2023
Zhu,Banghua和Frick,Evan和Wu,Tianhao和Zhu,Hanlin和Jiano,Jiantao
- 獎勵模型的縮放定律過度分配:2023
Gao,Leo和Schulman,John和Hilton,Jacob
- 鮭魚:與原理跟隨獎勵模型的自我調整:2023
Zhiqing Sun和Yikang Shen和Hongxin Zhang ... 2隱藏... David Cox和Yiming Yang和Chuang Gan
- 從人類反饋中學習的開放問題和強化學習的根本局限性:2023
斯蒂芬·卡斯珀(Stephen Casper)和Xander Davies和Claudia Shi ... 26隱藏... David Krueger和Dorsa Sadigh和Dylan Hadfield-Menell
- 駱駝在變化的氣候下:用圖盧2:2023增強LM適應
Hamish Ivison和Yizhong Wang和Valentina Pyatkin ... 5隱藏... Noah A. Smith和Iz Beltagy和Hannaneh Hajishirzi
- 駱駝2:開放基礎和微調聊天模型:2023
Hugo Touvron和Louis Martin和Kevin Stone ... 62隱藏... Robert Stojnic和Sergey Edunov和Thomas Scialom
- 是什麼使良好的數據保持對齊?對教學調整中自動數據選擇的全面研究:2023
Liu,Wei和Zeng,Weihao和他,Keqing和Jiang,Yong和他,Junxian
- HuggingFace H4堆棧交換偏好數據集:2023
蘭伯特(Lambert),內森(Nathan)和Tunstall,劉易斯(Lewis)和拉賈尼(Rajani),納茲恩(Nazneen)和鵝口瘡
- 教科書是您需要的:2023
Gunasekar,Suriya和Zhang,Yi和Aneja,Jyoti ... 5隱藏... De Rosa,Gustavo和Saarikivi,Olli等
- 通過AI反饋:2023
Herbie Bradley和Andrew Dai和Hannah Teufel ... 4隱藏... Kenneth Stanley和GrégorySchott和Joel Lehman
- 直接優先優化:您的語言模型是秘密的獎勵模型:2023
Rafailov,Rafael和Sharma,Archite和Mitchell,Eric和Ermon,Stefano和Manning,Christopher D和Finn,Chelsea
- 與大語言模型學習數學推理的擴展關係:2023
Yuan,Zheng和Yuan,Hongyi和Li,Chengpeng和Dong,Guanting和Tan,Chuanqi和Zhou,Chang
- 強化學習和人類反饋的歷史和風險:2023
蘭伯特,內森和吉爾伯特,托馬斯·克倫德爾和齊克,湯姆
- Zephyr:直接蒸餾LM對齊:2023
Tunstall,Lewis and Beeching,Edward和Lambert,Nathan ... 5隱藏... Fourrier,Cl'ementine和Habib,Nathan等人
- 自我反饋的危險:自我偏見在大語言模型中放大:2024
Wenda Xu和Guanglei Zhu和Xuandong Zhao和Liangming Pan和Lei Li和William Yang Wang
- 用直接原理反饋抑製粉紅色大象:2024
路易斯·卡斯特里卡托(Louis Castricato)和內森(Nathan Lile),蘇拉吉·阿南德(Suraj Anand)和海莉·舒爾科普(Hailey Schoelkopf)以及悉達多·維爾瑪(Siddharth Verma)和斯特拉·比德曼(Stella Biderman)
- N西部:改進的獎勵建模:2024
AlizéePace和Jonathan Mallinson,Eric Malmi和Sebastian Krause和Aliaksei Severyn
- 統計拒絕採樣改善了偏好優化:2024
Liu,Tianqi和Zhao,Yao和Joshi,Rishabh ... 1隱藏... Saleh,Mohammad和Liu,Peter J和Liu,Jialu
- 自我播放微調將弱語言模型轉換為強語模型:2024
Chen,Zixiang和Deng,Yihe和Yuan,Huizhuo和Ji,Kaixuan和Gu,Quanquan
- 自我獎勵語言模型:2024
Weizhe Yuan和Richard Yuanzhe Pang和Kyunghyun Cho和Sainbayar Sukhbaatar以及Jing Xu和Jason Weston
- 理論保證最佳N對準政策:2024
Beirami,Ahmad和Agarwal,Alekh和Berant,Jonathan ... 1 Hissed ... Eisenstein,Jacob和Nagpal,Chirag和Suresh,Ananda Theertha
- KTO:模型對準作為前景理論優化:2024
Ethayarajh,Kawin和Xu,Winnie和Muennighoff,Niklas和Jurafsky,Dan和Kiela,Douwe
對秘密學習的數據選擇
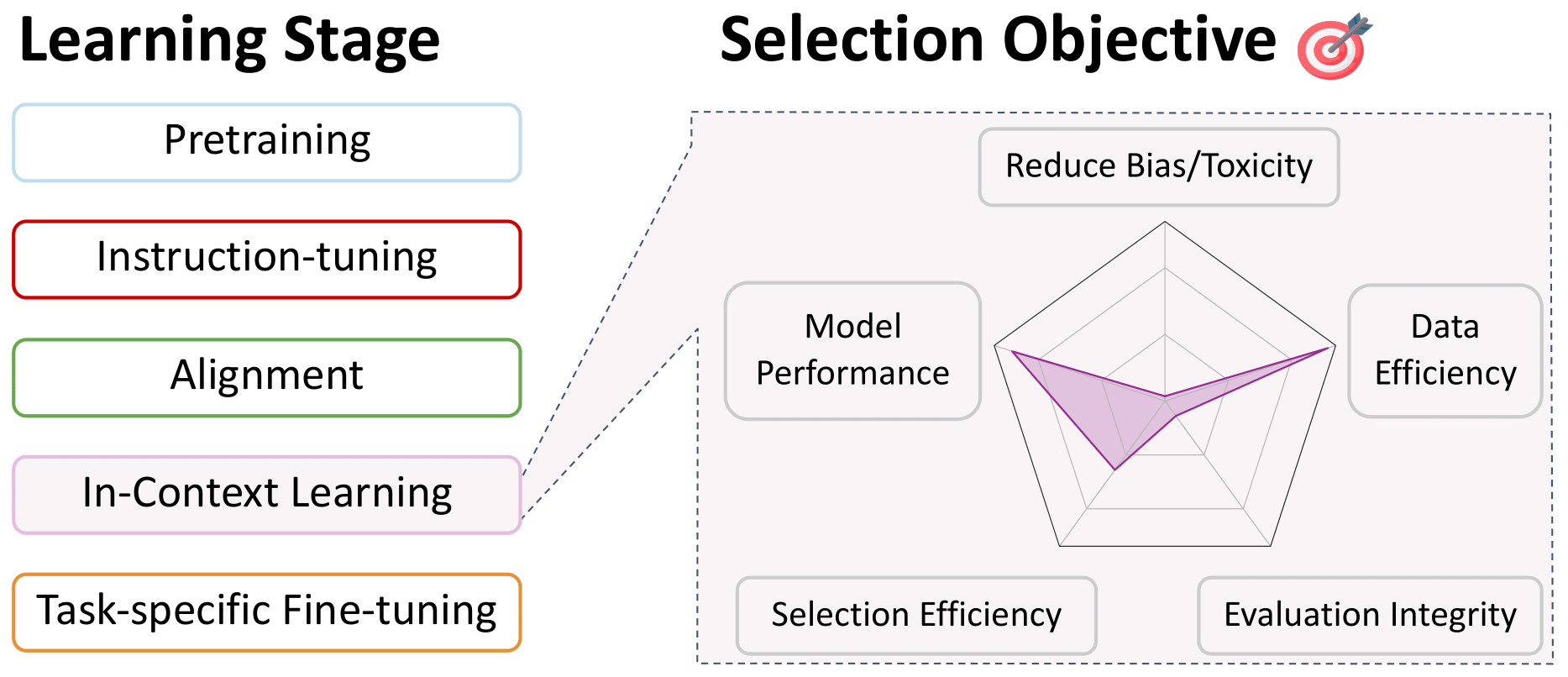
返回目錄
- 句子 - 伯特:使用Siamese Bert-Networks的句子嵌入:2019
Reimers,Nils和Gurevych,Iryna
- 語言模型是很少的學習者:2020
布朗,湯姆和曼恩,本傑明和萊德,尼克... 25隱藏...拉德福德,亞歷克和薩斯克弗,伊利亞和阿莫迪,達里奧
- 使用語言模型的真實數量學習:2021
Ethan Perez和Douwe Kiela和Kyunghyun Cho
- 主動示例選擇中的內在學習:2022
Zhang,Yiming和Feng,Shi和Tan,Chenhao
- 仔細的數據策展穩定在封閉式學習:2022
Chang,Ting-Yun和Jia,Robin
- 學習檢索提示的信息:2022
魯賓,哦,赫茲格,喬納森和貝蘭特,喬納森
- 井井有條的提示和在哪裡可以找到它們:克服幾乎沒有彈頭的提示命令靈敏度:2022
Lu,Yao和Bartolo,Max和Moore,Alastair和Riedel,Sebastian和Stenetorp,Pontus
- 是什麼使GPT-3的良好函數示例? :2022
Liu,Jiachang和Shen,Dinghan和Zhang,Yizhe和Dolan,Bill and Carin,Lawrence and Chen,Weizhu
- metaicl:學習在上下文中學習:2022
Min,Sewon和Lewis,Mike和Zettlemoyer,Luke和Hajishirzi,Hannaneh
- 統一演示檢索器用於內部文化學習:2023
Li,Xiaonan and LV,Kai和Yan,Hang ... 3隱藏... Xie,Guotong和Wang,Xiaoling和Qiu,Xipeng
- 哪些示例可以註釋以進行封閉式學習?邁向有效和高效的選擇:2023
Mavromatis,Costas和Srinivasan,Balasubramaniam和Shen,Zhengyuan ... 1隱藏... Rangwala,Huzefa和Faloutsos,Christos和Karypis,George,
- 大型語言模型是潛在變量模型:解釋和尋找有關秘密學習的良好演示:2023
Xinyi Wang和Wanrong Zhu和Michael Saxon以及Mark Steyvers和William Yang Wang
- 選擇性註釋使語言模型更好幾乎沒有學習者:2023
Hongjin Su和Jungo Kasai和Chen Henry Wu ... 5隱藏... Luke Zettlemoyer和Noah A. Smith和Tao Yu
- 影響影響的示例選擇:2023
Nguyen,Tai和Wong,Eric
- 基於覆蓋範圍的示例示例選擇:2023
古普塔(Gupta),希文舒(Shivanshu)和辛格(Singh),薩默(Same)和加德納(Gardner),馬特
- 內部文化學習的構圖示例:2023
Ye,Jicheng和Wu,Zhiyong和Feng,Jiangtao和Yu,Tao和Kong,Lingpeng
- 一次邁出一步,了解示範的增量實用性:重新播放的重新播放的分析:2023
Hashimoto,Kazuma和Raman,Karthik和Bendersky,Michael
- 大語言模型的模棱兩可的內在學習:2023
Gao,Lingyu和Chaudhary,Aditi和Srinivasan,Krishna和Hashimoto,Kazuma和Raman,Karthik和Bendersky,Michael
- 理想:影響驅動的選擇性註釋在大語言模型中增強了文化學習者的能力:2023
Zhang,Shaokun和Xia,Xiaobo和Wang,Zhaoqing ... 1隱藏... Liu,Jiale和Wu,Qingyun和Liu,Tongliang
- STACTSHOT:交互式內部文本示例策劃文本轉換:2023
Wu,Sherry和Shen,Hua和Weld,Daniel S和Heer,Jeffrey和Ribeiro,Marco Tulio
- 各種示範改善了文化的組成概括:2023
Levy,Itay and Bogin,Ben and Berant,Jonathan
- 查找文章學習的支持示例:2023
李,小和Qiu,Xipeng
- LLM中文化學習的基於錯誤的示範選擇:2024
XU,shangqing和Zhang,chao
- 語言模型的檢索示範中的文化學習:A調查:2024
Xu,Xin和Liu,Yue和Pasupat,Panupong和Kazemi,Mehran等
針對特定任務的微調數據選擇
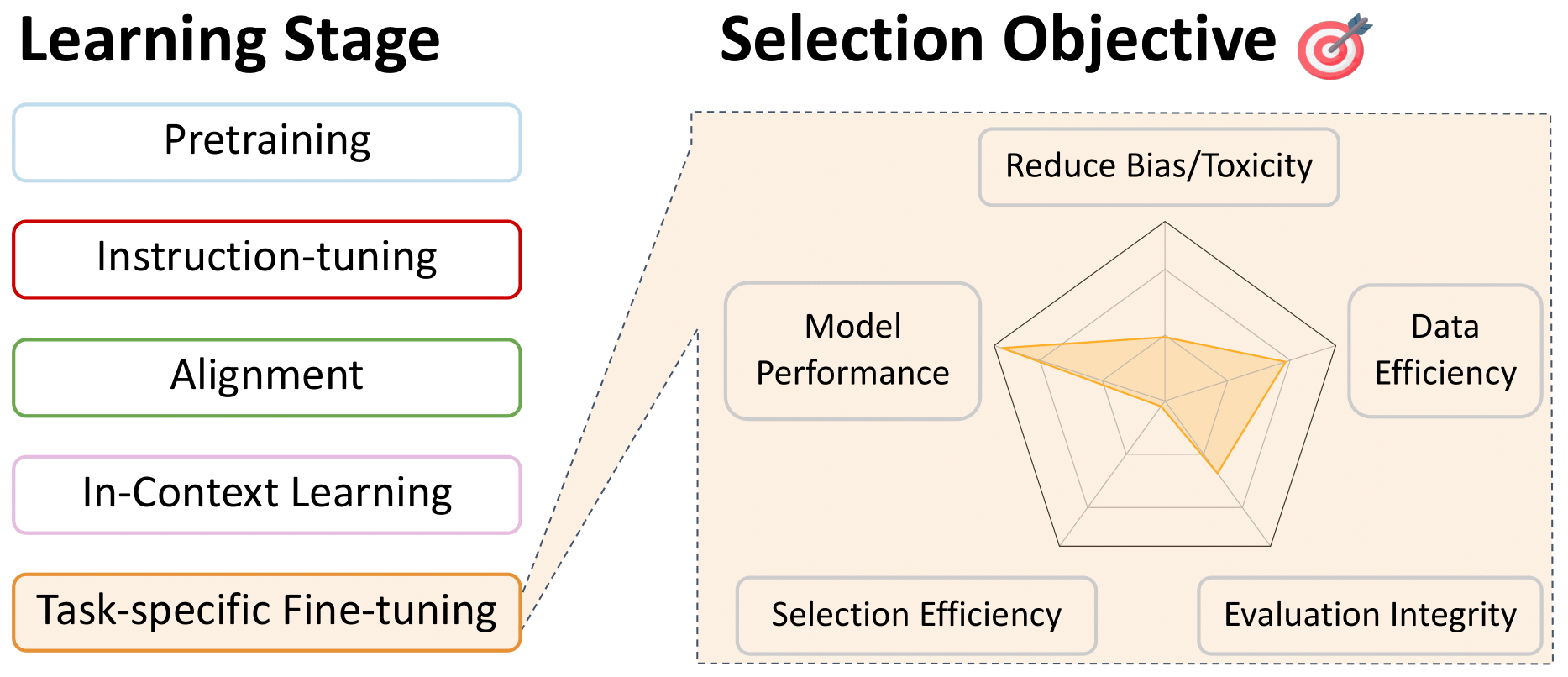
返回目錄
- 學習自然語言推斷的大型註釋語料庫:2015年
鮑曼(Bowman),塞繆爾·R(Samuel R.
- 膠水:自然語言理解的多任務基準和分析平台:2018
Wang,Alex和Singh,Amanpreet和Michael,Julian和Hill,Felix和Levy,Omer和Bowman,Samuel
- 通過推斷:2018
威廉姆斯,阿迪娜和南吉亞,尼基塔和鮑曼,塞繆爾
- 高蹺上的句子編碼:中間標籤data任務的補充培訓:2019
Jason Phang和ThibaultFévry和Samuel R. Bowman
- 分佈強大的神經網絡:2020
Shiori Sagawa和Pang Wei Koh和Tatsunori B. Hashimoto和Percy Liang
- 數據集製圖:用培訓動態映射和診斷數據集:2020
Swayamdipta,Swabha和Schwartz,Roy和Lourie,Nicholas ... 1隱藏... Hajishirzi,Hannaneh和Smith,Noah A.和Choi,Yejin
- 使用預讀的語言模型中級任務轉移學習:何時以及為什麼起作用? :2020
Pruksachatkun,Yada和Phang,Jason和Liu,Haokun ... 3隱藏... Vania,Clara和Kann,Katharina和Bowman,Samuel R.
- 關於數據選擇的互補性和針對域適應的微調:2021
Dan Iter和David Grangier
- Feta:開放域對話中的幾個樣本任務轉移的基準:2022
Albalak,Alon和Tuan,Yi-lin和Jandaghi,Pegah ... 3隱藏... Getoor,Lise和Pujara,Jay和Wang,William Yang
- 洛拉:大語言模型的低排名:2022
愛德華·J·胡(Edward J Hu),耶隆(Yelong)山和菲利普·沃利斯(Phillip Wallis)... 2隱藏... Shean Wang和Lu Wang和Weizhu Chen
- 較弱監督的培訓子集選擇:2022
Lang,Hunter和Vijayaraghavan,Aravindan和Sontag,David
- 按需採樣:從多個分佈中最佳學習:2022
Haghtalab,Nika和Jordan,Michael和Zhao,Eric
- 神經語言模型的領域改編的權衡:2022
Grangier,David和Iter,Dan
- 在神經機器翻譯中進行有效模型修剪的數據修剪:2023
Azeemi,Abdul和Qazi,Ihsan和Raza,Agha
- 技巧!數據驅動的理解和培訓語言模型的技能框架:2023
Mayee F. Chen和Nicholas Roberts和Kush Bhatia ... 1隱藏... Ce Zhang和Frederic Sala和ChristopherRé
- D2修剪:傳遞數據以平衡多樣性和難度的數據修剪:2023
Adyasha Maharana和Prateek Yadav和Mohit Bansal
- 通過探索和利用輔助數據來改善很少的概括:2023
Alon Albalak和Colin Raffel和William Yang Wang
- 語言模型預培訓的有效在線數據混合:2023
阿隆·阿爾巴克(Alon Albalak)和liangming pan和Colin Raffel和William Yang Wang
- 使用交叉任務最近的鄰居使用數據效率的鑑定:2023
Ivison,Hamish和Smith,Noah A.和Hajishirzi,Hannaneh和Dasigi,Pradeep
- 進行每個示例計數:從噪音NLP數據集學習的自我影響的穩定性和實用性:2023
Bejan,Irina和Sokolov,Artem和Filippova,Katja
- 少:選擇有影響力的數據進行調整:2024
Mengzhou Xia和Sadhika Malladi以及Suchin Gururangan,Sanjeev Arora和Danqi Chen
貢獻
我們錯過了該領域的一些令人驚嘆的作品,因此請為回購做出貢獻。
隨時用新論文打開拉動請求或創建問題,我們可以為您添加它們。預先感謝您的努力!
引用
我們希望這項工作是許多有影響力的未來作品的靈感。如果您發現我們的工作有用,請將本文引用為:
@article{albalak2024survey,
title={A Survey on Data Selection for Language Models},
author={Alon Albalak and Yanai Elazar and Sang Michael Xie and Shayne Longpre and Nathan Lambert and Xinyi Wang and Niklas Muennighoff and Bairu Hou and Liangming Pan and Haewon Jeong and Colin Raffel and Shiyu Chang and Tatsunori Hashimoto and William Yang Wang},
year={2024},
journal={arXiv preprint arXiv:2402.16827},
note={url{https://arxiv.org/abs/2402.16827}}
}


