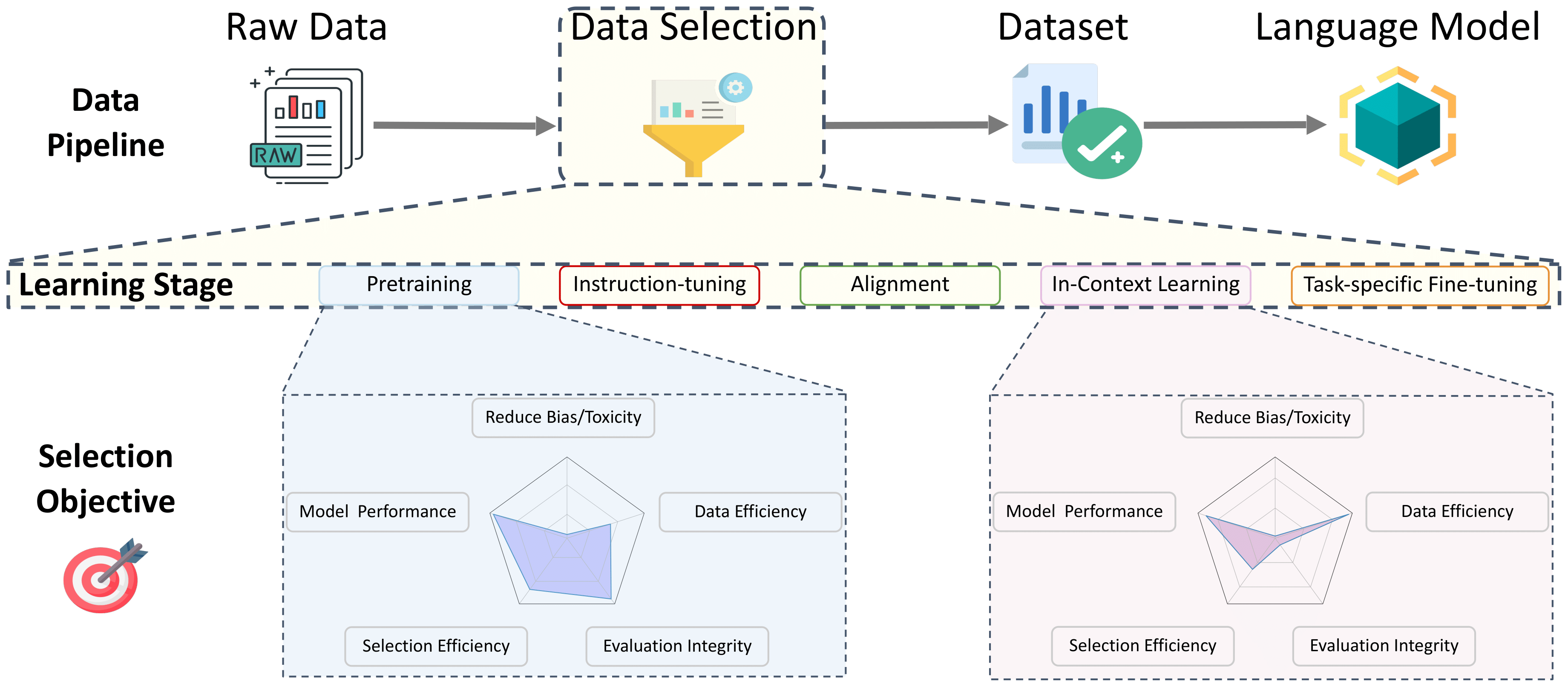
Опрос по выбору данных для языковых моделей
Это репо является удобным списком документов, относящихся к выбору данных для языковых моделей, на всех этапах обучения. Это предназначено для того, чтобы быть ресурсом для сообщества, поэтому, пожалуйста, внесите свой вклад, если вы видите, что чего -то не хватает!
Более подробную информацию об этих работах и многое другое, см. Наш документ для опроса: опрос по выбору данных для языковых моделей. Этой невероятной командой: Алон Альбалак, Янай Элазар, Санг Майкл Си, Шейн Лонгпри, Натан Ламберт, Синьи Ванг, Никлас Мененгофф, Байру Хоу, Лянгинг Пан, Хавон Чжон, Колин Раффел, Шию Чанг, Тацунори Хайхимот, Уильям Янг Ванг, Шию Чанг.
Оглавление
- Выбор данных для предварительной подготовки
- Языковая фильтрация
- Эвристические подходы
- Качество данных
- Домен специфичный отбор
- Данные данные
- Фильтрация токсичного и явного содержания
- Специализированный выбор для многоязычных моделей
- Смешивание данных
- Выбор данных для настройки обучения и многозадачности
- Выбор данных для предпочтения тонкая настройка выравнивания
- Выбор данных для обучения в контексте
- Выбор данных для точной настройки конкретной задачи
Выбор данных для предварительной подготовки
Языковая фильтрация
Вернуться к содержимому
- FASTTEXT.ZIP: сжатие моделей классификации текста: 2016
Арманд Джулин и Эдуард Могил и Пиотр Бояновский и Маттийс Дуз и Эрв Жегу и Томас Миколов
- Векторы обучения для 157 языков: 2018
Могила, Эдуард и Бояновский, Пиотр и Гупта, Прахар и Джулин, Арманд и Миколов, Томас
- Крестовая языковая модель предварительная подготовка: 2019
Конно, Алексис и Лэплу, Гийом
- Изучение пределов обучения передачи с помощью единого трансформатора текста в текст: 2020
Раффель, Колин и Шазир, Ноам и Робертс, Адам ... 3 Скрытый ... Чжоу, Янки и Ли, Вэй и Лю, Питер Дж.
- Идентификатор языка в дикой природе: неожиданные проблемы на пути к тысяче языковой веб-текстовой корпусе: 2020
Касвелл, Исаак и Брейнер, Тереза и Ван Эш, Даан и Бапна, Анкур
- Неконтролируемое межязычное представление Обучение в масштабе: 2020
Конно, Алексис и Хандельвал, Картикай и Гоял, Наман ... 4 Скрытые ... Отт, Майл и Зеттлемуер, Люк и Стоянов, Веселин
- CCNET: извлечение высококачественных монолингальных наборов данных из данных веб -сканирования: 2020
Вензек, Гийом и Лахау, Мари-Энн и Конно, Алексис ... 1 Скрытый ... Гусм'ан, Франциско и Джулин, Арманд и могила, Эдуард
- Воспроизведение двунаправленных моделей LSTM от Apple для идентификации языка в коротких строках: 2021
Toftrup, Mads и Asger Sorensen, Soren и Ciosici, Manuel R. и Assent, IRA
- Оценка крупных языковых моделей, обученных коду: 2021
Марк Чен и Джерри Творек и Heewoo Jun ... 52 Hidden ... Сэм МакКандлиш и Илью Сатскевер и Войцех Заремба
- MT5: массовый многоязычный предварительно обученный трансформатор текста в текст: 2021
Xue, Linting и Constant, Noah и Roberts, Adam ... 2 Hidden ... Siddhant, Aditya и Barua, Aditya и Raffel, Colin
- Генерация кода на уровне конкуренции с альфакодом: 2022
Ли, Юдзия и Чой, Дэвид и Чунг, Юньонг ... 20 Скрытых ... де Фрейтас, Нандо и Кавуккуоглу, Корай и Виналс, Ориол
- Palm: Моделирование языка масштабирования с помощью путей: 2022
Ааканкша Чоудери и Шаран Наранг и Джейкоб Девлин ... 61 Скрытый ... Джефф Дин и Слав Петров и Ноа Фидель
- Корпус Bigscience Corpes: составной многоязычный набор данных 1,6 ТБ: 2022
Laurenccon, Hugo и Saulnier, Lucile и Wang, Thomas ... 48 Hidden ... Митчелл, Маргарет и Луччиони, Саша Александра и Джернит, Ячин
- Записная система и метаданные докладчика для более чем 2800 сортов языка: 2022
Ван Эш, Даан и Лукассен, Тамар и Рудер, Себастьян и Касвелл, Исаак и Ривера, Клара
- Фытки: большие генеративные модели для маленького языка: 2023
Лукконен, Ристо и Комулайнен, Вилль и Луома, Джуни ... 5 Скрытый ... Мененгофф, Никлас и Пиктус, Александра и другие
- MC^ 2: многоязычный корпус языков меньшинств в Китае: 2023
Чжан, Чен и Тао, Мингсу и Хуанг, Кужэ и Лин, Джиухенг и Чен, Зибин и Фэн, Янсонг
- MADLAD-400: многоязычный набор данных на уровне документов: 2023
Кудугунта, Снеха и Касвелл, Исаак и Чжан, Биао ... 5 Скрытые ... Стелла, Роми и Бапна, Анкур и другие
- Набор данных RefinedWeb для Falcon LLM: опережать кураторские корпусы с веб -данными и только веб -данных: 2023
Гилхерм Пенедо и Квентин Малартик и Даниэль Хесслоу ... 3 Скрытые ... Баптист Панье и Эбсам Алмазруэи и Жюльен Лаунай
- Долма: открытый корпус из трех триллионов токенов для языковой модели. Предварительное исследование: 2024
Лука Солдайни и Родни Кинни и Акшита Бхагия ... 30 Скрытый ... Дирк Гроневельд и Джесси Додж и Кайл Ло
Эвристические подходы
Вернуться к содержимому
- Изучение пределов обучения передачи с помощью единого трансформатора текста в текст: 2020
Раффель, Колин и Шазир, Ноам и Робертс, Адам ... 3 Скрытый ... Чжоу, Янки и Ли, Вэй и Лю, Питер Дж.
- Языковые модели-несколько выстрелов: 2020
Браун, Том и Манн, Бенджамин и Райдер, Ник ... 25 Скрытый ... Рэдфорд, Алек и Сатскевер, Илья и Амодеей, Дарио
- Своение: набор данных с разнообразным текстом на 800 ГБ для языкового моделирования: 2020
Лео Гао и Стелла Бидерман и Сид Блэк ... 6 Скрытый ... Ноа Набешима и Шон Прессер и Коннор Лихи
- Оценка крупных языковых моделей, обученных коду: 2021
Марк Чен и Джерри Творек и Heewoo Jun ... 52 Hidden ... Сэм МакКандлиш и Илью Сатскевер и Войцех Заремба
- MT5: массовый многоязычный предварительно обученный трансформатор текста в текст: 2021
Xue, Linting и Constant, Noah и Roberts, Adam ... 2 Hidden ... Siddhant, Aditya и Barua, Aditya и Raffel, Colin
- Масштабирование языковых моделей: методы, анализ и понимание от тренировок суслика: 2022
Джек У. Рей и Себастьян Борги и Тревор Кай ... 74 Скрытые ... Демис Хассабис и Корай Кавуккуоглу и Джеффри Ирвинг
- Корпус Bigscience Corpes: составной многоязычный набор данных 1,6 ТБ: 2022
Laurenccon, Hugo и Saulnier, Lucile и Wang, Thomas ... 48 Hidden ... Митчелл, Маргарет и Луччиони, Саша Александра и Джернит, Ячин
- HTLM: гипертекстовое предварительное обучение и подсказка языковых моделей: 2022
Армен Агаджаньян и Дмитро Окхонко и Майк Льюис ... 1 Скрытый ... Ху Сюй и Гарги Гош и Люк Зеттлемуер
- Лама: открытые и эффективные основополагающие языковые модели: 2023
Хьюго Тувров и Тибо Лаврил и Гаутье Изакард ... 8 Скрытый ... Арманд Джулин и Эдуард Могила и Гийом Лобли
- Набор данных RefinedWeb для Falcon LLM: опережать кураторские корпусы с веб -данными и только веб -данных: 2023
Гилхерм Пенедо и Квентин Малартик и Даниэль Хесслоу ... 3 Скрытые ... Баптист Панье и Эбсам Алмазруэи и Жюльен Лаунай
- Индекс прозрачности фонда модели: 2023
Bommasani, Rishi и Klyman, Kevin и Longpre, Shayne ... 2 скрытые ... Xiong, Betty и Zhang, Daniel и Liang, Percy
- Долма: открытый корпус из трех триллионов токенов для языковой модели. Предварительное исследование: 2024
Лука Солдайни и Родни Кинни и Акшита Бхагия ... 30 Скрытый ... Дирк Гроневельд и Джесси Додж и Кайл Ло
Качество данных
Вернуться к содержимому
- Кенлм: быстрее и меньшие языковые запросы: 2011
Хифилд, Кеннет
- FASTTEXT.ZIP: сжатие моделей классификации текста: 2016
Арманд Джулин и Эдуард Могил и Пиотр Бояновский и Маттийс Дуз и Эрв Жегу и Томас Миколов
- Векторы обучения для 157 языков: 2018
Могила, Эдуард и Бояновский, Пиотр и Гупта, Прахар и Джулин, Арманд и Миколов, Томас
- Языковые модели - это неконтролируемые многозадачные ученики: 2019
Алек Рэдфорд и Джефф Ву и Ревон Чайлд и Дэвид Луан и Дарио Амодеи и Илья Сатскевер
- Языковые модели-несколько выстрелов: 2020
Браун, Том и Манн, Бенджамин и Райдер, Ник ... 25 Скрытый ... Рэдфорд, Алек и Сатскевер, Илья и Амодеей, Дарио
- Своение: набор данных с разнообразным текстом на 800 ГБ для языкового моделирования: 2020
Лео Гао и Стелла Бидерман и Сид Блэк ... 6 Скрытый ... Ноа Набешима и Шон Прессер и Коннор Лихи
- CCNET: извлечение высококачественных монолингальных наборов данных из данных веб -сканирования: 2020
Вензек, Гийом и Лахау, Мари-Энн и Конно, Алексис ... 1 Скрытый ... Гусм'ан, Франциско и Джулин, Арманд и могила, Эдуард
- Детоксифицирующие языковые модели рискуют маргинализирующими голоса меньшинства: 2021
Сюй, Альберт и Патак, Эшаан и Уоллес, Эрик и Гуруранган, Сучин и Сап, Маартен и Кляйн, Дэн
- Palm: Моделирование языка масштабирования с помощью путей: 2022
Ааканкша Чоудери и Шаран Наранг и Джейкоб Девлин ... 61 Скрытый ... Джефф Дин и Слав Петров и Ноа Фидель
- Масштабирование языковых моделей: методы, анализ и понимание от тренировок суслика: 2022
Джек У. Рей и Себастьян Борги и Тревор Кай ... 74 Скрытые ... Демис Хассабис и Корай Кавуккуоглу и Джеффри Ирвинг
- Чей язык считается высоким качеством? Идеологии измерения языка при выборе текстовых данных: 2022
Гуруранган, Сучин и Карда, Даллас и Дреер, Сара ... 2 Скрытые ... Ван, Зейу и Зеттлемуер, Люк и Смит, Ной А.
- Гламур: Эффективное масштабирование языковых моделей с смешением экспертов: 2022
Du, Nan и Huang, Yanping и Dai, Andrew M ... 21 Hidden ... Wu, Yonghui и Chen, Zhifeng и Cui, Claire
- Руководство по предварительному образованию по данным обучения: измерение последствий возраста данных, охвата домена, качества и токсичности: 2023
Шейн Лонгпри и Грегори Яуни и Эмили Рейф ... 5 Скрытый ... Кевин Робинсон и Дэвид Мимно и Дафна Ипполито
- Выбор данных для языковых моделей через важность повторной дискретизации: 2023
Санг Майкл Си и Шибани Сантуркар и Тенгю Ма и Перси Лян
- Набор данных RefinedWeb для Falcon LLM: опережать кураторские корпусы с веб -данными и только веб -данных: 2023
Гилхерм Пенедо и Квентин Малартик и Даниэль Хесслоу ... 3 Скрытые ... Баптист Панье и Эбсам Алмазруэи и Жюльен Лаунай
- Долма: открытый корпус из трех триллионов токенов для языковой модели. Предварительное исследование: 2024
Лука Солдайни и Родни Кинни и Акшита Бхагия ... 30 Скрытый ... Дирк Гроневельд и Джесси Додж и Кайл Ло
- Программирование каждого примера: подъем предварительного обучения качества данных, как эксперты в масштабе: 2024
Фан Чжоу и Зенгжи Ван и Цянь Лю и Джунлонг Ли и Пенгфей Лю
Домен специфичный отбор
Вернуться к содержимому
- Получение текстовых данных для языковых моделей, специфичных для домена: 2006
Сетей, Абхинав и Георгиу, Панайотис Г. и Нараянан, Шрикант
- Интеллектуальный выбор данных обучения языковой модели: 2010
Мур, Роберт С. и Льюис, Уильям
- Циничный выбор данных обучения языковой модели: 2017
Amittai Axelrod
- Автоматический выбор документов для эффективной предварительной подготовки энкодера: 2022
Фэн, Юкун и Ся, Патрик и Ван Дурм, Бенджамин и Седок, Джо ~ Ао
- Выбор данных для языковых моделей через важность повторной дискретизации: 2023
Санг Майкл Си и Шибани Сантуркар и Тенгю Ма и Перси Лян
- DSDM: Выбор набора данных с моделью с DataModels: 2024
Логан Энгстрем и Аксель Фельдманн и Александер Мэдри
Данные данные
Вернуться к содержимому
- Космические/временные компромиссы в хэш-кодировании с допустимыми ошибками: 1970
Блум, Бертон Х.
- Массивы суффиксов: новый метод для онлайн-поиска строк: 1993
Манбер, Уди и Майерс, Джин
- О сходстве и сдерживании документов: 1997
Бродер, Аризона
- Методы оценки сходства из алгоритмов округления: 2002
Чарикар, Моисей С.
- Нормализация URL-адреса для раздувания веб-страниц: 2009
Агарвал, Амит и Коппула, Хема Света и Лила, Кришна П .... 3 Скрытые ... Хати, Читтаранджан и Рой, Анирбан и Састуркар, Амит
- Асинхронные трубопроводы для обработки огромных корпораций на средних и низких ресурсных инфраструктурах: 2019
Педро Хавьер Ортис Су'арес и Бено^это Sagot и Laurent Romary
- Языковые модели-несколько выстрелов: 2020
Браун, Том и Манн, Бенджамин и Райдер, Ник ... 25 Скрытый ... Рэдфорд, Алек и Сатскевер, Илья и Амодеей, Дарио
- Своение: набор данных с разнообразным текстом на 800 ГБ для языкового моделирования: 2020
Лео Гао и Стелла Бидерман и Сид Блэк ... 6 Скрытый ... Ноа Набешима и Шон Прессер и Коннор Лихи
- CCNET: извлечение высококачественных монолингальных наборов данных из данных веб -сканирования: 2020
Вензек, Гийом и Лахау, Мари-Энн и Конно, Алексис ... 1 Скрытый ... Гусм'ан, Франциско и Джулин, Арманд и могила, Эдуард
- Помимо законов о масштабировании нейронного масштаба: побивание законодательства о власти за счет обрезки данных: 2022
Бен Соршер и Роберт Гейрхос и Шашанк Шехар и Сурья Гангули и Ари С. Моркос
- Дедуплирование данных обучения делает языковые модели лучше: 2022
Ли, Кэтрин и Ипполито, Дафна и Нистрем, Эндрю ... 1 Скрытый ... Эк, Дуглас и Каллисон-Берч, Крис и Карлини, Николас
- MTEB: массивный текстовый эталон встраивания: 2022
Muennigoff, Niklas и Tazi, Nouamane и Magne, Lo "IC и Reimers, Nils
- Palm: Моделирование языка масштабирования с помощью путей: 2022
Ааканкша Чоудери и Шаран Наранг и Джейкоб Девлин ... 61 Скрытый ... Джефф Дин и Слав Петров и Ноа Фидель
- Масштабирование языковых моделей: методы, анализ и понимание от тренировок суслика: 2022
Джек У. Рей и Себастьян Борги и Тревор Кай ... 74 Скрытые ... Демис Хассабис и Корай Кавуккуоглу и Джеффри Ирвинг
- SGPT: GPT предложение встраивание для семантического поиска: 2022
Мюеннгофф, Никлас
- Корпус Bigscience Corpes: составной многоязычный набор данных 1,6 ТБ: 2022
Laurenccon, Hugo и Saulnier, Lucile и Wang, Thomas ... 48 Hidden ... Митчелл, Маргарет и Луччиони, Саша Александра и Джернит, Ячин
- C-Pack: упакованные ресурсы для продвижения общего китайского встраивания: 2023
Сяо, Шитао и Лю, Чжэн и Чжан, Пейтиан и Мененьгофф, Никлас
- D4: Улучшение предварительной подготовки LLM с помощью детукации и диверсификации документов: 2023
Кушал Тирумала и Даниэль Симиг и Арден Агаджаньян и Ари С. Моркос
- Крупномасштабная близость-точка за большим кодом: 2023
Мусюр, Ченгао
- Палома: эталон для оценки языковой модели подходит: 2023
Ян Магнуссон и Акшита Бхагия и Валентин Хофманн ... 10 Скрытый ... Ноа А. Смит и Кайл Ричардсон и Джесси Додж
- Количественная оценка запоминания в моделях нейронного языка: 2023
Николас Карлини и Дафни Ипполито и Мэтью Джагельски, Кэтрин Ли, а также Флориан Трамер и Чиюан Чжан
- SEMDEDUP: эффективное обучение данных в веб-масштабе через семантическую дедупликацию: 2023
Аббас, Амро и Тирумала, Кушал и Симиг, Д'Аниэль и Гангули, Сурья и Моркос, Ари С.
- Набор данных RefinedWeb для Falcon LLM: опережать кураторские корпусы с веб -данными и только веб -данных: 2023
Гилхерм Пенедо и Квентин Малартик и Даниэль Хесслоу ... 3 Скрытые ... Баптист Панье и Эбсам Алмазруэи и Жюльен Лаунай
- Что в моих больших данных?: 2023
Elazar, Yanai и Bhagia, Akshita и Magnusson, Ian ... 5 Hidden ... Soldaini, Luca и Singh, Someer и другие
- Долма: открытый корпус из трех триллионов токенов для языковой модели. Предварительное исследование: 2024
Лука Солдайни и Родни Кинни и Акшита Бхагия ... 30 Скрытый ... Дирк Гроневельд и Джесси Додж и Кайл Ло
- Генеративная репрезентативная настройка инструкций: 2024
Muennigoff, Niklas and Su, Hongjin и Wang, Liang ... 2 Hidden ... Yu, Tao и Singh, Amanpreet и Kiela, Douwe
Фильтрация токсичного и явного содержания
Вернуться к содержимому
- Изучение пределов обучения передачи с помощью единого трансформатора текста в текст: 2020
Раффель, Колин и Шазир, Ноам и Робертс, Адам ... 3 Скрытый ... Чжоу, Янки и Ли, Вэй и Лю, Питер Дж.
- MT5: массовый многоязычный предварительно обученный трансформатор текста в текст: 2021
Xue, Linting и Constant, Noah и Roberts, Adam ... 2 Hidden ... Siddhant, Aditya и Barua, Aditya и Raffel, Colin
- Озадачен качеством: метод, основанный на недоумении для обнаружения взрослых и вредного содержания в многоязычных гетерогенных веб-данных: 2022
Тим Янсен и Янглинг Тонг и Виктория Зеваллос и Педро Ортис Суарес
- Масштабирование языковых моделей: методы, анализ и понимание от тренировок суслика: 2022
Джек У. Рей и Себастьян Борги и Тревор Кай ... 74 Скрытые ... Демис Хассабис и Корай Кавуккуоглу и Джеффри Ирвинг
- Корпус Bigscience Corpes: составной многоязычный набор данных 1,6 ТБ: 2022
Laurenccon, Hugo и Saulnier, Lucile и Wang, Thomas ... 48 Hidden ... Митчелл, Маргарет и Луччиони, Саша Александра и Джернит, Ячин
- Чей язык считается высоким качеством? Идеологии измерения языка при выборе текстовых данных: 2022
Гуруранган, Сучин и Карда, Даллас и Дреер, Сара ... 2 Скрытые ... Ван, Зейу и Зеттлемуер, Люк и Смит, Ной А.
- Руководство по предварительному образованию по данным обучения: измерение последствий возраста данных, охвата домена, качества и токсичности: 2023
Шейн Лонгпри и Грегори Яуни и Эмили Рейф ... 5 Скрытый ... Кевин Робинсон и Дэвид Мимно и Дафна Ипполито
- Набор данных по обучению изображений ИИ включает в себя изображения сексуального насилия над детьми: 2023
Дэвид, Эмилия
- Обнаружение личной информации в учебных корпусах: анализ: 2023
Subramani, Nishant и Luccioni, Sasha and Dodge, Jesse и Mitchell, Margaret
- Технический отчет GPT-4: 2023
Openai и: и Джош Ахиам ... 276 Скрытый ... Юнтанг Чжуан и Уильям Чжук и Баррет Зоф
- Santacoder: не дотянись за звездами!: 2023
Аллал, Лубна Бен и Ли, Рэймонд и Кочеетков, Денис ... 5 Скрытый ... Гу, Алекс и Дей, Манан и другие
- Набор данных RefinedWeb для Falcon LLM: опережать кураторские корпусы с веб -данными и только веб -данных: 2023
Гилхерм Пенедо и Квентин Малартик и Даниэль Хесслоу ... 3 Скрытые ... Баптист Панье и Эбсам Алмазруэи и Жюльен Лаунай
- Индекс прозрачности фонда модели: 2023
Bommasani, Rishi и Klyman, Kevin и Longpre, Shayne ... 2 скрытые ... Xiong, Betty и Zhang, Daniel и Liang, Percy
- Что в моих больших данных?: 2023
Elazar, Yanai и Bhagia, Akshita и Magnusson, Ian ... 5 Hidden ... Soldaini, Luca и Singh, Someer и другие
- Долма: открытый корпус из трех триллионов токенов для языковой модели. Предварительное исследование: 2024
Лука Солдайни и Родни Кинни и Акшита Бхагия ... 30 Скрытый ... Дирк Гроневельд и Джесси Додж и Кайл Ло
- OLMO: Ускорение науки о языковых моделях: 2024
Groeneveld, Dirk and Beltagy, Iz и Walsh, Pete ... 5 Hidden ... Magnusson, Ian и Wang, Yizhong и другие
Специализированный выбор для многоязычных моделей
Вернуться к содержимому
- Блум: многоязычная языковая модель с открытым доступом 176B-параметра: 2022
Семинар, Bigscience и Scao, Teven Le и Fan, Angela ... 5 Hidden ... Luccioni, Alexandra Sasha и Yvon, Franccois и другие
- Качество с первого взгляда: аудит многоязычных наборов данных: 2022
Кройцер, Джулия и Касвелл, Исаак и Ван, Лиза ... 46 Скрытые ... Ахи, Огенефго и Агравал, Света и Адейеми, Мофетолува
- Корпус Bigscience Corpes: составной многоязычный набор данных 1,6 ТБ: 2022
Laurenccon, Hugo и Saulnier, Lucile и Wang, Thomas ... 48 Hidden ... Митчелл, Маргарет и Луччиони, Саша Александра и Джернит, Ячин
- На какой языковой модели тренироваться, если у вас один миллион графических часов?: 2022
Скао, Тевен Ле и Ван, Томас и Хесслоу, Даниэль ... 5 Скрытый ... Мененгофф, Никлас и Пханг, Джейсон и другие
- MADLAD-400: многоязычный набор данных на уровне документов: 2023
Кудугунта, Снеха и Касвелл, Исаак и Чжан, Биао ... 5 Скрытые ... Стелла, Роми и Бапна, Анкур и другие
- Масштабирование многоязычных языковых моделей в рамках ограниченных данных: 2023
Scao, Teven le
- Набор данных AYA: коллекция с открытым доступом для многоязычной настройки инструкций: 2024
Шивалка Сингх и Фредди Варгус и Даниэль Дсуза ... 27 Скрытый ... Ахмет üstün и Марзи Фадаи и Сара Хукер
Смешивание данных
Вернуться к содержимому
- Неустохастическая проблема бандитса: 2002 г.
Auer, Peter and Cesa-Bianchi, Nicol`o и Freund, Yoav и Schapire, Robert E.
- Дистрибутивное моделирование языка: 2019
Орен, Йонатан и Сагава, Шиори и Хасимото, Татсунори Б. и Лян, Перси
- Распространение нейронных сетей: 2020
Шиори Сагава и Панг Вэй Ко и Татсунори Б. Хашимото и Перси Лян
- Изучение пределов обучения передачи с помощью единого трансформатора текста в текст: 2020
Раффель, Колин и Шазир, Ноам и Робертс, Адам ... 3 Скрытый ... Чжоу, Янки и Ли, Вэй и Лю, Питер Дж.
- Своение: набор данных с разнообразным текстом на 800 ГБ для языкового моделирования: 2020
Лео Гао и Стелла Бидерман и Сид Блэк ... 6 Скрытый ... Ноа Набешима и Шон Прессер и Коннор Лихи
- Масштабирование языковых моделей: методы, анализ и понимание от тренировок суслика: 2022
Джек У. Рей и Себастьян Борги и Тревор Кай ... 74 Скрытые ... Демис Хассабис и Корай Кавуккуоглу и Джеффри Ирвинг
- Гламур: Эффективное масштабирование языковых моделей с смешением экспертов: 2022
Du, Nan и Huang, Yanping и Dai, Andrew M ... 21 Hidden ... Wu, Yonghui и Chen, Zhifeng и Cui, Claire
- Крестовой надзор улучшает большие языковые модели перед тренировкой: 2023
Андреа Шиоппа и Ксавье Гарсия и Орхан Фират
- [Doge: Reviouding домена с оценкой обобщения] (https://arxiv.org/abs/arxiv Preprint): 2023
Simin Fan и Matteo Pagliardini и Martin Jaggi
- Дореми: оптимизация смесей данных ускоряет языковую модель, предварительно подготовка: 2023
Санг Майкл Си и Хие Фам и Сюанья Донг ... 4 Скрытые ... Quoc V le и Tengyu Ma и Adams Wei Yu
- Эффективное смешивание данных в Интернете для языковой модели перед тренировкой: 2023
Алон Альбалак и Лянгинг Пан, Колин Раффел и Уильям Ян Ванг
- Лама: открытые и эффективные основополагающие языковые модели: 2023
Хьюго Тувров и Тибо Лаврил и Гаутье Изакард ... 8 Скрытый ... Арманд Джулин и Эдуард Могила и Гийом Лобли
- Pythia: набор для анализа больших языковых моделей по всему обучению и масштабированию: 2023
Biderman, Stella and Schoelkopf, Hailey и Anthony, Quentin Gregory ... 7 Hidden ... Skowron, Aviya и Sutawika, Lintang и Van der Wal, Oskar
- Масштабирование языковых моделей, ограниченных данными: 2023
Никлас Мюеннгофф и Александр М Раш и Боаз Барак ... 3 Скрытые ... Сампо Писало и Томас Вольф и Колин Раффель
- Сдвиг лама: ускоряющая языковая модель предварительной тренировки через структурированную обрезку: 2023
Mengzhou Xia и Tianyu Gao и Zhiyuan Zeng и Danqi Chen
- Навык-это! Руководителем навыков, управляемой данными для понимания и обучения языковыми моделями: 2023
Майи Ф. Чен и Николас Робертс и Куш Бхатия ... 1 Скрытый ... Се Чжан и Фредерик Сала и Кристофер Рене
Выбор данных для настройки обучения и многозадачности
Вернуться к содержимому
- Decathlon The Natural Language: многозадачное обучение в качестве ответа на вопрос: 2018
Макканн, Брайан и Кескар, Нитиш Шириш и Сионг, Кайминг и Сохер, Ричард
- Объединяющий вопрос ответа, классификация текста и регрессия с помощью извлечения пролета: 2019
Кескар, Нитиш Шириш и Макканн, Брайан и Сионг, Кайминг и Сохер, Ричард
- Глубокие нейронные сети с несколькими задачами для понимания естественного языка: 2019
Лю, Сяодонг и он, Пенгчэн и Чен, Вейуху и Гао, Цзянфенг
- Unifiedqa: границы формата пересечения с одной системой QA: 2020
Хашаби, Даниэль и Мин, Сьюон и Хот, Тушар ... 1 Скрытый ... Тафджорд, Ойвинд и Кларк, Питер и Хаджисирзи, Ханнанех
- Изучение пределов обучения передачи с помощью единого трансформатора текста в текст: 2020
Раффель, Колин и Шазир, Ноам и Робертс, Адам ... 3 Скрытый ... Чжоу, Янки и Ли, Вэй и Лю, Питер Дж.
- Маппет: массивные многозадачные представления с предварительной финикой: 2021
Агаджаньян, Армен и Гупта, Анхит и Шривастава, Акшат и Чен, Ксилун и Зеттлемуер, Люк и Гупта, Сонал
- Созданные языковые модели-ученики с нулевым выстрелом: 2021
Вэй, Джейсон и Босма, Мартен и Чжао, Винсент Y .... 3 Скрытые ... DU, NAN и DAI, Эндрю М. и Ле, QUOC V.
- Обобщение по перекрестной задаче с помощью инструкций по краудсорсингу естественного языка: 2021
Мишра, Сваруп и Хашаби, Даниэль и Барал, Читта и Хаджисирзи, Ганнанех
- NL-Augmenter: основа для чувствительного к задачам увеличения естественного языка: 2021
Dhole, Kaustubh D и Gangal, Varun и Gehrmann, Sebastian ... 5 Hidden ... Shrivastava, Ashish and Tan, Samson и другие
- EXT5: к экстремальному масштабированию многозадачного обучения: 2021
Арибанди, Вамси и Тай, И и Шустер, Тал ... 5 Скрытый ... Бахри, Дара и Ни, Цзяньмо и другие
- Super-NaturalInstructions: обобщение с помощью декларативных инструкций по 1600+ Задачам NLP: 2022
Ван, Йизхонг и Мишра, Сваруп и Алипормолабаши, Пега ... 29 Скрытые ... Патро, Суманта и Диксит, Танай и Шен, Ксудон
- Масштабирование на фамилированных языковых моделях: 2022
Chung, Hyung Won и Hou, Le и Longpre, Shayne ... 5 Hidden ... Dehghani, Mashafa и Brahma, Siddhartha и других
- Bloom+ 1: Добавление языковой поддержки к цвету для получения нулевого выстрела: 2022
Йонг, Чжэн-Хин и Шоэлкопф, Хейли и Мененгофф, Никлас ... 5 Скрытые ... Касаи, Юнго и Барува, Ахмед и другие
- OPT-IML: масштабирование языковой модели инструкции Мета обучение через призму обобщения: 2022
Шринивасан Айер и Си Виктория Лин и Рамакант Пасунуру ... 12 Скрытый ... Асли Селикилмаз и Люк Зеттлемуер и Вес Стоянов
- Metaicl: Learning to Learning в контексте: 2022
Мин, Сьюон и Льюис, Майк и Зеттлемойер, Люк и Хаджисирзи, Ханнанех
- Неестественные инструкции: настройка языковых моделей с (почти) без человеческого труда: 2022
Хонович, или Скилом, Томас и Леви, Омер и Шик, Тимо
- Кросслинг -обобщение через многозадачное искусство: 2022
Мененгофф, Никлас и Ван, Томас и Сутавика, Линтанг ... 5 Скрытый ... Юн, Чжэн-Син и Шолкопф, Хейли и другие
- Многозадачная подготовка
Виктор Сан и Альберт Вебсон и Колин Раффел ... 34 Скрытые ... Лео Гао и Томас Вольф и Александр М.
- Прометей: вызывание мелкозернистой оценки в языковых моделях: 2023
Ким, Сейнгоне и Шин, Джамин и Чо, Еджин ... 5 Скрытый ... Ким, Сунгдонг и Торн, Джеймс и другие
- Slimorca: открытый набор данных следов рассуждений Augmented Flan GPT-4, с проверкой: 2023
Wing Lian и Guan Wang и Bleys Goodson ... 1 Скрытый ... Остин Кук и Чанвикет Вонг и "Тениум"
- Ай искусство крадет у художников?: 2023
Чейка, Кайл
- Пол Тремблей, Мона Авад против Openai, Inc. и др.: 2023
Савери, Джозеф Р. и Зирполи, Кадио и Янг, Кристофер К.Л. и МакМахон, Кэтлин Дж.
- Сделать большие языковые модели лучшими создателями данных: 2023
Ли, Дон-Хо и Пуджара, Джея и Сьюк, Мохит и Уайт, Райен и Джаухар, Суджай
- Коллекция FLAN: проектирование данных и методов для эффективной настройки инструкций: 2023
Shayne Longpre и Le Hou и Tu Vu ... 5 Скрытый ... Баррет Зоф и Джейсон Вэй и Адам Робертс
- Wizardlm: расширение возможностей моделей больших языков, чтобы следовать сложным инструкциям: 2023
Сюй, Кан и Солнце, Цинфенг и Чжэн, Кай ... 2 Скрытые ... Фэн, Цзяшан и Тао, Чонгьян и Цзян, Даксин
- Лима: меньше для выравнивания: 2023
Чунтинг Чжоу и Пенгфей Лю и Пуксин Сюй ... 9 Скрытый ... Майк Льюис и Люк Зеттлемуер и Омер Леви
- Верблюды в изменяющемся климате: усиление адаптации LM с Tulu 2: 2023
Хэмиш Ивисон и Йижонг Ван и Валентина Пьяткин ... 5 Скрытый ... Ноа А. Смит и Из -Белтаги и Ханнане Хаджиширзи
- Самоубийство: выравнивание языковых моделей с самостоятельными инструкциями: 2023
Ван, Йижонг и Корди, Йегане и Мишра, Сваруп ... 1 Скрытый ... Смит, Ноа А. и Хашаби, Даниэль и Хаджисирзи, Ханнанех
- Что делает хорошие данные для выравнивания? Комплексное исследование автоматического выбора данных в настройке инструкций: 2023
Лю, Вэй и Зенг, Вейхао и он, Кецин и Цзян, Юн и он, Джунсиан
- Настройка инструкции для больших языковых моделей: опрос: 2023
Shengyu Zhang и Linfeng Dong и Xiaoya Li ... 5 Hidden ... Tianwei Zhang и Fei Wu и Guoyin Wang
- Стэнфордская Альпака: инструкционная модель ламы: 2023
Рохан Таори и Ишаан Гулраджани и Тиани Чжан ... 2 Скрытые ... Карлос Гесстрин и Перси Лян и Тацунори Б. Хасимото
- Как далеко могут зайти верблюды? Изучение состояния настройки инструкций на открытых ресурсах: 2023
Йижонг Ван и Хэмиш Ивисон и Прадип Дасиги ... 5 Скрытый ... Ноа А. Смит и Из -Белтаги и Ханнане Хаджиширзи
- Открытые разговоры-демократизация крупного языкового выравнивания: 2023
K "Opf, Andreas and Kilcher, Yannic и Von R" Utte, Dimitri ... 5 Скрытый ... Стэнли, Оливер и Нагифи, Рич'ард и другие
- Octopack: код настройки инструкций
Никлас Мененгофф и Цянь Лю и Армель Зебазе ... 4 Скрытые ... Сянгра Тан и Леандро фон Верра и Шейн Лонгпри
- Самостоятельная эворация для самого эволюции для крупного языка: 2023
Лу, Цзяньцяо и Чжун, Ванджун и Хуанг, Венинг ... 3 Скрытые ... Ван, Вейчао и Шанг, Лифэнг и Лю, Кун
- Коллекция FLAN: проектирование данных и методов для эффективной настройки инструкций: 2023
Longpre, Shayne and Hou, Le и Vu, Tu ... 5 Hidden ... Zoph, Barret и Wei, Jason and Roberts, Adam
- #Instag: тегирование инструкций для анализа контролируемой тонкой настройки крупных языковых моделей: 2023
Кеминг Лу и Хонги Юань и Чжэн Юань ... 2 Скрытые ... Чуанки Тан и Чан Чжоу и Цзинрен Чжоу
- МАНПИСЬ ТРУЖЕНИЯ: Когда интеллектуальный анализ данных соответствует модели с большой языком: 2023
Yihan Cao и Yanbin Kang, Chi Wang и Lichao Sun
- Активная настройка инструкций: улучшение генерализации межзадачных задач путем обучения по быстрым чувствительным задачам: 2023
По-Ниен Кунг и Фан Инь и Ди Ву и Кай-Вей Чанг и Наньян Пенг
- Инициатива Provenance Data: крупномасштабный аудит лицензирования и атрибуции наборов данных в AI: 2023
Longpre, Shayne и Mahari, Robert и Chen, Энтони ... 5 Скрытый ... Каббара, Джейд и Перисетла, Картик и другие
- Набор данных AYA: коллекция с открытым доступом для многоязычной настройки инструкций: 2024
Шивалка Сингх и Фредди Варгус и Даниэль Дсуза ... 27 Скрытый ... Ахмет üstün и Марзи Фадаи и Сара Хукер
- Astraios: Параметр-экономичный код настройки инструкций. Большие языковые модели: 2024
Чжуо, Терри Юэ и Зебазе, Армель и Супаттарачай, Ничакарн ... 1 Скрытый ... де Врис, Хар и Лю, Цянь и Мененгофф, Никлас
- Модель AYA: Многоязычная языковая модель с открытым доступом модели: 2024
"UST" UN, AHMET и ARYABUMI, VIRAAT и YONG, ZHENG-XIN ... 5 Hidden ... Ooi, Hui-Lee и Kayid, AMR и другие
- Меньшие языковые модели способны выбирать данные об обучении настройки обучения для более крупных языковых моделей: 2024
Dheeraj Mekala и Alex Nguyen и Jingbo Shang
- Автоматизированное курирование данных для надежной языковой модели тонкая настройка: 2024
Джихай Чен и Джонас Мюллер
Выбор данных для предпочтения тонкая настройка: выравнивание
Вернуться к содержимому
- WebGPT: вопросы вопроса о браузере с обратной связью с человеком: 2021
Накано, Рейхиро и Хилтон, Джейкоб и Баладжи, Сучир ... 5 Скрытый ... Косараджу, Винет и Сондерс, Уильям и другие
- Обучение полезного и безвредного помощника по подкреплению, обучаясь на отзывах человека: 2022
Бай, Юнтао и Джонс, Энди и Ндуссе, Камал ... 5 Скрытый ... Гангули, Глубь и Хеньян, Том и другие
- Понимание сложности набора данных с помощью $ mathcalv $-пользовательской информации: 2022
Ethayarajh, Kawin и Choi, Yejin и Swayamdipta, Swabha
- Конституционный ИИ: Безвредность от обратной связи с ИИ: 2022
Бай, Юнтао и Кадават, Саурав и Кунду, Сандипан ... 5 Скрытые ... Мирхосейни, Азалия и МакКинвин, Кэмерон и другие
- Прометей: вызывание мелкозернистой оценки в языковых моделях: 2023
Ким, Сейнгоне и Шин, Джамин и Чо, Еджин ... 5 Скрытый ... Ким, Сунгдонг и Торн, Джеймс и другие
- НЕТ: 2023
Альваро Бартолом и Габриэль Мартин и Даниэль Вила
- Ultrafeedback: повышение языковых моделей с высококачественной обратной связью: 2023
Ganqu Cui and Lifan Yuan and Ning Ding... 3 hidden ... Guotong Xie and Zhiyuan Liu and Maosong Sun
- Exploration with Principles for Diverse AI Supervision: 2023
Liu, Hao and Zaharia, Matei and Abbeel, Pieter
- Wizardlm: Empowering large language models to follow complex instructions: 2023
Xu, Can and Sun, Qingfeng and Zheng, Kai... 2 hidden ... Feng, Jiazhan and Tao, Chongyang and Jiang, Daxin
- LIMA: Less Is More for Alignment: 2023
Chunting Zhou and Pengfei Liu and Puxin Xu... 9 hidden ... Mike Lewis and Luke Zettlemoyer and Omer Levy
- Shepherd: A Critic for Language Model Generation: 2023
Tianlu Wang and Ping Yu and Xiaoqing Ellen Tan... 4 hidden ... Luke Zettlemoyer and Maryam Fazel-Zarandi and Asli Celikyilmaz
- No Robots: 2023
Nazneen Rajani and Lewis Tunstall and Edward Beeching and Nathan Lambert and Alexander M. Rush and Thomas Wolf
- Starling-7B: Improving LLM Helpfulness & Harmlessness with RLAIF: 2023
Zhu, Banghua and Frick, Evan and Wu, Tianhao and Zhu, Hanlin and Jiao, Jiantao
- Scaling laws for reward model overoptimization: 2023
Gao, Leo and Schulman, John and Hilton, Jacob
- SALMON: Self-Alignment with Principle-Following Reward Models: 2023
Zhiqing Sun and Yikang Shen and Hongxin Zhang... 2 hidden ... David Cox and Yiming Yang and Chuang Gan
- Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback: 2023
Stephen Casper and Xander Davies and Claudia Shi... 26 hidden ... David Krueger and Dorsa Sadigh and Dylan Hadfield-Menell
- Camels in a Changing Climate: Enhancing LM Adaptation with Tulu 2: 2023
Hamish Ivison and Yizhong Wang and Valentina Pyatkin... 5 hidden ... Noah A. Smith and Iz Beltagy and Hannaneh Hajishirzi
- Llama 2: Open Foundation and Fine-Tuned Chat Models: 2023
Hugo Touvron and Louis Martin and Kevin Stone... 62 hidden ... Robert Stojnic and Sergey Edunov and Thomas Scialom
- What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning: 2023
Liu, Wei and Zeng, Weihao and He, Keqing and Jiang, Yong and He, Junxian
- HuggingFace H4 Stack Exchange Preference Dataset: 2023
Lambert, Nathan and Tunstall, Lewis and Rajani, Nazneen and Thrush, Tristan
- Textbooks Are All You Need: 2023
Gunasekar, Suriya and Zhang, Yi and Aneja, Jyoti... 5 hidden ... de Rosa, Gustavo and Saarikivi, Olli and others
- Quality-Diversity through AI Feedback: 2023
Herbie Bradley and Andrew Dai and Hannah Teufel... 4 hidden ... Kenneth Stanley and Grégory Schott and Joel Lehman
- Direct preference optimization: Your language model is secretly a reward model: 2023
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Ermon, Stefano and Manning, Christopher D and Finn, Chelsea
- Scaling relationship on learning mathematical reasoning with large language models: 2023
Yuan, Zheng and Yuan, Hongyi and Li, Chengpeng and Dong, Guanting and Tan, Chuanqi and Zhou, Chang
- The History and Risks of Reinforcement Learning and Human Feedback: 2023
Lambert, Nathan and Gilbert, Thomas Krendl and Zick, Tom
- Zephyr: Direct distillation of lm alignment: 2023
Tunstall, Lewis and Beeching, Edward and Lambert, Nathan... 5 hidden ... Fourrier, Cl'ementine and Habib, Nathan and others
- Perils of Self-Feedback: Self-Bias Amplifies in Large Language Models: 2024
Wenda Xu and Guanglei Zhu and Xuandong Zhao and Liangming Pan and Lei Li and William Yang Wang
- Suppressing Pink Elephants with Direct Principle Feedback: 2024
Louis Castricato and Nathan Lile and Suraj Anand and Hailey Schoelkopf and Siddharth Verma and Stella Biderman
- West-of-N: Synthetic Preference Generation for Improved Reward Modeling: 2024
Alizée Pace and Jonathan Mallinson and Eric Malmi and Sebastian Krause and Aliaksei Severyn
- Statistical Rejection Sampling Improves Preference Optimization: 2024
Liu, Tianqi and Zhao, Yao and Joshi, Rishabh... 1 hidden ... Saleh, Mohammad and Liu, Peter J and Liu, Jialu
- Self-play fine-tuning converts weak language models to strong language models: 2024
Chen, Zixiang and Deng, Yihe and Yuan, Huizhuo and Ji, Kaixuan and Gu, Quanquan
- Self-Rewarding Language Models: 2024
Weizhe Yuan and Richard Yuanzhe Pang and Kyunghyun Cho and Sainbayar Sukhbaatar and Jing Xu and Jason Weston
- Theoretical guarantees on the best-of-n alignment policy: 2024
Beirami, Ahmad and Agarwal, Alekh and Berant, Jonathan... 1 hidden ... Eisenstein, Jacob and Nagpal, Chirag and Suresh, Ananda Theertha
- KTO: Model Alignment as Prospect Theoretic Optimization: 2024
Ethayarajh, Kawin and Xu, Winnie and Muennighoff, Niklas and Jurafsky, Dan and Kiela, Douwe
Data Selection for In-Context Learning
Back to Table of Contents
- Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks: 2019
Reimers, Nils and Gurevych, Iryna
- Language Models are Few-Shot Learners: 2020
Brown, Tom and Mann, Benjamin and Ryder, Nick... 25 hidden ... Radford, Alec and Sutskever, Ilya and Amodei, Dario
- True Few-Shot Learning with Language Models: 2021
Ethan Perez and Douwe Kiela and Kyunghyun Cho
- Active Example Selection for In-Context Learning: 2022
Zhang, Yiming and Feng, Shi and Tan, Chenhao
- Careful Data Curation Stabilizes In-context Learning: 2022
Chang, Ting-Yun and Jia, Robin
- Learning To Retrieve Prompts for In-Context Learning: 2022
Rubin, Ohad and Herzig, Jonathan and Berant, Jonathan
- Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity: 2022
Lu, Yao and Bartolo, Max and Moore, Alastair and Riedel, Sebastian and Stenetorp, Pontus
- What Makes Good In-Context Examples for GPT-3?: 2022
Liu, Jiachang and Shen, Dinghan and Zhang, Yizhe and Dolan, Bill and Carin, Lawrence and Chen, Weizhu
- MetaICL: Learning to Learn In Context: 2022
Min, Sewon and Lewis, Mike and Zettlemoyer, Luke and Hajishirzi, Hannaneh
- Unified Demonstration Retriever for In-Context Learning: 2023
Li, Xiaonan and Lv, Kai and Yan, Hang... 3 hidden ... Xie, Guotong and Wang, Xiaoling and Qiu, Xipeng
- Which Examples to Annotate for In-Context Learning? Towards Effective and Efficient Selection: 2023
Mavromatis, Costas and Srinivasan, Balasubramaniam and Shen, Zhengyuan... 1 hidden ... Rangwala, Huzefa and Faloutsos, Christos and Karypis, George
- Large Language Models Are Latent Variable Models: Explaining and Finding Good Demonstrations for In-Context Learning: 2023
Xinyi Wang and Wanrong Zhu and Michael Saxon and Mark Steyvers and William Yang Wang
- Selective Annotation Makes Language Models Better Few-Shot Learners: 2023
Hongjin SU and Jungo Kasai and Chen Henry Wu... 5 hidden ... Luke Zettlemoyer and Noah A. Smith and Tao Yu
- In-context Example Selection with Influences: 2023
Nguyen, Tai and Wong, Eric
- Coverage-based Example Selection for In-Context Learning: 2023
Gupta, Shivanshu and Singh, Sameer and Gardner, Matt
- Compositional exemplars for in-context learning: 2023
Ye, Jiacheng and Wu, Zhiyong and Feng, Jiangtao and Yu, Tao and Kong, Lingpeng
- Take one step at a time to know incremental utility of demonstration: An analysis on reranking for few-shot in-context learning: 2023
Hashimoto, Kazuma and Raman, Karthik and Bendersky, Michael
- Ambiguity-aware in-context learning with large language models: 2023
Gao, Lingyu and Chaudhary, Aditi and Srinivasan, Krishna and Hashimoto, Kazuma and Raman, Karthik and Bendersky, Michael
- IDEAL: Influence-Driven Selective Annotations Empower In-Context Learners in Large Language Models: 2023
Zhang, Shaokun and Xia, Xiaobo and Wang, Zhaoqing... 1 hidden ... Liu, Jiale and Wu, Qingyun and Liu, Tongliang
- ScatterShot: Interactive In-context Example Curation for Text Transformation: 2023
Wu, Sherry and Shen, Hua and Weld, Daniel S and Heer, Jeffrey and Ribeiro, Marco Tulio
- Diverse Demonstrations Improve In-context Compositional Generalization: 2023
Levy, Itay and Bogin, Ben and Berant, Jonathan
- Finding supporting examples for in-context learning: 2023
Li, Xiaonan and Qiu, Xipeng
- Misconfidence-based Demonstration Selection for LLM In-Context Learning: 2024
Xu, Shangqing and Zhang, Chao
- In-context Learning with Retrieved Demonstrations for Language Models: A Survey: 2024
Xu, Xin and Liu, Yue and Pasupat, Panupong and Kazemi, Mehran and others
Data Selection for Task-specific Fine-tuning
Back to Table of Contents
- A large annotated corpus for learning natural language inference: 2015
Bowman, Samuel R. and Angeli, Gabor and Potts, Christopher and Manning, Christopher D.
- GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding: 2018
Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel
- A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference: 2018
Williams, Adina and Nangia, Nikita and Bowman, Samuel
- Sentence Encoders on STILTs: Supplementary Training on Intermediate Labeled-data Tasks: 2019
Jason Phang and Thibault Févry and Samuel R. Bowman
- Distributionally Robust Neural Networks: 2020
Shiori Sagawa and Pang Wei Koh and Tatsunori B. Hashimoto and Percy Liang
- Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics: 2020
Swayamdipta, Swabha and Schwartz, Roy and Lourie, Nicholas... 1 hidden ... Hajishirzi, Hannaneh and Smith, Noah A. and Choi, Yejin
- Intermediate-Task Transfer Learning with Pretrained Language Models: When and Why Does It Work?: 2020
Pruksachatkun, Yada and Phang, Jason and Liu, Haokun... 3 hidden ... Vania, Clara and Kann, Katharina and Bowman, Samuel R.
- On the Complementarity of Data Selection and Fine Tuning for Domain Adaptation: 2021
Dan Iter and David Grangier
- FETA: A Benchmark for Few-Sample Task Transfer in Open-Domain Dialogue: 2022
Albalak, Alon and Tuan, Yi-Lin and Jandaghi, Pegah... 3 hidden ... Getoor, Lise and Pujara, Jay and Wang, William Yang
- LoRA: Low-Rank Adaptation of Large Language Models: 2022
Edward J Hu and yelong shen and Phillip Wallis... 2 hidden ... Shean Wang and Lu Wang and Weizhu Chen
- Training Subset Selection for Weak Supervision: 2022
Lang, Hunter and Vijayaraghavan, Aravindan and Sontag, David
- On-Demand Sampling: Learning Optimally from Multiple Distributions: 2022
Haghtalab, Nika and Jordan, Michael and Zhao, Eric
- The Trade-offs of Domain Adaptation for Neural Language Models: 2022
Grangier, David and Iter, Dan
- Data Pruning for Efficient Model Pruning in Neural Machine Translation: 2023
Azeemi, Abdul and Qazi, Ihsan and Raza, Agha
- Skill-it! A Data-Driven Skills Framework for Understanding and Training Language Models: 2023
Mayee F. Chen and Nicholas Roberts and Kush Bhatia... 1 hidden ... Ce Zhang and Frederic Sala and Christopher Ré
- D2 Pruning: Message Passing for Balancing Diversity and Difficulty in Data Pruning: 2023
Adyasha Maharana and Prateek Yadav and Mohit Bansal
- Improving Few-Shot Generalization by Exploring and Exploiting Auxiliary Data: 2023
Alon Albalak and Colin Raffel and William Yang Wang
- Efficient Online Data Mixing For Language Model Pre-Training: 2023
Alon Albalak and Liangming Pan and Colin Raffel and William Yang Wang
- Data-Efficient Finetuning Using Cross-Task Nearest Neighbors: 2023
Ivison, Hamish and Smith, Noah A. and Hajishirzi, Hannaneh and Dasigi, Pradeep
- Make Every Example Count: On the Stability and Utility of Self-Influence for Learning from Noisy NLP Datasets: 2023
Bejan, Irina and Sokolov, Artem and Filippova, Katja
- LESS: Selecting Influential Data for Targeted Instruction Tuning: 2024
Mengzhou Xia and Sadhika Malladi and Suchin Gururangan and Sanjeev Arora and Danqi Chen
Вклад
There are likely some amazing works in the field that we missed, so please contribute to the repo.
Feel free to open a pull request with new papers or create an issue and we can add them for you. Thank you in advance for your efforts!
Цитирование
We hope this work serves as inspiration for many impactful future works. If you found our work useful, please cite this paper as:
@article{albalak2024survey,
title={A Survey on Data Selection for Language Models},
author={Alon Albalak and Yanai Elazar and Sang Michael Xie and Shayne Longpre and Nathan Lambert and Xinyi Wang and Niklas Muennighoff and Bairu Hou and Liangming Pan and Haewon Jeong and Colin Raffel and Shiyu Chang and Tatsunori Hashimoto and William Yang Wang},
year={2024},
journal={arXiv preprint arXiv:2402.16827},
note={url{https://arxiv.org/abs/2402.16827}}
}


