Une enquête sur la sélection des données pour les modèles de langue
Ce repo est une liste pratique des articles pertinents pour la sélection des données pour les modèles de langue, à toutes les étapes de la formation. Ceci est censé être une ressource pour la communauté, alors veuillez contribuer si vous voyez quelque chose qui manque!
Pour plus de détails sur ces travaux, et plus encore, consultez notre document d'enquête: une enquête sur la sélection des données pour les modèles de langue. Par cette incroyable équipe: Alon Albalak, Yanai Elazar, a chanté Michael Xie, Shayne Longpre, Nathan Lambert, Xinyi Wang, Niklas Muennighoff, Bairu Hou, Liangming Pan, Haewon Jeong, Colin Raffel, Shiyu Chang, Tatsunori Hashimoto, William Yang Wang
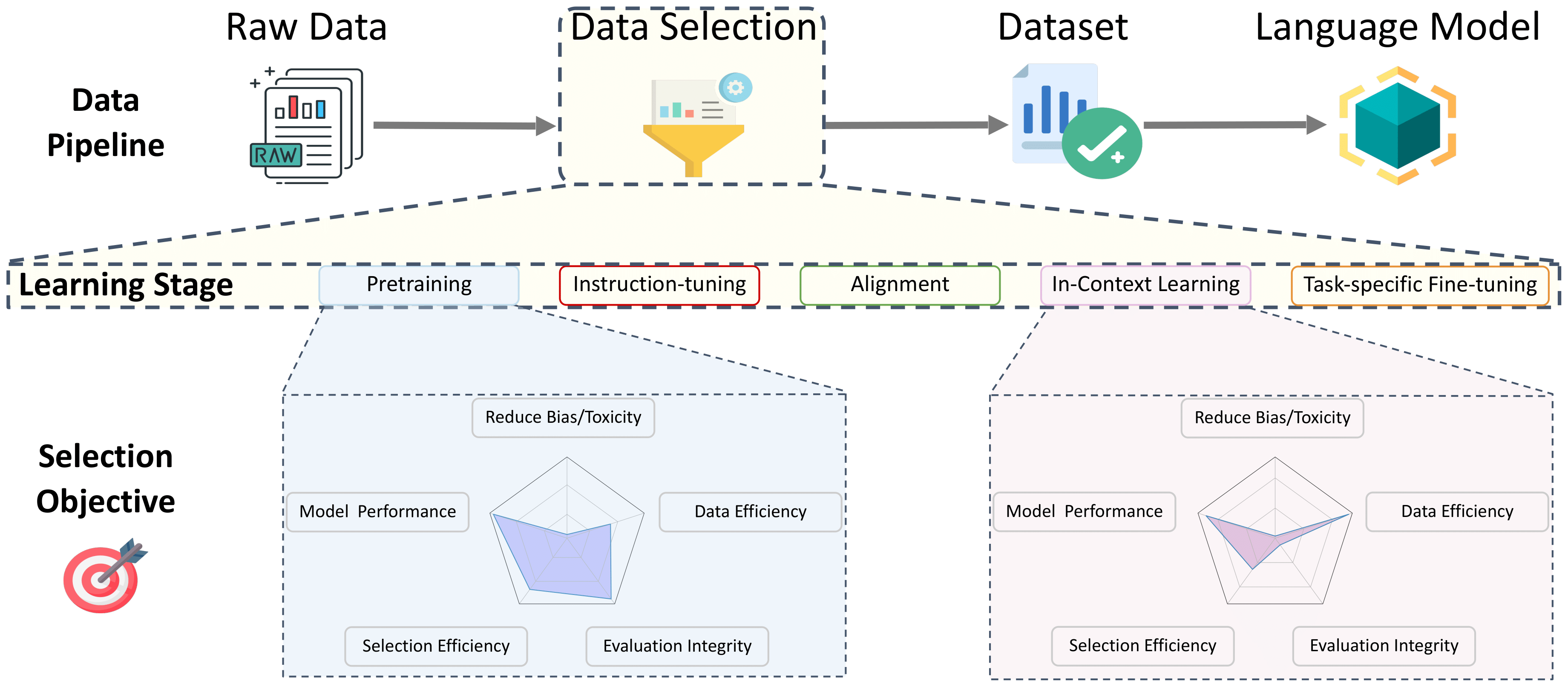
Table des matières
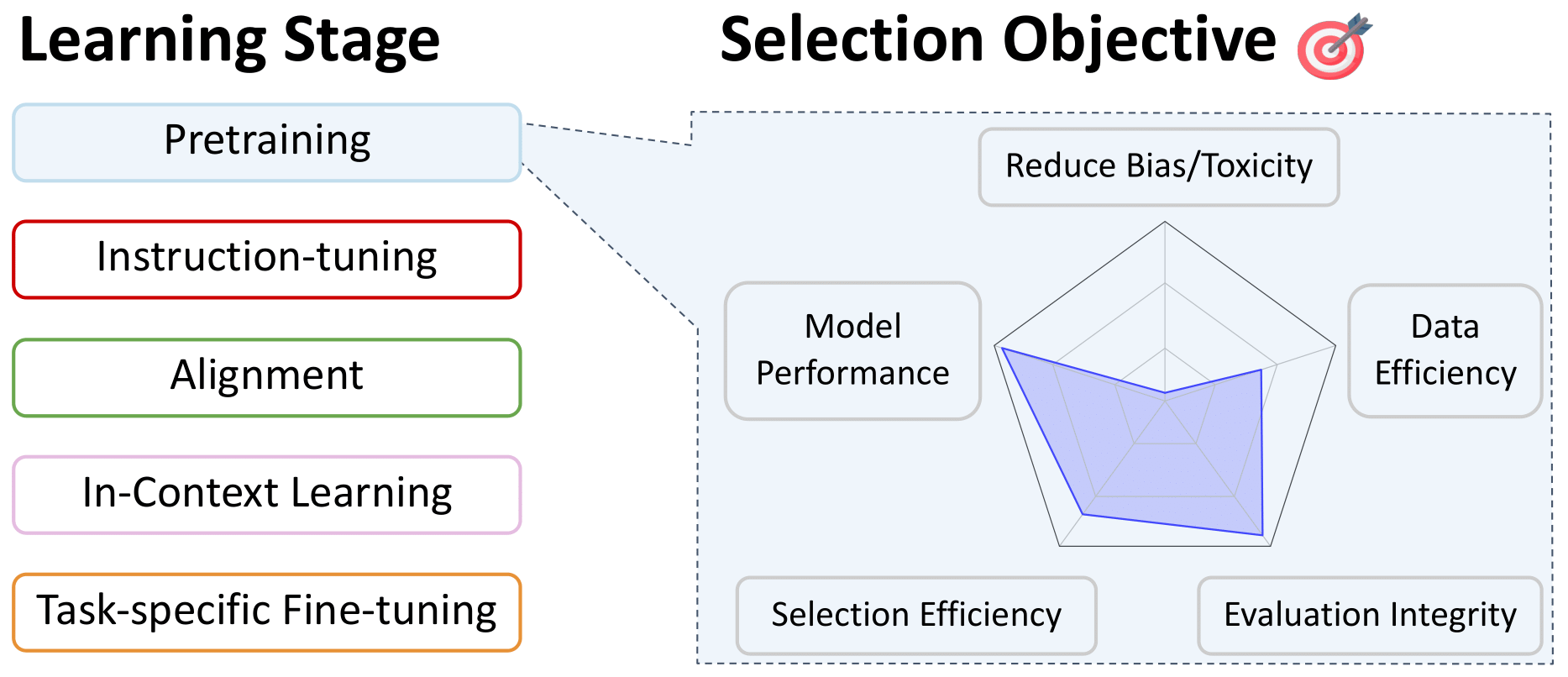
- Sélection de données pour pré-formation
- Filtrage linguistique
- Approches heuristiques
- Qualité des données
- Sélection spécifique au domaine
- Déduplication des données
- Filtrage du contenu toxique et explicite
- Sélection spécialisée pour les modèles multilingues
- Mélange de données
- Sélection des données pour le réglage de l'instruction et la formation multitâche
- Sélection des données pour l'alignement de réglage des préférences
- Sélection de données pour l'apprentissage en contexte
- Sélection de données pour un réglage fin spécifique à la tâche
Sélection de données pour pré-formation
Filtrage linguistique
Retour à la table des matières
- FastText.zip: Modèles de classification de texte de compression: 2016
Armand Joulin et Edouard Grave et Piotr Bojanowski et Matthijs Douze et Hérve Jégou et Tomas Mikolov
- Vecteurs de mots d'apprentissage pour 157 langues: 2018
Grave, Edouard et Bojanowski, Piotr et Gupta, Prakhar et Joulin, Armand et Mikolov, Tomas
- Modèle de langage inter-greffe Pré-formation: 2019
Conneau, Alexis et Lample, Guillaume
- Exploration des limites de l'apprentissage du transfert avec un transformateur de texte à texte unifié: 2020
Raffel, Colin et Shazeer, Noam et Roberts, Adam ... 3 Hidden ... Zhou, Yanqi et Li, Wei et Liu, Peter J.
- ID de langue dans la nature: défis inattendus sur le chemin de un Corpus de texte Web mille-language: 2020
Caswell, Isaac et Breiner, Theresa et Van Esch, Daan et Bapna, Ankur
- Représentation inter-linguale non supervisée Apprentissage à l'échelle: 2020
Conneau, Alexis et Khandelwal, Kartikay et Goyal, Naman ... 4 Hidden ... Ott, Myle et Zettlemoyer, Luke et Stoyanov, Veselin
- CCNET: Extraction d'ensembles de données monolingues de haute qualité à partir des données de crawl: 2020
Wenzek, Guillaume et Lachaux, Marie-Anne et Conneau, Alexis ... 1 Hidden ... Guzm'an, Francisco et Joulin, Armand et Grave, Edouard
- Une reproduction des modèles LSTM bidirectionnels d'Apple pour l'identification du langage dans les chaînes courtes: 2021
Toftrup, Mads et Asger Sorensen, Soren et Ciosici, Manuel R. et Assentiment, Ira
- Évaluation de modèles de grandes langues formés sur le code: 2021
Mark Chen et Jerry Tworek et Heewoo Jun ... 52 Hidden ... Sam McCandlish et Ilya Sutskever et Wojciech Zaremba
- MT5: Un transformateur de texte à texte pré-formé massivement multilingue: 2021
Xue, lineting et constant, Noah et Roberts, Adam ... 2 Hidden ... Siddhant, Aditya et Barua, Aditya et Raffel, Colin
- Génération de code au niveau de la compétition avec Alphacode: 2022
Li, Yujia et Choi, David et Chung, Junyoung ... 20 Hidden ... de Freitas, Nando et Kavukcuoglu, Koray et Vinyals, Oriol
- PAMPE: Échelle de la modélisation du langage avec des voies: 2022
Aakanksha Chowdhery et Sharan Narang et Jacob Devlin ... 61 Hidden ... Jeff Dean et Slav Petrov et Noah Fiedel
- The BigScience Roots Corpus: un ensemble de données multilingues composites de 1,6 To: 2022
Laurenccon, Hugo et Saulnier, Lucile et Wang, Thomas ... 48 Hidden ... Mitchell, Margaret et Luccioni, Sasha Alexandra et Jernite, Yacine
- Système d'écriture et métadonnées de haut-parleurs pour 2 800+ variétés de langue: 2022
Van Esch, Daan et Lucassen, Tamar et Ruder, Sebastian et Caswell, Isaac et Rivera, Clara
- Fingpt: GRANDS modèles génératifs pour une petite langue: 2023
Luukkonen, Risto et Komulainen, Ville et Luoma, Jouni ... 5 Hidden ... Muennighoff, Niklas et Piktus, Aleksandra et autres
- Mc ^ 2: un corpus multilingue des langues minoritaires en Chine: 2023
Zhang, Chen et Tao, Mingxu et Huang, Quzhe et Lin, Jiuheng et Chen, Zhibin et Feng, Yansong
- MADLAD-400: un ensemble de données vérifiées multiples et au niveau du document: 2023
Kudugunta, Sneha et Caswell, Isaac et Zhang, Biao ... 5 Hidden ... Stella, Romi et Bapna, Ankur et autres
- L'ensemble de données raffiné pour Falcon LLM: surperformant les corpus organisés avec des données Web et les données Web uniquement: 2023
Guilherme Penedo et Quentin Malartic et Daniel Hesslow ... 3 Hidden ... Baptiste Pannier et Ebtesam Almazrouei et Julien Launay
- Dolma: un corpus ouvert de trois billions de jetons pour le modèle de langue Recherche de pré-formation: 2024
Luca Soldaini et Rodney Kinney et Akshita Bhagia ... 30 Hidden ... Dirk Groeneveld et Jesse Dodge et Kyle Lo
Approches heuristiques
Retour à la table des matières
- Exploration des limites de l'apprentissage du transfert avec un transformateur de texte à texte unifié: 2020
Raffel, Colin et Shazeer, Noam et Roberts, Adam ... 3 Hidden ... Zhou, Yanqi et Li, Wei et Liu, Peter J.
- Les modèles de langue sont des apprenants à quelques tirs: 2020
Brown, Tom et Mann, Benjamin et Ryder, Nick ... 25 Hidden ... Radford, Alec et Sutskever, Ilya et Amodei, Dario
- La pile: un ensemble de données de 800 Go de texte diversifié pour la modélisation du langage: 2020
Leo Gao et Stella Biderman et Sid Black ... 6 Hidden ... Noa Nabeshima et Shawn Pressher et Connor Leahy
- Évaluation de modèles de grandes langues formés sur le code: 2021
Mark Chen et Jerry Tworek et Heewoo Jun ... 52 Hidden ... Sam McCandlish et Ilya Sutskever et Wojciech Zaremba
- MT5: Un transformateur de texte à texte pré-formé massivement multilingue: 2021
Xue, lineting et constant, Noah et Roberts, Adam ... 2 Hidden ... Siddhant, Aditya et Barua, Aditya et Raffel, Colin
- Modèles de langage d'échelle: méthodes, analyse et perspectives de la formation Gopher: 2022
Jack W. Rae et Sebastian Borgeaud et Trevor Cai ... 74 Hidden ... Demis Hassabis et Koray Kavukcuoglu et Geoffrey Irving
- The BigScience Roots Corpus: un ensemble de données multilingues composites de 1,6 To: 2022
Laurenccon, Hugo et Saulnier, Lucile et Wang, Thomas ... 48 Hidden ... Mitchell, Margaret et Luccioni, Sasha Alexandra et Jernite, Yacine
- HTLM: pré-formation hyper-texte et invitation des modèles de langue: 2022
Armen Aghajanyan et Dmytro Okhonko et Mike Lewis ... 1 Hidden ... Hu Xu et Gargi Ghosh et Luke Zettlemoyer
- LLAMA: Modèles de langue de base ouverts et efficaces: 2023
Hugo Touvron et Thibaut Lavril et Gautier Izacard ... 8 Hidden ... Armand Joulin et Edouard Grave et Guillaume Lample
- L'ensemble de données raffiné pour Falcon LLM: surperformant les corpus organisés avec des données Web et les données Web uniquement: 2023
Guilherme Penedo et Quentin Malartic et Daniel Hesslow ... 3 Hidden ... Baptiste Pannier et Ebtesam Almazrouei et Julien Launay
- L'indice de transparence du modèle de fondation: 2023
Bommasani, Rishi et Klyman, Kevin et Longpre, Shayne ... 2 Hidden ... Xiong, Betty et Zhang, Daniel et Liang, Percy
- Dolma: un corpus ouvert de trois billions de jetons pour le modèle de langue Recherche de pré-formation: 2024
Luca Soldaini et Rodney Kinney et Akshita Bhagia ... 30 Hidden ... Dirk Groeneveld et Jesse Dodge et Kyle Lo
Qualité des données
Retour à la table des matières
- Kenlm: Requêtes de modèle de langue plus rapide et plus petite: 2011
Hefield, Kenneth
- FastText.zip: Modèles de classification de texte de compression: 2016
Armand Joulin et Edouard Grave et Piotr Bojanowski et Matthijs Douze et Hérve Jégou et Tomas Mikolov
- Vecteurs de mots d'apprentissage pour 157 langues: 2018
Grave, Edouard et Bojanowski, Piotr et Gupta, Prakhar et Joulin, Armand et Mikolov, Tomas
- Les modèles linguistiques sont des apprenants multitâches non surveillés: 2019
Alec Radford et Jeff Wu et Rewon Child et David Luan et Dario Amodei et Ilya Sutskever
- Les modèles de langue sont des apprenants à quelques tirs: 2020
Brown, Tom et Mann, Benjamin et Ryder, Nick ... 25 Hidden ... Radford, Alec et Sutskever, Ilya et Amodei, Dario
- La pile: un ensemble de données de 800 Go de texte diversifié pour la modélisation du langage: 2020
Leo Gao et Stella Biderman et Sid Black ... 6 Hidden ... Noa Nabeshima et Shawn Pressher et Connor Leahy
- CCNET: Extraction d'ensembles de données monolingues de haute qualité à partir des données de crawl: 2020
Wenzek, Guillaume et Lachaux, Marie-Anne et Conneau, Alexis ... 1 Hidden ... Guzm'an, Francisco et Joulin, Armand et Grave, Edouard
- Détoxifier les modèles de langue risque marginalisant les voix des minorités: 2021
Xu, Albert et Pathak, Eshaan et Wallace, Eric et Gururangan, Suchin et Sap, Maarten et Klein, Dan
- PAMPE: Échelle de la modélisation du langage avec des voies: 2022
Aakanksha Chowdhery et Sharan Narang et Jacob Devlin ... 61 Hidden ... Jeff Dean et Slav Petrov et Noah Fiedel
- Modèles de langage d'échelle: méthodes, analyse et perspectives de la formation Gopher: 2022
Jack W. Rae et Sebastian Borgeaud et Trevor Cai ... 74 Hidden ... Demis Hassabis et Koray Kavukcuoglu et Geoffrey Irving
- Dont la langue compte comme une qualité élevée? Mesurer les idéologies linguistiques dans la sélection des données texte: 2022
Gururangan, Suchin and Card, Dallas et Dreier, Sarah ... 2 Hidden ... Wang, Zeyu et Zettlemoyer, Luke et Smith, Noah A.
- GLAM: échelle efficace des modèles de langage avec mélange des experts: 2022
Du, Nan et Huang, Yanping et Dai, Andrew M ... 21 Hidden ... Wu, Yonghui et Chen, Zhifeng et Cui, Claire
- Guide d'un prétraiteur pour la formation des données: Mesurer les effets de l'âge des données, de la couverture du domaine, de la qualité et de la toxicité: 2023
Shayne Longpre et Gregory Yauney et Emily Reif ... 5 Hidden ... Kevin Robinson et David Mimno et Daphne Ippolito
- Sélection de données pour les modèles de langage via un rééchantillonnage d'importance: 2023
Sang Michael Xie et Shibani Santurkar et Tengyu Ma et Percy Liang
- L'ensemble de données raffiné pour Falcon LLM: surperformant les corpus organisés avec des données Web et les données Web uniquement: 2023
Guilherme Penedo et Quentin Malartic et Daniel Hesslow ... 3 Hidden ... Baptiste Pannier et Ebtesam Almazrouei et Julien Launay
- Dolma: un corpus ouvert de trois billions de jetons pour le modèle de langue Recherche de pré-formation: 2024
Luca Soldaini et Rodney Kinney et Akshita Bhagia ... 30 Hidden ... Dirk Groeneveld et Jesse Dodge et Kyle Lo
- Programmation de chaque exemple: levage de la qualité des données pré-formation comme des experts à l'échelle: 2024
Fan Zhou et Zengzhi Wang et Qian Liu et Junlong Li et Pengfei Liu
Sélection spécifique au domaine
Retour à la table des matières
- Acquisition de données texte pour les modèles de langage spécifiques au domaine: 2006
Sethy, Abhinav et Georgiou, Panayiotis G. et Narayanan, Shrikanth
- Sélection intelligente des données de formation du modèle de langue: 2010
Moore, Robert C. et Lewis, William
- Sélection cynique des données de formation du modèle de langue: 2017
Axelrod d'Amittai
- Sélection automatique des documents pour un encodeur efficace Pretoring: 2022
Feng, Yukun et Xia, Patrick et Van Durme, Benjamin et Sedoc, Jo ~ ao
- Sélection de données pour les modèles de langage via un rééchantillonnage d'importance: 2023
Sang Michael Xie et Shibani Santurkar et Tengyu Ma et Percy Liang
- DSDM: Sélection du jeu de données Aware-Aware avec DataModels: 2024
Logan Engstrom et Axel Feldmann et Aleksander Madry
Déduplication des données
Retour à la table des matières
- Compromis espace / temps dans le codage de hachage avec des erreurs autorisées: 1970
Bloom, Burton H.
- Associations de suffixe: une nouvelle méthode pour les recherches de chaînes en ligne: 1993
Manber, Udi et Myers, Gene
- Sur la ressemblance et le confinement des documents: 1997
Broder, AZ
- Techniques d'estimation de similitude à partir d'algorithmes d'arrondi: 2002
Charikar, Moses S.
- Normalisation de l'URL pour la déshabitation des pages Web: 2009
Agarwal, Amit et Koppula, Hema Swetha et Leela, Krishna P .... 3 Hidden ... Haty, Chittaranjan et Roy, Anirban et Sasturkar, Amit
- Pipelines asynchrones pour traiter d'énormes corpus sur des infrastructures de ressources moyennes à faibles: 2019
Pedro Javier Ortiz Su'arez et Beno ^ It Sagot et Laurent Romaire
- Les modèles de langue sont des apprenants à quelques tirs: 2020
Brown, Tom et Mann, Benjamin et Ryder, Nick ... 25 Hidden ... Radford, Alec et Sutskever, Ilya et Amodei, Dario
- La pile: un ensemble de données de 800 Go de texte diversifié pour la modélisation du langage: 2020
Leo Gao et Stella Biderman et Sid Black ... 6 Hidden ... Noa Nabeshima et Shawn Pressher et Connor Leahy
- CCNET: Extraction d'ensembles de données monolingues de haute qualité à partir des données de crawl: 2020
Wenzek, Guillaume et Lachaux, Marie-Anne et Conneau, Alexis ... 1 Hidden ... Guzm'an, Francisco et Joulin, Armand et Grave, Edouard
- Au-delà des lois sur l'échelle neuronale: la mise à l'échelle de la loi du pouvoir de battre via l'élagage des données: 2022
Ben Sorscher et Robert Geirhos et Shashank Shekhar et Surya Ganguli et Ari S. Morcos
- La déduplication des données de formation rend les modèles de langage meilleurs: 2022
Lee, Katherine et Ippolito, Daphne et Nystrom, Andrew ... 1 Hidden ... Eck, Douglas et Callison-Burch, Chris et Carlini, Nicholas
- MTEB: Texte massif Intégration de référence: 2022
Muennighoff, Niklas et Tazi, Nouamane et Magne, lo "ic et reimers, nils
- PAMPE: Échelle de la modélisation du langage avec des voies: 2022
Aakanksha Chowdhery et Sharan Narang et Jacob Devlin ... 61 Hidden ... Jeff Dean et Slav Petrov et Noah Fiedel
- Modèles de langage d'échelle: méthodes, analyse et perspectives de la formation Gopher: 2022
Jack W. Rae et Sebastian Borgeaud et Trevor Cai ... 74 Hidden ... Demis Hassabis et Koray Kavukcuoglu et Geoffrey Irving
- SGPT: GPT Embeddings de phrases pour la recherche sémantique: 2022
Muennighoff, Niklas
- The BigScience Roots Corpus: un ensemble de données multilingues composites de 1,6 To: 2022
Laurenccon, Hugo et Saulnier, Lucile et Wang, Thomas ... 48 Hidden ... Mitchell, Margaret et Luccioni, Sasha Alexandra et Jernite, Yacine
- C-Pack: Ressources emballées pour faire progresser l'intégration générale chinoise: 2023
Xiao, Shitao et Liu, Zheng et Zhang, Peitian et Muennighoff, Niklas
- D4: Amélioration de la pré-élaction de LLM via le document De-Duplication and Diversification: 2023
Kushal Tirumala et Daniel Simig et Armen Aghajanyan et Ari S. Morcos
- À grande échelle quasi-déduplication derrière BigCode: 2023
Mou, Chenghao
- Paloma: une référence pour évaluer l'ajustement du modèle de langue: 2023
Ian Magnusson et Akshita Bhagia et Valentin Hofmann ... 10 Hidden ... Noah A. Smith et Kyle Richardson et Jesse Dodge
- Quantification de la mémorisation sur les modèles de langage neuronal: 2023
Nicholas Carlini et Daphne Ippolito et Matthew Jagielski et Katherine Lee et Florian Tramer et Chiyuan Zhang
- SemDedup: apprentissage économe en données à l'échelle du Web par le biais de déduplication sémantique: 2023
Abbas, Amro et Tirumala, Kushal et Simig, D'Aniel et Ganguli, Surya et Morcos, Ari S
- L'ensemble de données raffiné pour Falcon LLM: surperformant les corpus organisés avec des données Web et les données Web uniquement: 2023
Guilherme Penedo et Quentin Malartic et Daniel Hesslow ... 3 Hidden ... Baptiste Pannier et Ebtesam Almazrouei et Julien Launay
- Qu'y a-t-il dans mes mégadonnées ?: 2023
Elazar, Yanai et Bhagia, Akshita et Magnusson, Ian ... 5 Hidden ... Soldaini, Luca et Singh, Sameer et autres
- Dolma: un corpus ouvert de trois billions de jetons pour le modèle de langue Recherche de pré-formation: 2024
Luca Soldaini et Rodney Kinney et Akshita Bhagia ... 30 Hidden ... Dirk Groeneveld et Jesse Dodge et Kyle Lo
- Réglage de l'instruction de représentation générative: 2024
Muennighoff, Niklas et Su, Hongjin et Wang, Liang ... 2 Hidden ... Yu, Tao et Singh, Amanpreet et Kiela, Douwe
Filtrage du contenu toxique et explicite
Retour à la table des matières
- Exploration des limites de l'apprentissage du transfert avec un transformateur de texte à texte unifié: 2020
Raffel, Colin et Shazeer, Noam et Roberts, Adam ... 3 Hidden ... Zhou, Yanqi et Li, Wei et Liu, Peter J.
- MT5: Un transformateur de texte à texte pré-formé massivement multilingue: 2021
Xue, lineting et constant, Noah et Roberts, Adam ... 2 Hidden ... Siddhant, Aditya et Barua, Aditya et Raffel, Colin
- Perplexe par la qualité: une méthode basée sur la perplexité pour la détection de contenu adulte et nocif dans les données Web hétérogènes multilingues: 2022
Tim Jansen et Yangling Tong et Victoria Zevallos et Pedro Ortiz Suarez
- Modèles de langage d'échelle: méthodes, analyse et perspectives de la formation Gopher: 2022
Jack W. Rae et Sebastian Borgeaud et Trevor Cai ... 74 Hidden ... Demis Hassabis et Koray Kavukcuoglu et Geoffrey Irving
- The BigScience Roots Corpus: un ensemble de données multilingues composites de 1,6 To: 2022
Laurenccon, Hugo et Saulnier, Lucile et Wang, Thomas ... 48 Hidden ... Mitchell, Margaret et Luccioni, Sasha Alexandra et Jernite, Yacine
- Dont la langue compte comme une qualité élevée? Mesurer les idéologies linguistiques dans la sélection des données texte: 2022
Gururangan, Suchin and Card, Dallas et Dreier, Sarah ... 2 Hidden ... Wang, Zeyu et Zettlemoyer, Luke et Smith, Noah A.
- Guide d'un prétraiteur pour la formation des données: Mesurer les effets de l'âge des données, de la couverture du domaine, de la qualité et de la toxicité: 2023
Shayne Longpre et Gregory Yauney et Emily Reif ... 5 Hidden ... Kevin Robinson et David Mimno et Daphne Ippolito
- L'ensemble de données de formation d'image IA a été trouvé pour inclure l'imagerie des abus sexuels sur les enfants: 2023
David, Emilia
- Détection d'informations personnelles dans la formation des corpus: Analyse: 2023
Subramani, Nishant et Luccioni, Sasha et Dodge, Jesse et Mitchell, Margaret
- Rapport technique GPT-4: 2023
Openai et: et Josh Achiam ... 276 Hidden ... Juntang Zhuang et William Zhuk et Barret Zoph
- Santacoder: N'atteignez pas les étoiles !: 2023
Allal, Loubna Ben et Li, Raymond et Kocetkov, Denis ... 5 Hidden ... Gu, Alex et Dey, Manan et autres
- L'ensemble de données raffiné pour Falcon LLM: surperformant les corpus organisés avec des données Web et les données Web uniquement: 2023
Guilherme Penedo et Quentin Malartic et Daniel Hesslow ... 3 Hidden ... Baptiste Pannier et Ebtesam Almazrouei et Julien Launay
- L'indice de transparence du modèle de fondation: 2023
Bommasani, Rishi et Klyman, Kevin et Longpre, Shayne ... 2 Hidden ... Xiong, Betty et Zhang, Daniel et Liang, Percy
- Qu'y a-t-il dans mes mégadonnées ?: 2023
Elazar, Yanai et Bhagia, Akshita et Magnusson, Ian ... 5 Hidden ... Soldaini, Luca et Singh, Sameer et autres
- Dolma: un corpus ouvert de trois billions de jetons pour le modèle de langue Recherche de pré-formation: 2024
Luca Soldaini et Rodney Kinney et Akshita Bhagia ... 30 Hidden ... Dirk Groeneveld et Jesse Dodge et Kyle Lo
- Olmo: Accélération de la science des modèles de langue: 2024
Groeneveld, Dirk et Beltagy, Iz et Walsh, Pete ... 5 Hidden ... Magnusson, Ian et Wang, Yizhong et autres
Sélection spécialisée pour les modèles multilingues
Retour à la table des matières
- BLOOM: A 176B Paramètre Modèle de langue multilingue-accès: 2022
Atelier, BigScience et Scao, Teven Le et fan, Angela ... 5 Hidden ... Luccioni, Alexandra Sasha et Yvon, Franccois et autres
- Qualité en un coup d'œil: un audit des ensembles de données multilingues raffinés par le Web: 2022
Kreutzer, Julia et Caswell, Isaac et Wang, Lisa ... 46 Hidden ... Ahia, Oghenefego et Agrawal, Sweta et Adeyemi, Mofetoluwa
- The BigScience Roots Corpus: un ensemble de données multilingues composites de 1,6 To: 2022
Laurenccon, Hugo et Saulnier, Lucile et Wang, Thomas ... 48 Hidden ... Mitchell, Margaret et Luccioni, Sasha Alexandra et Jernite, Yacine
- Quel modèle de langue s'entraîner si vous avez un million d'heures de GPU ?: 2022
Scao, Teven Le et Wang, Thomas et Hesslow, Daniel ... 5 Hidden ... Muennighoff, Niklas et Phang, Jason et autres
- MADLAD-400: un ensemble de données vérifiées multiples et au niveau du document: 2023
Kudugunta, Sneha et Caswell, Isaac et Zhang, Biao ... 5 Hidden ... Stella, Romi et Bapna, Ankur et autres
- Échelle des modèles de langage multilingue sous des données contraises: 2023
Scao, teven le
- Ensemble de données AYA: une collection à accès ouvert pour le réglage des instructions multilingues: 2024
Shivalika Singh et Freddie Vargus et Daniel Dsouza ... 27 Hidden ... Ahmet üstün et Marzieh Fadadee et Sara Hooker
Mélange de données
Retour à la table des matières
- Le problème du bandit multiaire non stochastique: 2002
Auer, Peter et Cesa-Bianchi, Nicol`o et Freund, Yoav et Schapire, Robert E.
- Modélisation du langage robuste à distribution: 2019
Oren, Yonatan et Sagawa, Shiori et Hashimoto, Tatsunori B. et Liang, Percy
- Réseaux de neurones robustes distribués: 2020
Shiori Sagawa et Pang Wei Koh et Tatsunori B. Hashimoto et Percy Liang
- Exploration des limites de l'apprentissage du transfert avec un transformateur de texte à texte unifié: 2020
Raffel, Colin et Shazeer, Noam et Roberts, Adam ... 3 Hidden ... Zhou, Yanqi et Li, Wei et Liu, Peter J.
- La pile: un ensemble de données de 800 Go de texte diversifié pour la modélisation du langage: 2020
Leo Gao et Stella Biderman et Sid Black ... 6 Hidden ... Noa Nabeshima et Shawn Pressher et Connor Leahy
- Modèles de langage d'échelle: méthodes, analyse et perspectives de la formation Gopher: 2022
Jack W. Rae et Sebastian Borgeaud et Trevor Cai ... 74 Hidden ... Demis Hassabis et Koray Kavukcuoglu et Geoffrey Irving
- GLAM: échelle efficace des modèles de langage avec mélange des experts: 2022
Du, Nan et Huang, Yanping et Dai, Andrew M ... 21 Hidden ... Wu, Yonghui et Chen, Zhifeng et Cui, Claire
- La supervision interdiculée améliore les modèles de grands langues pré-formation: 2023
Andrea Schioppa et Xavier Garcia et Orhan Firat
- [DOGE: repondération du domaine avec l'estimation de la généralisation] (https://arxiv.org/abs/arxiv preprint): 2023
Fan Simin et Matteo Pagliardini et Martin Jaggi
- Doremi: Optimiser les mélanges de données accélère le modèle de langue pré-formation: 2023
Sang Michael Xie et Hieu Pham et Xuanyi Dong ... 4 Hidden ... Quoc V le et Tengyu Ma et Adams Wei Yu
- Mélange de données en ligne efficace pour le modèle de langue pré-formation: 2023
Alon Albalak et Liangming Pan et Colin Raffel et William Yang Wang
- LLAMA: Modèles de langue de base ouverts et efficaces: 2023
Hugo Touvron et Thibaut Lavril et Gautier Izacard ... 8 Hidden ... Armand Joulin et Edouard Grave et Guillaume Lample
- Pythie: une suite pour analyser les modèles de gros langues à travers la formation et la mise à l'échelle: 2023
Biderman, Stella et Schoelkopf, Hailey et Anthony, Quentin Gregory ... 7 Hidden ... Skowron, Aviya et Sutawika, Lintang et Van der Wal, Oskar
- Échelle des modèles de langage limité aux données: 2023
Niklas Muennighoff et Alexander M Rush et Boaz Barak ... 3 Hidden ... Sampo Pyysalo et Thomas Wolf et Colin Raffel
- Llama cisaillé: accélération du modèle de langue pré-formation via l'élagage structuré: 2023
Mengzhou Xia et Tianyu Gao et Zhiyuan Zeng et Danqi Chen
- Skill-it! Un cadre de compétences basé sur les données pour la compréhension et la formation des modèles de langue: 2023
Mayee F. Chen et Nicholas Roberts et Kush Bhatia ... 1 Hidden ... CE Zhang et Frederic Sala et Christopher Ré
Sélection des données pour le réglage de l'instruction et la formation multitâche
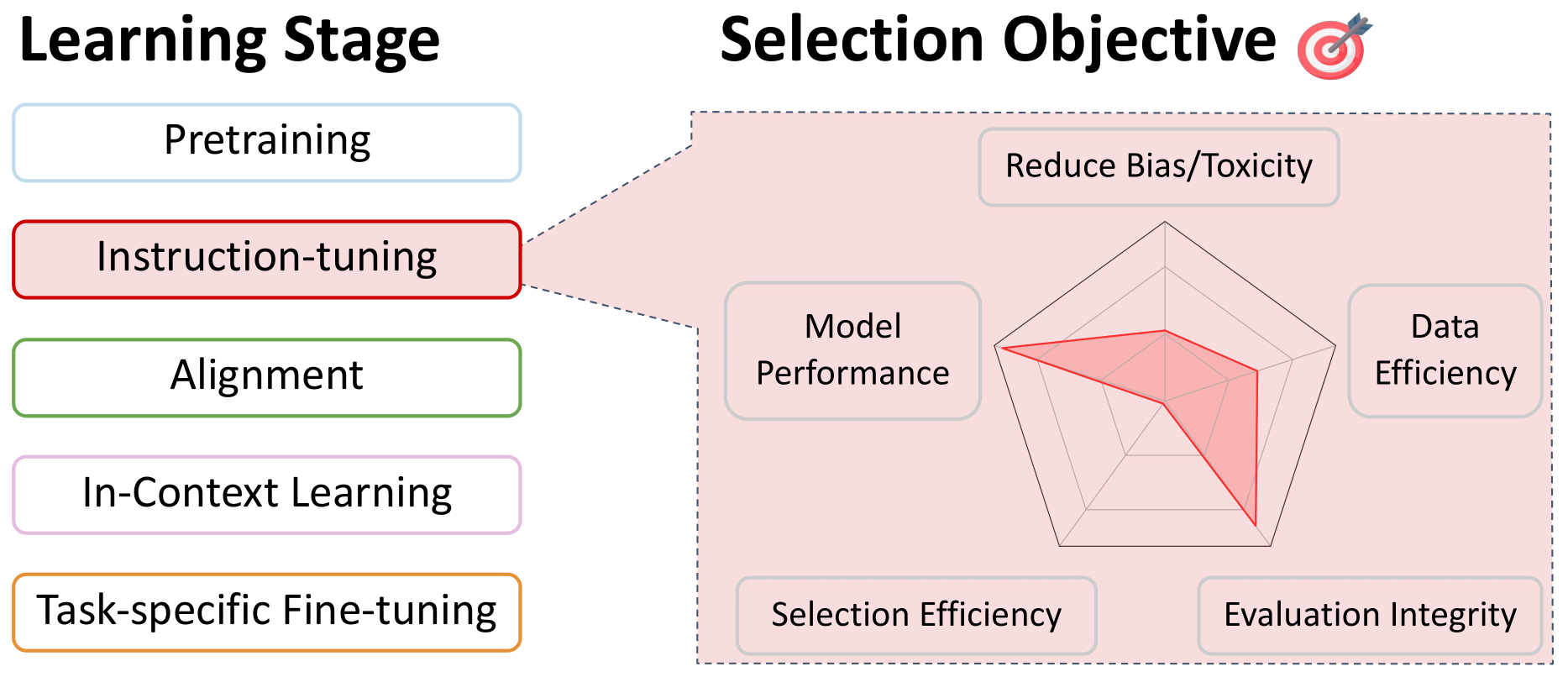
Retour à la table des matières
- The Natural Language Decathlon: Multitask Learning As Question Répondre: 2018
McCann, Bryan et Keskar, Nitish Shirish et Xiong, Caiming et Socher, Richard
- Réponse de question unificatrice, classification du texte et régression via l'extraction de Span: 2019
Keskar, Nitish Shirish et McCann, Bryan et Xiong, Caiming et Socher, Richard
- Réseaux de neurones profonds multi-tâches pour la compréhension du langage naturel: 2019
Liu, Xiaodong et lui, Pengcheng et Chen, Weizhu et Gao, Jianfeng
- UnifiedQA: Travette des limites du format avec un seul système QA: 2020
Khashabi, Daniel et Min, Sewon et Khot, Tushar ... 1 Hidden ... Tafjord, Oyvind et Clark, Peter et Hajishirzi, Hannaneh
- Exploration des limites de l'apprentissage du transfert avec un transformateur de texte à texte unifié: 2020
Raffel, Colin et Shazeer, Noam et Roberts, Adam ... 3 Hidden ... Zhou, Yanqi et Li, Wei et Liu, Peter J.
- Muppet: représentations massives multi-tâches avec pré-fintuning: 2021
Aghajanyan, Armen et Gupta, Anchit et Shrivastava, Akshat et Chen, Xilun et Zettlemoyer, Luke et Gupta, Sonal
- Les modèles de langage finetuné sont des apprenants à tirs zéro: 2021
Wei, Jason et Bosma, Maarten et Zhao, Vincent Y .... 3 Hidden ... Du, Nan et Dai, Andrew M. et Le, Quoc V.
- Généralisation de la tâche croisée via les instructions de crowdsourcing en langage naturel: 2021
Mishra, Swaroop et Khashabi, Daniel et Baral, Chitta et Hajishirzi, Hannaneh
- NL-Augmenter: Un cadre pour la tâche Augmentation du langage naturel sensible aux tâches: 2021
Dhole, Kaustubh D et Gangal, Varun et Gehrmann, Sebastian ... 5 Hidden ... Shrivastava, Ashish et Tan, Samson et autres
- EXT5: Vers une échelle extrême multi-tâches pour l'apprentissage du transfert: 2021
Aribandi, Vamsi et Tay, Yi et Schuster, Tal ... 5 Hidden ... Bahri, Dara et Ni, Jianmo et autres
- Super-Naturaline Inscriptions: Généralisation via des instructions déclaratives sur plus de 1600 tâches NLP: 2022
Wang, Yizhong et Mishra, Swaroop et Alipoormolabashi, Pegah ... 29 Hidden ... Patro, Sumanta et Dixit, Tanay et Shen, Xudong
- Échelle des modèles de langage au plateau d'instructions: 2022
Chung, Hyung Won et Hou, Le et Longpre, Shayne ... 5 Hidden ... Dehghani, Mosfa et Brahma, Siddhartha et autres
- Bloom + 1: Ajouter un support linguistique à Bloom pour une invitation à zéro: 2022
Yong, Zheng-Xin et Schoelkopf, Hailey et Muennighoff, Niklas ... 5 Hidden ... Kasai, Jungo et Baruwa, Ahmed et autres
- OPT-IML: Échelle du modèle de langue Instruction Meta Apprentissage à travers l'objectif de la généralisation: 2022
Srinivasan Iyer et Xi Victoria Lin et Ramakanth Pasunuru ... 12 Hidden ... Asli Celikyilmaz et Luke Zettlemoyer et Ves Stoyanov
- Metaicl: Apprendre à apprendre dans le contexte: 2022
Min, Sewon et Lewis, Mike et Zettlemoyer, Luke et Hajishirzi, Hannaneh
- Instructions contre nature: réglage des modèles de langue avec (presque) pas de travail humain: 2022
Honovich, ou et Scialom, Thomas et Levy, Omer et Schick, Timo
- Généralisation crosslinguale à travers des finetuning multitastiques: 2022
Muennighoff, Niklas et Wang, Thomas et Sutawika, Lintang ... 5 Hidden ... Yong, Zheng-Xin et Schoelkopf, Hailey et autres
- La formation invitée multitâche permet la généralisation des tâches zéro-shot: 2022
Victor Sanh et Albert Webson et Colin Raffel ... 34 Hidden ... Leo Gao et Thomas Wolf et Alexander M Rush
- PROMÉTHEUS: Induction de la capacité d'évaluation à grain fin dans les modèles de langue: 2023
Kim, Seungone et Shin, Jamin et Cho, Yejin ... 5 Hidden ... Kim, Sungdong et Thorne, James et autres
- Slimorca: un ensemble de données ouvert des traces de raisonnement Flan augmentée GPT-4, avec vérification: 2023
Wing Lian et Guan Wang et Bleys Goodson ... 1 Hidden ... Austin Cook et Chanvichet Vong et "Teknium"
- L'art a-t-il volé des artistes ?: 2023
Chayka, Kyle
- Paul Tremblay, Mona Awad contre Openai, Inc., et al .: 2023
Saveri, Joseph R. et Zirpoli, Cadio et Young, Christopher KL et McMahon, Kathleen J.
- Faire de grands modèles de langage de meilleurs créateurs de données: 2023
Lee, Dong-ho et Pujara, Jay et Sewak, Mohit et White, Ryen et Jauhar, Sujay
- La collecte de flan: conception de données et méthodes pour un réglage de l'instruction efficace: 2023
Shayne Longpre et Le Hou et Tu Vu ... 5 Hidden ... Barret Zoph et Jason Wei et Adam Roberts
- Wizardlm: autonomiser les modèles de gros langues pour suivre les instructions complexes: 2023
Xu, Can and Sun, Qingfeng et Zheng, Kai ... 2 Hidden ... Feng, Jiazhan et Tao, Chongyang et Jiang, Daxin
- Lima: moins c'est plus pour l'alignement: 2023
Chunting Zhou et Pengfei Liu et Poxin Xu ... 9 Hidden ... Mike Lewis et Luke Zettlemoyer et Omer Levy
- Chameaux dans un climat changeant: améliorer l'adaptation LM avec Tulu 2: 2023
Hamish Ivison et Yizhong Wang et Valentina Pyatkin ... 5 Hidden ... Noah A. Smith et Iz Beltagy et Hannaneh Hajishirzi
- Auto-instruction: Alignement des modèles de langue avec des instructions auto-générées: 2023
Wang, Yizhong et Kordi, Yeganeh et Mishra, Swaroop ... 1 Hidden ... Smith, Noah A. et Khashabi, Daniel et Hajishirzi, Hannaneh
- Qu'est-ce qui fait de bonnes données pour l'alignement? Une étude complète de la sélection automatique des données dans le réglage des instructions: 2023
Liu, Wei et Zeng, Weihao et lui, Keqing et Jiang, Yong et lui, Junxian
- Réglage des instructions pour les grands modèles de langue: une enquête: 2023
Shengyu Zhang et Linfeng Dong et Xiaoya Li ... 5 Hidden ... Tianwei Zhang et Fei Wu et Guoyin Wang
- Stanford Alpaca: Un modèle LLAMA suivant les instructions: 2023
Rohan Taori et Ishaan Gulrajani et Tianyi Zhang ... 2 Hidden ... Carlos Guestrin et Percy Liang et Tatsunori B. Hashimoto
- Jusqu'où les chameaux peuvent-ils aller? Exploration de l'état de réglage des instructions sur les ressources ouvertes: 2023
Yizhong Wang et Hamish Ivison et Pradeep Dasigi ... 5 Hidden ... Noah A. Smith et Iz Beltagy et Hannaneh Hajishirzi
- Conversations ouvertes - démocratiser l'alignement du modèle de grande langue: 2023
K "OPF, Andreas et Kilcher, Yannic et Von R" Utte, Dimitri ... 5 Hidden ... Stanley, Oliver et Nagyfi, Rich'ard et autres
- Octopack: Code de réglage des instructions Modèles de grande langue: 2023
Niklas Muennighoff et Qian Liu et Armel Zebaze ... 4 Hidden ... Xiangru Tang et Leandro von Werra et Shayne Longpre
- Self: Auto-évolution axée sur la langue pour un grand modèle de langue: 2023
Lu, Jianqiao et Zhong, Wanjun et Huang, Wenyong ... 3 Hidden ... Wang, Weichao et Shang, Lifeng et Liu, Qun
- La collecte de flan: conception de données et méthodes pour un réglage de l'instruction efficace: 2023
Longpre, Shayne et Hou, Le et Vu, Tu ... 5 Hidden ... Zoph, Barret et Wei, Jason et Roberts, Adam
- #Instag: étiquetage d'instructions pour l'analyse du réglage fin supervisé des modèles de grande langue: 2023
Keming Lu et Hongyi Yuan et Zheng Yuan ... 2 Hidden ... Chuanqi Tan et Chang Zhou et Jingren Zhou
- Exploitation d'instructions: lorsque l'exploration de données rencontre un modèle de grande langue Finetuning: 2023
Yihan Cao et Yanbin Kang et Chi Wang et Lichao Sun
- Ticage d'instruction actif: Amélioration de la généralisation de la tâche croisée par une formation sur des tâches sensibles rapides: 2023
Po-Nien Kung et Fan Yin et Di Wu et Kai-Wei Chang et Nanyun Peng
- L'Initiative de provenance des données: un audit à grande échelle de l'octroi de licences et d'attribution de l'ensemble de données dans l'IA: 2023
Longpre, Shayne et Mahari, Robert et Chen, Anthony ... 5 Hidden ... Kabbara, Jad et Perisetla, Kartik et autres
- Ensemble de données AYA: une collection à accès ouvert pour le réglage des instructions multilingues: 2024
Shivalika Singh et Freddie Vargus et Daniel Dsouza ... 27 Hidden ... Ahmet üstün et Marzieh Fadadee et Sara Hooker
- Astraios: Code de réglage des instructions économe en paramètres Modèles de grande langue: 2024
Zhuo, Terry Yue et Zebaze, Armel et Suppattarachai, Nitchakarn ... 1 Hidden ... de Vries, Harm and Liu, Qian et Muennighoff, Niklas
- Modèle AYA: une instruction Finetuned Open-Access Multantial Language Modèle: 2024
"UST" Un, Ahmet et Aryabumi, Viraat et Yong, Zheng-Xin ... 5 Hidden ... Ooi, Hui-Lee et Kayid, Amr et autres
- Les modèles de langage plus petits sont capables de sélectionner des données de formation sur l'instruction pour les modèles de langue plus grands: 2024
Dheeraj Mekala et Alex Nguyen et Jingbo Shang
- Curration automatisée des données pour le modèle de langue robuste Fonction: 2024
Jihai Chen et Jonas Mueller
Sélection des données pour le réglage fin des préférences: alignement
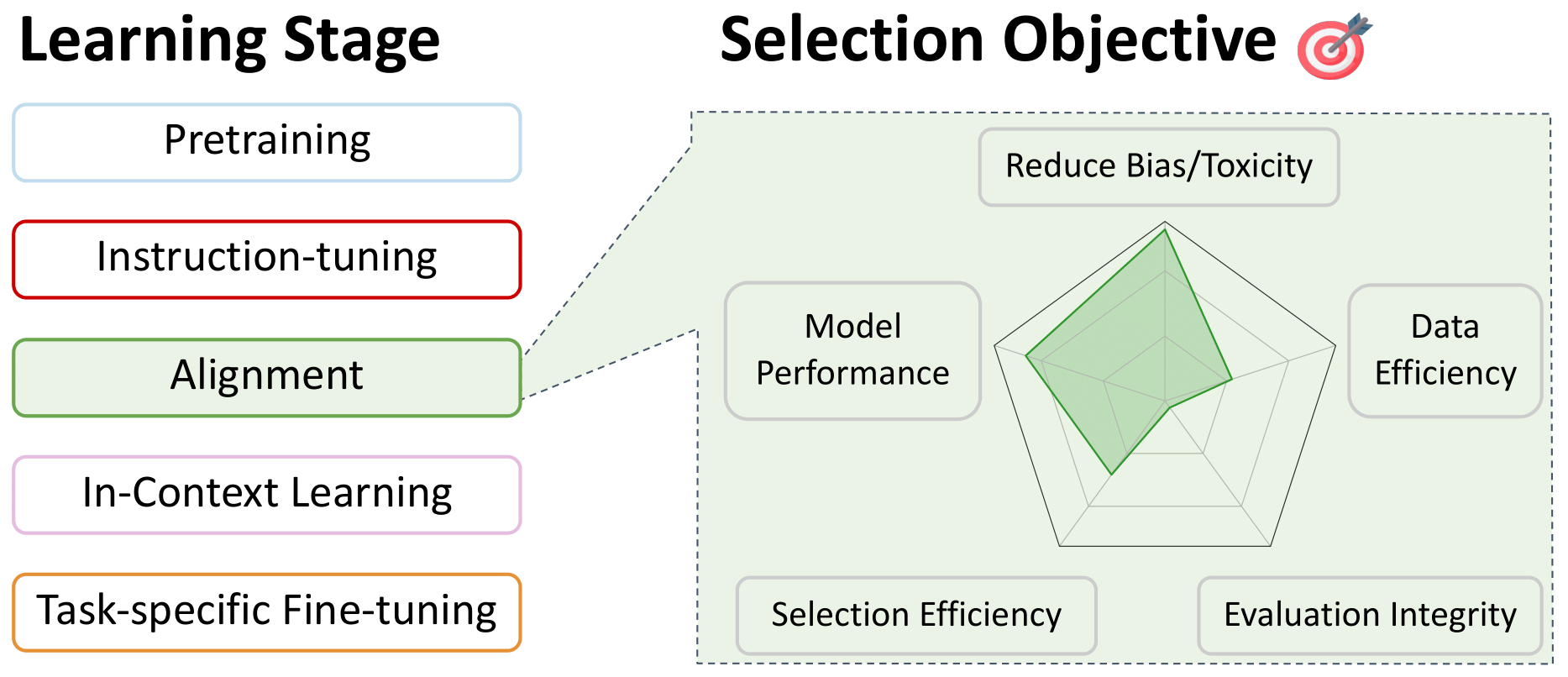
Retour à la table des matières
- WebGPT: Assaiant de questions assisté par le navigateur avec rétroaction humaine: 2021
Nakano, Reiichiro et Hilton, Jacob et Balaji, Suchir ... 5 Hidden ... Kosaraju, Vineet et Saunders, William et autres
- Formation d'un assistant utile et inoffensif avec apprentissage du renforcement des commentaires humains: 2022
Bai, Yuntao et Jones, Andy et Ndousse, Kamal ... 5 Hidden ... Ganguli, Deep et Henighan, Tom et autres
- Comprendre la difficulté de l'ensemble de données avec $ MathCalv $ - Informations utilisables: 2022
Ethayarajh, Kawin et Choi, Yejin et Swayamdipta, Swabha
- IA constitutionnelle: insigne de la rétroaction de l'IA: 2022
Bai, Yuntao et Kadavath, Saurav et Kundu, Sandipan ... 5 Hidden ... Mirhoseini, Azalia et McKinnon, Cameron et autres
- PROMÉTHEUS: Induction de la capacité d'évaluation à grain fin dans les modèles de langue: 2023
Kim, Seungone et Shin, Jamin et Cho, Yejin ... 5 Hidden ... Kim, Sungdong et Thorne, James et autres
- Notus: 2023
Alvaro Bartolome et Gabriel Martin et Daniel Vila
- Ultrafeedback: boosting des modèles de langue avec une rétroaction de haute qualité: 2023
Ganqu Cui and Lifan Yuan and Ning Ding... 3 hidden ... Guotong Xie and Zhiyuan Liu and Maosong Sun
- Exploration with Principles for Diverse AI Supervision: 2023
Liu, Hao and Zaharia, Matei and Abbeel, Pieter
- Wizardlm: Empowering large language models to follow complex instructions: 2023
Xu, Can and Sun, Qingfeng and Zheng, Kai... 2 hidden ... Feng, Jiazhan and Tao, Chongyang and Jiang, Daxin
- LIMA: Less Is More for Alignment: 2023
Chunting Zhou and Pengfei Liu and Puxin Xu... 9 hidden ... Mike Lewis and Luke Zettlemoyer and Omer Levy
- Shepherd: A Critic for Language Model Generation: 2023
Tianlu Wang and Ping Yu and Xiaoqing Ellen Tan... 4 hidden ... Luke Zettlemoyer and Maryam Fazel-Zarandi and Asli Celikyilmaz
- No Robots: 2023
Nazneen Rajani and Lewis Tunstall and Edward Beeching and Nathan Lambert and Alexander M. Rush and Thomas Wolf
- Starling-7B: Improving LLM Helpfulness & Harmlessness with RLAIF: 2023
Zhu, Banghua and Frick, Evan and Wu, Tianhao and Zhu, Hanlin and Jiao, Jiantao
- Scaling laws for reward model overoptimization: 2023
Gao, Leo and Schulman, John and Hilton, Jacob
- SALMON: Self-Alignment with Principle-Following Reward Models: 2023
Zhiqing Sun and Yikang Shen and Hongxin Zhang... 2 hidden ... David Cox and Yiming Yang and Chuang Gan
- Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback: 2023
Stephen Casper and Xander Davies and Claudia Shi... 26 hidden ... David Krueger and Dorsa Sadigh and Dylan Hadfield-Menell
- Camels in a Changing Climate: Enhancing LM Adaptation with Tulu 2: 2023
Hamish Ivison and Yizhong Wang and Valentina Pyatkin... 5 hidden ... Noah A. Smith and Iz Beltagy and Hannaneh Hajishirzi
- Llama 2: Open Foundation and Fine-Tuned Chat Models: 2023
Hugo Touvron and Louis Martin and Kevin Stone... 62 hidden ... Robert Stojnic and Sergey Edunov and Thomas Scialom
- What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning: 2023
Liu, Wei and Zeng, Weihao and He, Keqing and Jiang, Yong and He, Junxian
- HuggingFace H4 Stack Exchange Preference Dataset: 2023
Lambert, Nathan and Tunstall, Lewis and Rajani, Nazneen and Thrush, Tristan
- Textbooks Are All You Need: 2023
Gunasekar, Suriya and Zhang, Yi and Aneja, Jyoti... 5 hidden ... de Rosa, Gustavo and Saarikivi, Olli and others
- Quality-Diversity through AI Feedback: 2023
Herbie Bradley and Andrew Dai and Hannah Teufel... 4 hidden ... Kenneth Stanley and Grégory Schott and Joel Lehman
- Direct preference optimization: Your language model is secretly a reward model: 2023
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Ermon, Stefano and Manning, Christopher D and Finn, Chelsea
- Scaling relationship on learning mathematical reasoning with large language models: 2023
Yuan, Zheng and Yuan, Hongyi and Li, Chengpeng and Dong, Guanting and Tan, Chuanqi and Zhou, Chang
- The History and Risks of Reinforcement Learning and Human Feedback: 2023
Lambert, Nathan and Gilbert, Thomas Krendl and Zick, Tom
- Zephyr: Direct distillation of lm alignment: 2023
Tunstall, Lewis and Beeching, Edward and Lambert, Nathan... 5 hidden ... Fourrier, Cl'ementine and Habib, Nathan and others
- Perils of Self-Feedback: Self-Bias Amplifies in Large Language Models: 2024
Wenda Xu and Guanglei Zhu and Xuandong Zhao and Liangming Pan and Lei Li and William Yang Wang
- Suppressing Pink Elephants with Direct Principle Feedback: 2024
Louis Castricato and Nathan Lile and Suraj Anand and Hailey Schoelkopf and Siddharth Verma and Stella Biderman
- West-of-N: Synthetic Preference Generation for Improved Reward Modeling: 2024
Alizée Pace and Jonathan Mallinson and Eric Malmi and Sebastian Krause and Aliaksei Severyn
- Statistical Rejection Sampling Improves Preference Optimization: 2024
Liu, Tianqi and Zhao, Yao and Joshi, Rishabh... 1 hidden ... Saleh, Mohammad and Liu, Peter J and Liu, Jialu
- Self-play fine-tuning converts weak language models to strong language models: 2024
Chen, Zixiang and Deng, Yihe and Yuan, Huizhuo and Ji, Kaixuan and Gu, Quanquan
- Self-Rewarding Language Models: 2024
Weizhe Yuan and Richard Yuanzhe Pang and Kyunghyun Cho and Sainbayar Sukhbaatar and Jing Xu and Jason Weston
- Theoretical guarantees on the best-of-n alignment policy: 2024
Beirami, Ahmad and Agarwal, Alekh and Berant, Jonathan... 1 hidden ... Eisenstein, Jacob and Nagpal, Chirag and Suresh, Ananda Theertha
- KTO: Model Alignment as Prospect Theoretic Optimization: 2024
Ethayarajh, Kawin and Xu, Winnie and Muennighoff, Niklas and Jurafsky, Dan and Kiela, Douwe
Data Selection for In-Context Learning
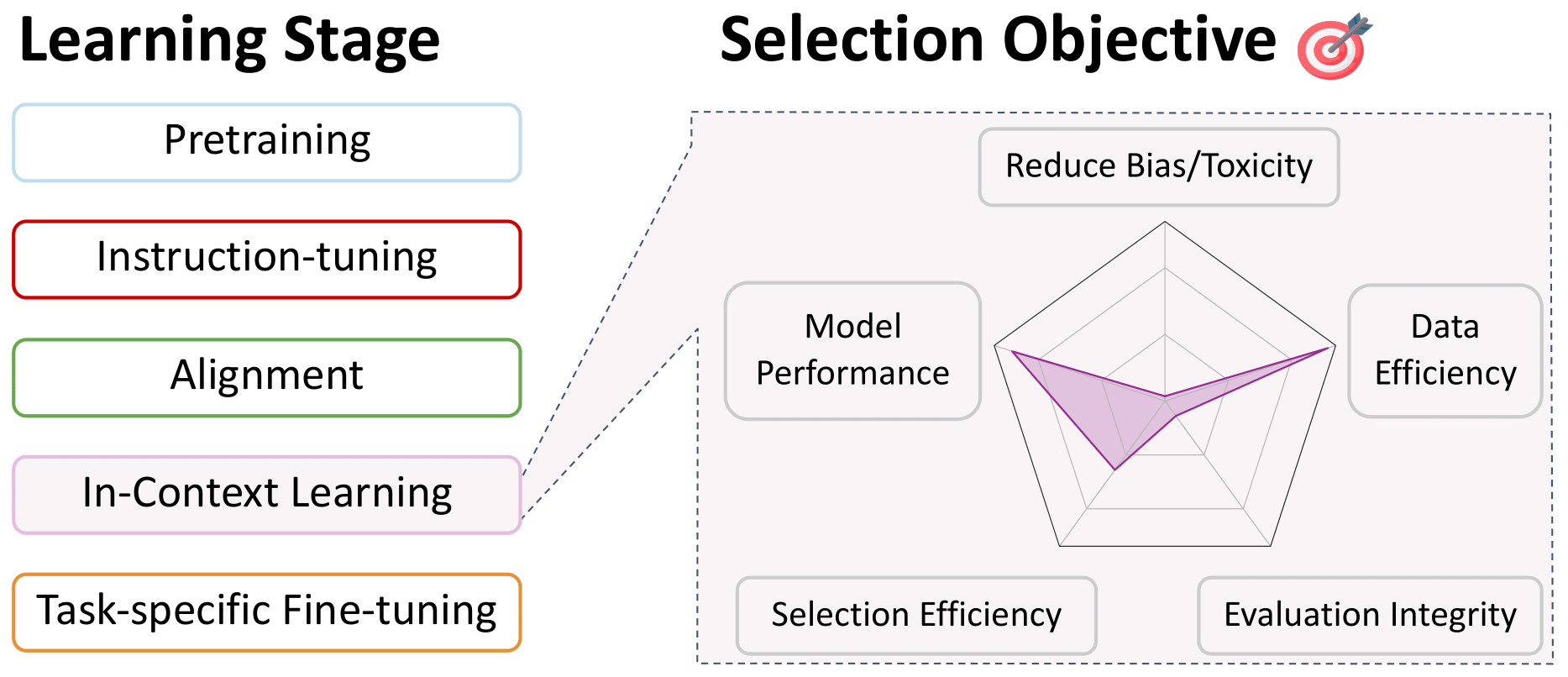
Back to Table of Contents
- Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks: 2019
Reimers, Nils and Gurevych, Iryna
- Language Models are Few-Shot Learners: 2020
Brown, Tom and Mann, Benjamin and Ryder, Nick... 25 hidden ... Radford, Alec and Sutskever, Ilya and Amodei, Dario
- True Few-Shot Learning with Language Models: 2021
Ethan Perez and Douwe Kiela and Kyunghyun Cho
- Active Example Selection for In-Context Learning: 2022
Zhang, Yiming and Feng, Shi and Tan, Chenhao
- Careful Data Curation Stabilizes In-context Learning: 2022
Chang, Ting-Yun and Jia, Robin
- Learning To Retrieve Prompts for In-Context Learning: 2022
Rubin, Ohad and Herzig, Jonathan and Berant, Jonathan
- Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity: 2022
Lu, Yao and Bartolo, Max and Moore, Alastair and Riedel, Sebastian and Stenetorp, Pontus
- What Makes Good In-Context Examples for GPT-3?: 2022
Liu, Jiachang and Shen, Dinghan and Zhang, Yizhe and Dolan, Bill and Carin, Lawrence and Chen, Weizhu
- MetaICL: Learning to Learn In Context: 2022
Min, Sewon and Lewis, Mike and Zettlemoyer, Luke and Hajishirzi, Hannaneh
- Unified Demonstration Retriever for In-Context Learning: 2023
Li, Xiaonan and Lv, Kai and Yan, Hang... 3 hidden ... Xie, Guotong and Wang, Xiaoling and Qiu, Xipeng
- Which Examples to Annotate for In-Context Learning? Towards Effective and Efficient Selection: 2023
Mavromatis, Costas and Srinivasan, Balasubramaniam and Shen, Zhengyuan... 1 hidden ... Rangwala, Huzefa and Faloutsos, Christos and Karypis, George
- Large Language Models Are Latent Variable Models: Explaining and Finding Good Demonstrations for In-Context Learning: 2023
Xinyi Wang and Wanrong Zhu and Michael Saxon and Mark Steyvers and William Yang Wang
- Selective Annotation Makes Language Models Better Few-Shot Learners: 2023
Hongjin SU and Jungo Kasai and Chen Henry Wu... 5 hidden ... Luke Zettlemoyer and Noah A. Smith and Tao Yu
- In-context Example Selection with Influences: 2023
Nguyen, Tai and Wong, Eric
- Coverage-based Example Selection for In-Context Learning: 2023
Gupta, Shivanshu and Singh, Sameer and Gardner, Matt
- Compositional exemplars for in-context learning: 2023
Ye, Jiacheng and Wu, Zhiyong and Feng, Jiangtao and Yu, Tao and Kong, Lingpeng
- Take one step at a time to know incremental utility of demonstration: An analysis on reranking for few-shot in-context learning: 2023
Hashimoto, Kazuma and Raman, Karthik and Bendersky, Michael
- Ambiguity-aware in-context learning with large language models: 2023
Gao, Lingyu and Chaudhary, Aditi and Srinivasan, Krishna and Hashimoto, Kazuma and Raman, Karthik and Bendersky, Michael
- IDEAL: Influence-Driven Selective Annotations Empower In-Context Learners in Large Language Models: 2023
Zhang, Shaokun and Xia, Xiaobo and Wang, Zhaoqing... 1 hidden ... Liu, Jiale and Wu, Qingyun and Liu, Tongliang
- ScatterShot: Interactive In-context Example Curation for Text Transformation: 2023
Wu, Sherry and Shen, Hua and Weld, Daniel S and Heer, Jeffrey and Ribeiro, Marco Tulio
- Diverse Demonstrations Improve In-context Compositional Generalization: 2023
Levy, Itay and Bogin, Ben and Berant, Jonathan
- Finding supporting examples for in-context learning: 2023
Li, Xiaonan and Qiu, Xipeng
- Misconfidence-based Demonstration Selection for LLM In-Context Learning: 2024
Xu, Shangqing and Zhang, Chao
- In-context Learning with Retrieved Demonstrations for Language Models: A Survey: 2024
Xu, Xin and Liu, Yue and Pasupat, Panupong and Kazemi, Mehran and others
Data Selection for Task-specific Fine-tuning
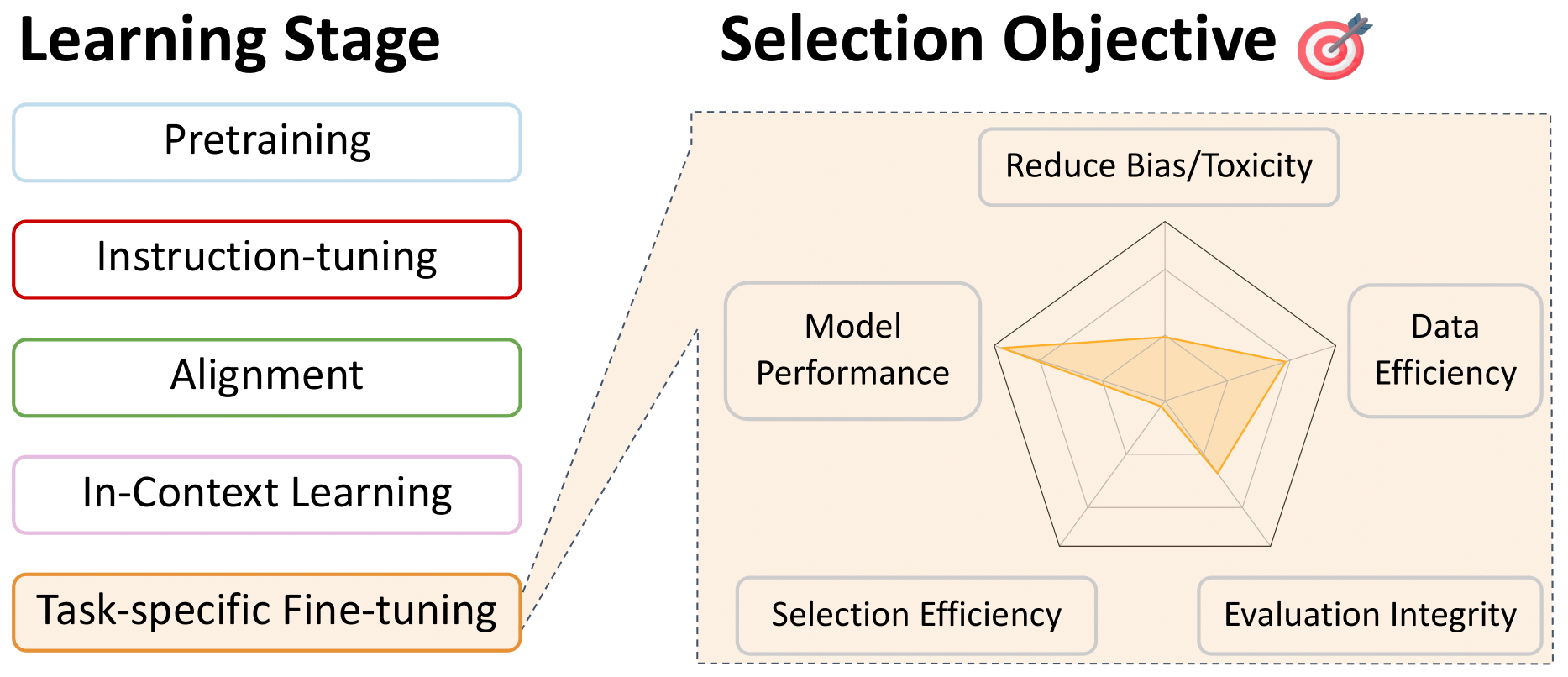
Back to Table of Contents
- A large annotated corpus for learning natural language inference: 2015
Bowman, Samuel R. and Angeli, Gabor and Potts, Christopher and Manning, Christopher D.
- GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding: 2018
Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel
- A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference: 2018
Williams, Adina and Nangia, Nikita and Bowman, Samuel
- Sentence Encoders on STILTs: Supplementary Training on Intermediate Labeled-data Tasks: 2019
Jason Phang and Thibault Févry and Samuel R. Bowman
- Distributionally Robust Neural Networks: 2020
Shiori Sagawa and Pang Wei Koh and Tatsunori B. Hashimoto and Percy Liang
- Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics: 2020
Swayamdipta, Swabha and Schwartz, Roy and Lourie, Nicholas... 1 hidden ... Hajishirzi, Hannaneh and Smith, Noah A. and Choi, Yejin
- Intermediate-Task Transfer Learning with Pretrained Language Models: When and Why Does It Work?: 2020
Pruksachatkun, Yada and Phang, Jason and Liu, Haokun... 3 hidden ... Vania, Clara and Kann, Katharina and Bowman, Samuel R.
- On the Complementarity of Data Selection and Fine Tuning for Domain Adaptation: 2021
Dan Iter and David Grangier
- FETA: A Benchmark for Few-Sample Task Transfer in Open-Domain Dialogue: 2022
Albalak, Alon and Tuan, Yi-Lin and Jandaghi, Pegah... 3 hidden ... Getoor, Lise and Pujara, Jay and Wang, William Yang
- LoRA: Low-Rank Adaptation of Large Language Models: 2022
Edward J Hu and yelong shen and Phillip Wallis... 2 hidden ... Shean Wang and Lu Wang and Weizhu Chen
- Training Subset Selection for Weak Supervision: 2022
Lang, Hunter and Vijayaraghavan, Aravindan and Sontag, David
- On-Demand Sampling: Learning Optimally from Multiple Distributions: 2022
Haghtalab, Nika and Jordan, Michael and Zhao, Eric
- The Trade-offs of Domain Adaptation for Neural Language Models: 2022
Grangier, David and Iter, Dan
- Data Pruning for Efficient Model Pruning in Neural Machine Translation: 2023
Azeemi, Abdul and Qazi, Ihsan and Raza, Agha
- Skill-it! A Data-Driven Skills Framework for Understanding and Training Language Models: 2023
Mayee F. Chen and Nicholas Roberts and Kush Bhatia... 1 hidden ... Ce Zhang and Frederic Sala and Christopher Ré
- D2 Pruning: Message Passing for Balancing Diversity and Difficulty in Data Pruning: 2023
Adyasha Maharana and Prateek Yadav and Mohit Bansal
- Improving Few-Shot Generalization by Exploring and Exploiting Auxiliary Data: 2023
Alon Albalak and Colin Raffel and William Yang Wang
- Efficient Online Data Mixing For Language Model Pre-Training: 2023
Alon Albalak and Liangming Pan and Colin Raffel and William Yang Wang
- Data-Efficient Finetuning Using Cross-Task Nearest Neighbors: 2023
Ivison, Hamish and Smith, Noah A. and Hajishirzi, Hannaneh and Dasigi, Pradeep
- Make Every Example Count: On the Stability and Utility of Self-Influence for Learning from Noisy NLP Datasets: 2023
Bejan, Irina and Sokolov, Artem and Filippova, Katja
- LESS: Selecting Influential Data for Targeted Instruction Tuning: 2024
Mengzhou Xia and Sadhika Malladi and Suchin Gururangan and Sanjeev Arora and Danqi Chen
Contribution
There are likely some amazing works in the field that we missed, so please contribute to the repo.
Feel free to open a pull request with new papers or create an issue and we can add them for you. Thank you in advance for your efforts!
Citation
We hope this work serves as inspiration for many impactful future works. If you found our work useful, please cite this paper as:
@article{albalak2024survey,
title={A Survey on Data Selection for Language Models},
author={Alon Albalak and Yanai Elazar and Sang Michael Xie and Shayne Longpre and Nathan Lambert and Xinyi Wang and Niklas Muennighoff and Bairu Hou and Liangming Pan and Haewon Jeong and Colin Raffel and Shiyu Chang and Tatsunori Hashimoto and William Yang Wang},
year={2024},
journal={arXiv preprint arXiv:2402.16827},
note={url{https://arxiv.org/abs/2402.16827}}
}


