دراسة استقصائية حول اختيار البيانات لنماذج اللغة
هذا الريبو هو قائمة ملائمة للأوراق ذات الصلة باختيار البيانات لنماذج اللغة ، خلال جميع مراحل التدريب. من المفترض أن يكون هذا موردًا للمجتمع ، لذا يرجى المساهمة إذا رأيت أي شيء مفقود!
لمزيد من التفاصيل حول هذه الأعمال ، وأكثر من ذلك ، راجع ورقة المسح الخاصة بنا: دراسة استقصائية حول اختيار البيانات لنماذج اللغة. من خلال هذا الفريق المذهل: Alon Albalak ، Yanai Elazar ، Sang Michael Xie ، Shayne Longpre ، Nathan Lambert ، Xinyi Wang ، Niklas Muennighoff ، Bairu Hou ، Liangming Pan ، Haewon Jeong ، Colin Raffel ، Shiyu Change ، Tatsunori Hashimoto ، William Wang
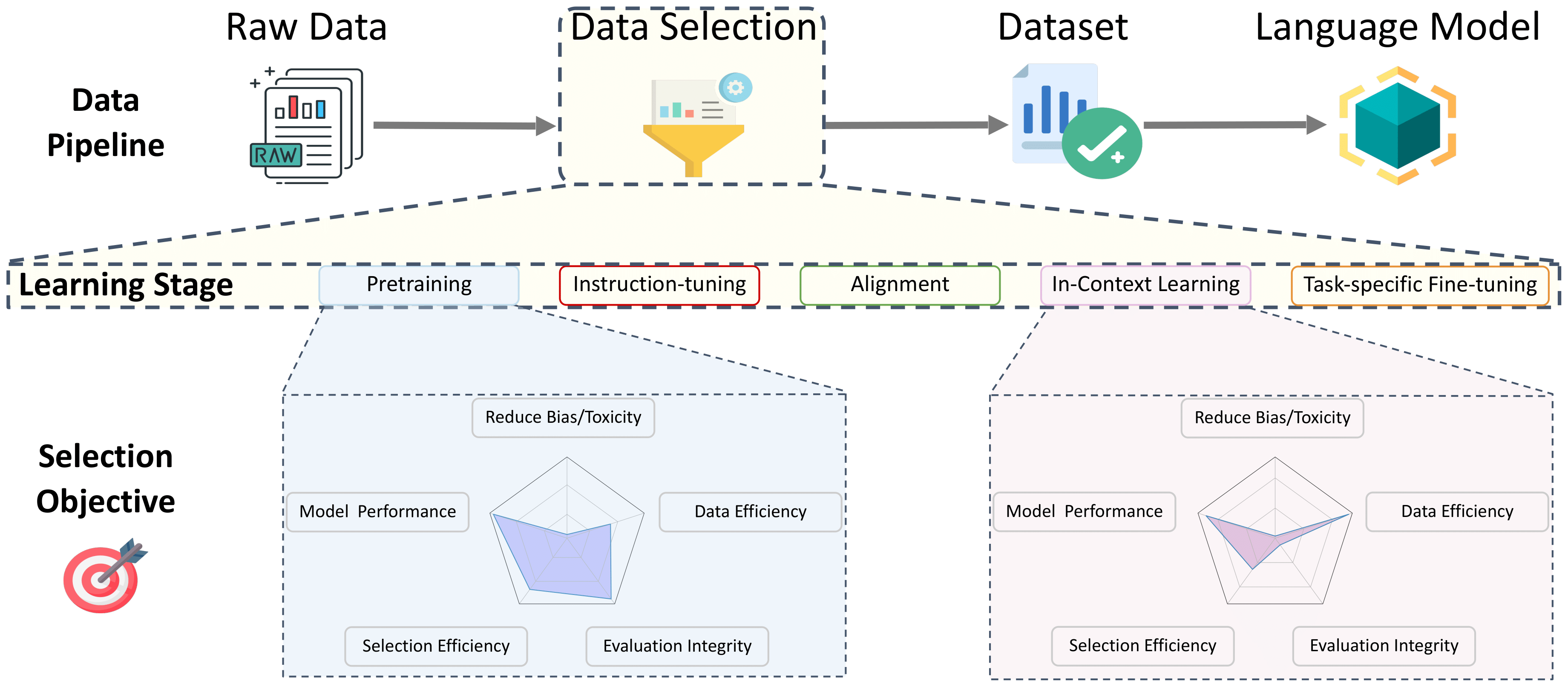
جدول المحتويات
- اختيار البيانات للتدريب
- تصفية اللغة
- النهج الجماعية
- جودة البيانات
- اختيار خاص بالمجال
- البيانات المكررة
- تصفية المحتوى السام والصريح
- اختيار متخصص للنماذج متعددة اللغات
- خلط البيانات
- اختيار البيانات لتدريب التعليمات والتدريب متعدد المهام
- اختيار البيانات لمحاذاة صقل الأفضلية
- اختيار البيانات للتعلم داخل السياق
- اختيار البيانات للضغط الخاص بالمهمة
اختيار البيانات للتدريب
تصفية اللغة
العودة إلى جدول المحتويات
- fasttext.zip: ضغط نماذج تصنيف النص: 2016
أرماند جولين وإدوارد غبر وبيوت بوجانوفسكي وماتيجس دوز وهريف جيجو وتوماس ميكولوف
- متعلم ناقلات كلمة 157 لغة: 2018
Grave ، Edouard و Bojanowski ، Piotr and Gupta ، Prakhar and Joulin ، Armand and Mikolov ، Tomas
- نموذج اللغة عبر اللغات ما قبل الإدراك: 2019
كونو ، أليكسيس و lample ، guillaume
- استكشاف حدود التعلم النقل باستخدام محول نص إلى نص موحد: 2020
رافيل ، كولين وشازير ، نام وروبرتس ، آدم ... 3 مخفي ... تشو ، يانكي ولي ، وي وليو ، بيتر ج.
- معرف اللغة في البرية: تحديات غير متوقعة على الطريق إلى مجموعة نص ويب من اللغة: 2020
Caswell و Isaac و Breiner و Theresa و Van Esch و Daan و Bapna و Ankur
- التمثيل عبر اللغات غير الخاضع للرقابة التعلم على نطاق واسع: 2020
كونو ، أليكسيس وخاندلوال ، كارتيكاي وجويال ، نامان ... 4 مخبأة ... أوت ، مايل و Zettlemoyer ، لوك وستويانوف ، فيسيلين
- CCNET: استخراج مجموعات بيانات أحادية الجودة عالية الجودة من بيانات الزحف على الويب: 2020
Wenzek ، Guillaume and Lachaux ، Marie-Anne and Conneau ، Alexis ... 1 Hidden ... Guzm'an ، Francisco and Joulin ، Armand and Grave ، Edouard
- استنساخ لنماذج LSTM ثنائية الاتجاه من Apple لتحديد اللغة في السلاسل القصيرة: 2021
Toftrup و Mads و Asger Sorensen و Soren و Ciosici و Manuel R. و Assent ، IRA
- تقييم نماذج اللغة الكبيرة المدربة على الكود: 2021
مارك تشن وجيري تويرك وهووو يونيو ... 52 مخفيًا ... سام مكندليش وإيليا سوتسكفر و Wojciech Zaremba
- MT5: محول نص إلى نص متعدد اللغات على نطاق واسع: 2021
Xue ، Linting و Constant ، نوح وروبرتس ، آدم ... 2 مخفي ... Siddhant ، Aditya و Barua ، Aditya و Raffel ، Colin
- توليد رمز على مستوى المنافسة مع Alphacode: 2022
Li ، Yujia and Choi ، David and Chung ، Junyoung ... 20 Hidden ... De Freitas ، Nando و Kavukcuoglu ، Koray and Vinyals ، Oriol
- النخيل: نمذجة لغة التحجيم مع المسارات: 2022
Aakanksha Chowdhery و Sharan Narang و Jacob Devlin ... 61 Hidden ... Jeff Dean و Slav Petrov و Noah Fiedel
- مجموعة BigScience Roots: مجموعة بيانات متعددة اللغات مركبة 1.6 تيرابايت: 2022
لورينكونون ، هوغو وسولنييه ، لوسيل ووانغ ، توماس ... 48 مخفيًا ... ميتشل ، مارغريت ولوكوني ، ساشا ألكسندرا وجيرنيت ، ياسين
- نظام الكتابة والبيانات الوصفية للسماعات لـ 2،800+ الأصناف اللغوية: 2022
Van Esch ، Daan and Lucassen ، Tamar and Ruder ، Sebastian and Caswell ، Isaac and Rivera ، Clara
- Fingpt: نماذج توليدية كبيرة للغة الصغيرة: 2023
Luukkonen ، Risto and Komulainen ، Ville and Luoma ، Jouni ... 5 Hidden ... Muennighoff ، Niklas and Piktus ، Aleksandra and others
- MC^ 2: مجموعة متعددة اللغات لغات الأقليات في الصين: 2023
تشانغ ، تشن وتاو ، مينغكسو وهوانغ ، kozhe ولين ، جيوانغ وتشن ، Zhibin و Feng ، Yansong
- MADLAD-400: مجموعة بيانات مراجعة كبيرة متعددة اللغات ومستوى كبير: 2023
Kudugunta و Sneha و Caswell و Isaac and Zhang و Biao ... 5 Hidden ... Stella و Romi و Bapna و Ankur وغيرها
- مجموعة بيانات refressedweb لـ Falcon LLM: تفوق الأداء المبرمج مع بيانات الويب ، وبيانات الويب فقط: 2023
Guilherme Penedo و Quentin Malartic و Daniel Hesslow ... 3 Hidden ... Baptiste Pannier و Ebtesam Almazrouei و Julien Launay
- Dolma: مجموعة مفتوحة من ثلاثة تريليونات الرموز لنموذج اللغة الأبحاث المسبق: 2024
لوكا سولديني ورودني كيني وأكشيتا بهاجيا ... 30 مخفيًا ... ديرك جرينفيلد وجيسي دودج وكايل لو
النهج الجماعية
العودة إلى جدول المحتويات
- استكشاف حدود التعلم النقل باستخدام محول نص إلى نص موحد: 2020
رافيل ، كولين وشازير ، نام وروبرتس ، آدم ... 3 مخفي ... تشو ، يانكي ولي ، وي وليو ، بيتر ج.
- نماذج اللغة متعلمين قليلة: 2020
براون ، توم ومان ، بنيامين ورايدر ، نيك ... 25 مخفيًا ... رادفورد ، أليك وسوتسكفر ، إيليا وأمودي ، داريو
- الوبر: مجموعة بيانات 800 جيجابايت من النص المتنوع لنمذجة اللغة: 2020
ليو جاو وستيلا بايدرمان وسيد بلاك ... 6 مخفي ... نوا نابشيما وشون بريسر وكونور ليهي
- تقييم نماذج اللغة الكبيرة المدربة على الكود: 2021
مارك تشن وجيري تويرك وهووو يونيو ... 52 مخفيًا ... سام مكندليش وإيليا سوتسكفر و Wojciech Zaremba
- MT5: محول نص إلى نص متعدد اللغات على نطاق واسع: 2021
Xue ، Linting و Constant ، نوح وروبرتس ، آدم ... 2 مخفي ... Siddhant ، Aditya و Barua ، Aditya و Raffel ، Colin
- نماذج لغة التحجيم: الأساليب والتحليل والرؤى من تدريب Gopher: 2022
جاك دبليو راي وسيباستيان بورجيود وتريفور كاي ... 74 مخفيًا ... ديميس هاسابيس وكوراي كافوكوغلو وجيفري إيرفينغ
- مجموعة BigScience Roots: مجموعة بيانات متعددة اللغات مركبة 1.6 تيرابايت: 2022
لورينكونون ، هوغو وسولنييه ، لوسيل ووانغ ، توماس ... 48 مخفيًا ... ميتشل ، مارغريت ولوكوني ، ساشا ألكسندرا وجيرنيت ، ياسين
- HTLM: Hyper-Text Pre-Training و Proping لنماذج اللغة: 2022
أرمين آغاجانيان ودميترو أوكونكو ومايك لويس ... 1 مخفي ... هو شو شو وغارجي غوش ولوك زيتلمويير
- لاما: نماذج لغة الأساس المفتوحة والفعالة: 2023
Hugo Touvron و Thibaut Lavril و Gautier Izacard ... 8 Hidden ... Armand Joulin و Edouard Grave و Guillaume Lample
- مجموعة بيانات refressedweb لـ Falcon LLM: تفوق الأداء المبرمج مع بيانات الويب ، وبيانات الويب فقط: 2023
Guilherme Penedo و Quentin Malartic و Daniel Hesslow ... 3 Hidden ... Baptiste Pannier و Ebtesam Almazrouei و Julien Launay
- مؤشر شفافية نموذج الأساس: 2023
Bommasani ، Rishi and Klyman ، Kevin and Longpre ، Shayne ... 2 Hidden ... Xiong ، Betty and Zhang ، Daniel and Liang ، Percy
- Dolma: مجموعة مفتوحة من ثلاثة تريليونات الرموز لنموذج اللغة الأبحاث المسبق: 2024
لوكا سولديني ورودني كيني وأكشيتا بهاجيا ... 30 مخفيًا ... ديرك جرينفيلد وجيسي دودج وكايل لو
جودة البيانات
العودة إلى جدول المحتويات
- Kenlm: استفسارات نموذج اللغة أسرع وأصغر: 2011
هيفيلد ، كينيث
- fasttext.zip: ضغط نماذج تصنيف النص: 2016
أرماند جولين وإدوارد غبر وبيوت بوجانوفسكي وماتيجس دوز وهريف جيجو وتوماس ميكولوف
- متعلم ناقلات كلمة 157 لغة: 2018
Grave ، Edouard و Bojanowski ، Piotr and Gupta ، Prakhar and Joulin ، Armand and Mikolov ، Tomas
- نماذج اللغة متعلمين في المهام المتعددة غير الخاضعة للإشراف: 2019
أليك رادفورد وجيف وو وريون تشايلد وديفيد لوان وداريو أمودي وإيليا سوتسكفر
- نماذج اللغة متعلمين قليلة: 2020
براون ، توم ومان ، بنيامين ورايدر ، نيك ... 25 مخفيًا ... رادفورد ، أليك وسوتسكفر ، إيليا وأمودي ، داريو
- الوبر: مجموعة بيانات 800 جيجابايت من النص المتنوع لنمذجة اللغة: 2020
ليو جاو وستيلا بايدرمان وسيد بلاك ... 6 مخفي ... نوا نابشيما وشون بريسر وكونور ليهي
- CCNET: استخراج مجموعات بيانات أحادية الجودة عالية الجودة من بيانات الزحف على الويب: 2020
Wenzek ، Guillaume and Lachaux ، Marie-Anne and Conneau ، Alexis ... 1 Hidden ... Guzm'an ، Francisco and Joulin ، Armand and Grave ، Edouard
- نماذج لغة إزالة السموم تخاطر بتهميش أصوات الأقليات: 2021
شو ، ألبرت و باثاك ، إيشان و والاس ، إريك وجورانجان ، سوشن و SAP ، مارتن وكلاين ، دان
- النخيل: نمذجة لغة التحجيم مع المسارات: 2022
Aakanksha Chowdhery و Sharan Narang و Jacob Devlin ... 61 Hidden ... Jeff Dean و Slav Petrov و Noah Fiedel
- نماذج لغة التحجيم: الأساليب والتحليل والرؤى من تدريب Gopher: 2022
جاك دبليو راي وسيباستيان بورجيود وتريفور كاي ... 74 مخفيًا ... ديميس هاسابيس وكوراي كافوكوغلو وجيفري إيرفينغ
- من الذي تعتبر اللغة عالية الجودة؟ قياس أيديولوجيات اللغة في اختيار البيانات النصية: 2022
Gururangan ، Schoin and Card ، Dallas and Dreier ، Sarah ... 2 Hidden ... Wang ، Zeyu and Zettlemoyer ، Luke and Smith ، Noah A.
- glam: تحجيم فعال لنماذج اللغة مع الخبراء الخليط: 2022
Du ، Nan and Huang ، Yanping and Dai ، Andrew M ... 21 Hidden ... Wu ، Yonghui and Chen ، Zhifeng and Cui ، Claire
- دليل ما قبل الأملس لبيانات التدريب: قياس آثار عمر البيانات وتغطية المجال والجودة والسمية: 2023
شاين لونجبر وجريجوري يوني وإميلي ريف ... 5 مخفي ... كيفن روبنسون وديفيد ممنو ودافني إيبوليتو
- اختيار البيانات لنماذج اللغة من خلال إعادة تشكيل الأهمية: 2023
سانج مايكل شيه وشيباني سانتوركار و Tengyu MA و Percy Liang
- مجموعة بيانات refressedweb لـ Falcon LLM: تفوق الأداء المبرمج مع بيانات الويب ، وبيانات الويب فقط: 2023
Guilherme Penedo و Quentin Malartic و Daniel Hesslow ... 3 Hidden ... Baptiste Pannier و Ebtesam Almazrouei و Julien Launay
- Dolma: مجموعة مفتوحة من ثلاثة تريليونات الرموز لنموذج اللغة الأبحاث المسبق: 2024
لوكا سولديني ورودني كيني وأكشيتا بهاجيا ... 30 مخفيًا ... ديرك جرينفيلد وجيسي دودج وكايل لو
- برمجة كل مثال: رفع جودة البيانات قبل التدريب مثل الخبراء على نطاق واسع: 2024
المعجبين تشو و Zengzhi Wang و Qian Liu و Junlong Li و Pengfei Liu
اختيار خاص بالمجال
العودة إلى جدول المحتويات
- اكتساب البيانات النصية لنماذج اللغة الخاصة بالمجال: 2006
سيثي ، أبهيناف وجورجيو ، بانايوتس ج. ونارايانان ، شريكانث
- اختيار ذكي لبيانات تدريب نموذج اللغة: 2010
مور ، روبرت سي ولويس ، وليام
- اختيار ساخر لبيانات تدريب نموذج اللغة: 2017
Amittai Axelrod
- اختيار المستند التلقائي ل pretring التشفير الفعال: 2022
فنغ ويوكون وشيا ، باتريك وفان دورمي ، بنيامين وسدوك ، جو ~ ao
- اختيار البيانات لنماذج اللغة من خلال إعادة تشكيل الأهمية: 2023
سانج مايكل شيه وشيباني سانتوركار و Tengyu MA و Percy Liang
- DSDM: اختيار مجموعة بيانات النموذج مع Datamodels: 2024
لوجان إنجستروم وأكسل فيلدمان وألكساندر مادي
البيانات المكررة
العودة إلى جدول المحتويات
- مقايضات الفضاء/الوقت في ترميز التجزئة مع الأخطاء المسموح بها: 1970
بلوم ، بيرتون H.
- صفائف لاحقة: طريقة جديدة لعمليات البحث عن السلسلة عبر الإنترنت: 1993
مانبر ، أودي ومايرز ، جين
- على تشابه واحتواء الوثائق: 1997
برودر ، من الألف إلى الياء
- تقنيات تقدير التشابه من الخوارزميات الدائرية: 2002
Charikar ، موسى س.
- تطبيع عنوان URL لإلغاء الاشتراك في صفحات الويب: 2009
Agarwal و Amit و Koppula و Hema Swetha و Leela و Krishna P .... 3 Hidden ... Haty و Chittaranjan و Roy و Anirban و Sasturkar ، Amit
- خطوط أنابيب غير متزامنة لمعالجة الشركات الضخمة على البنية التحتية المتوسطة إلى المنخفضة للموارد: 2019
Pedro Javier Ortiz Su'arez و Beno^It Sagot و Laurent Romary
- نماذج اللغة متعلمين قليلة: 2020
براون ، توم ومان ، بنيامين ورايدر ، نيك ... 25 مخفيًا ... رادفورد ، أليك وسوتسكفر ، إيليا وأمودي ، داريو
- الوبر: مجموعة بيانات 800 جيجابايت من النص المتنوع لنمذجة اللغة: 2020
ليو جاو وستيلا بايدرمان وسيد بلاك ... 6 مخفي ... نوا نابشيما وشون بريسر وكونور ليهي
- CCNET: استخراج مجموعات بيانات أحادية الجودة عالية الجودة من بيانات الزحف على الويب: 2020
Wenzek ، Guillaume and Lachaux ، Marie-Anne and Conneau ، Alexis ... 1 Hidden ... Guzm'an ، Francisco and Joulin ، Armand and Grave ، Edouard
- ما وراء قوانين التحجيم العصبي: تخطي قانون السلطة المتضايق عبر تقليم البيانات: 2022
بن سورشر وروبرت جيرهوس وشاشانك شيخار وسوريا جانجولي وأري س. موركوس
- بيانات التدريب المستهلكة تجعل نماذج اللغة أفضل: 2022
لي ، كاثرين وإيبوليتو ، دافني ونيستروم ، أندرو ... 1 مخفي ... إيك ، دوغلاس وكالسون بورش ، كريس وكارلين ، نيكولاس
- MTEB: معايير تضمين نص ضخمة: 2022
Muennighoff و Niklas و Tazi و Nouamane و Magne ، Lo "IC و Reimers ، Nils
- النخيل: نمذجة لغة التحجيم مع المسارات: 2022
Aakanksha Chowdhery و Sharan Narang و Jacob Devlin ... 61 Hidden ... Jeff Dean و Slav Petrov و Noah Fiedel
- نماذج لغة التحجيم: الأساليب والتحليل والرؤى من تدريب Gopher: 2022
جاك دبليو راي وسيباستيان بورجيود وتريفور كاي ... 74 مخفيًا ... ديميس هاسابيس وكوراي كافوكوغلو وجيفري إيرفينغ
- SGPT: جمل GPT تضمينات للبحث الدلالي: 2022
Muennighoff ، نيكلاس
- مجموعة BigScience Roots: مجموعة بيانات متعددة اللغات مركبة 1.6 تيرابايت: 2022
لورينكونون ، هوغو وسولنييه ، لوسيل ووانغ ، توماس ... 48 مخفيًا ... ميتشل ، مارغريت ولوكوني ، ساشا ألكسندرا وجيرنيت ، ياسين
- C-Pack: الموارد المعبأة لتعزيز التضمين الصيني العام: 2023
شياو ، شياو وليو ، تشنغ وتشانغ ، بيتيان ومونيهوف ، نيكلاس
- D4: تحسين PretReing LLM عبر إلغاء الإلغاء الوثيقة والتنويع: 2023
كوشال تيرومالا ودانييل سيميج وأرمين آغاجانيان وأري س.
- على نطاق واسع شبه انخفاض في Bigcode: 2023
مذكرة التفاهم
- بالوما: معيار لتقييم نموذج اللغة المناسب: 2023
إيان ماجنوسون وأكشيتا بهاجيا وفالنتين هوفمان ... 10 مخفي ... نوح أ. سميث وكايل ريتشاردسون وجيسي دودج
- تحديد الكمية في النماذج اللغوية العصبية: 2023
نيكولاس كارليني ودافني إيبوليتو وماثيو جاجيلسكي وكاثرين لي وفلوريان ترامر وتشيوان تشانغ
- SEMDEDUP: التعلم الفعال للبيانات على نطاق الويب من خلال إلغاء البيانات الدلالية: 2023
عباس وعمرو وتيرومالا وكوشال وسيميج ودانيل وجانجولي وسوريا ومركوس ، آري س
- مجموعة بيانات refressedweb لـ Falcon LLM: تفوق الأداء المبرمج مع بيانات الويب ، وبيانات الويب فقط: 2023
Guilherme Penedo و Quentin Malartic و Daniel Hesslow ... 3 Hidden ... Baptiste Pannier و Ebtesam Almazrouei و Julien Launay
- ماذا يوجد في بياناتي الكبيرة ؟: 2023
Elazar ، Yanai و Bhagia ، Akshita و Magnusson ، Ian ... 5 Hidden ... Soldaini ، Luca and Singh ، Sameer وغيرها
- Dolma: مجموعة مفتوحة من ثلاثة تريليونات الرموز لنموذج اللغة الأبحاث المسبق: 2024
لوكا سولديني ورودني كيني وأكشيتا بهاجيا ... 30 مخفيًا ... ديرك جرينفيلد وجيسي دودج وكايل لو
- ضبط تعليمات التمثيل التوليدي: 2024
Muennighoff ، Niklas and Su ، Hongjin and Wang ، Liang ... 2 Hidden ... Yu ، Tao and Singh ، Amanpreet and Kiela ، Douwe
تصفية المحتوى السام والصريح
العودة إلى جدول المحتويات
- استكشاف حدود التعلم النقل باستخدام محول نص إلى نص موحد: 2020
رافيل ، كولين وشازير ، نام وروبرتس ، آدم ... 3 مخفي ... تشو ، يانكي ولي ، وي وليو ، بيتر ج.
- MT5: محول نص إلى نص متعدد اللغات على نطاق واسع: 2021
Xue ، Linting و Constant ، نوح وروبرتس ، آدم ... 2 مخفي ... Siddhant ، Aditya و Barua ، Aditya و Raffel ، Colin
- في حيرة من الجودة: طريقة قائمة على الحيرة للكشف عن المحتوى البالغ والضرر في بيانات الويب غير المتجانسة متعددة اللغات: 2022
تيم يانسن ويانغلينج تونغ وفيكتوريا زيفالوس وبيدرو أورتيز سواريز
- نماذج لغة التحجيم: الأساليب والتحليل والرؤى من تدريب Gopher: 2022
جاك دبليو راي وسيباستيان بورجيود وتريفور كاي ... 74 مخفيًا ... ديميس هاسابيس وكوراي كافوكوغلو وجيفري إيرفينغ
- مجموعة BigScience Roots: مجموعة بيانات متعددة اللغات مركبة 1.6 تيرابايت: 2022
لورينكونون ، هوغو وسولنييه ، لوسيل ووانغ ، توماس ... 48 مخفيًا ... ميتشل ، مارغريت ولوكوني ، ساشا ألكسندرا وجيرنيت ، ياسين
- من الذي تعتبر اللغة عالية الجودة؟ قياس أيديولوجيات اللغة في اختيار البيانات النصية: 2022
Gururangan ، Schoin and Card ، Dallas and Dreier ، Sarah ... 2 Hidden ... Wang ، Zeyu and Zettlemoyer ، Luke and Smith ، Noah A.
- دليل ما قبل الأملس لبيانات التدريب: قياس آثار عمر البيانات وتغطية المجال والجودة والسمية: 2023
شاين لونجبر وجريجوري يوني وإميلي ريف ... 5 مخفي ... كيفن روبنسون وديفيد ممنو ودافني إيبوليتو
- تم العثور على مجموعة بيانات تدريب الصور من الذكاء الاصطناعي لتشمل صور الاعتداء الجنسي على الأطفال: 2023
ديفيد ، إميليا
- اكتشاف المعلومات الشخصية في شركة التدريب: تحليل: 2023
Subramani ، Nishant و Luccioni ، ساشا ودودج ، جيسي وميتشل ، مارغريت
- التقرير الفني GPT-4: 2023
Openai و: Josh Achiam ... 276 Hidden ... Juntang Zhuang و William Zhuk و Barret Zoph
- Santacoder: لا تصل إلى النجوم !: 2023
Allal ، Loubna Ben and Li ، Raymond and Kocetkov ، Denis ... 5 Hidden ... Gu ، Alex and Dey ، Manan and others
- مجموعة بيانات refressedweb لـ Falcon LLM: تفوق الأداء المبرمج مع بيانات الويب ، وبيانات الويب فقط: 2023
Guilherme Penedo و Quentin Malartic و Daniel Hesslow ... 3 Hidden ... Baptiste Pannier و Ebtesam Almazrouei و Julien Launay
- مؤشر شفافية نموذج الأساس: 2023
Bommasani ، Rishi and Klyman ، Kevin and Longpre ، Shayne ... 2 Hidden ... Xiong ، Betty and Zhang ، Daniel and Liang ، Percy
- ماذا يوجد في بياناتي الكبيرة ؟: 2023
Elazar ، Yanai و Bhagia ، Akshita و Magnusson ، Ian ... 5 Hidden ... Soldaini ، Luca and Singh ، Sameer وغيرها
- Dolma: مجموعة مفتوحة من ثلاثة تريليونات الرموز لنموذج اللغة الأبحاث المسبق: 2024
لوكا سولديني ورودني كيني وأكشيتا بهاجيا ... 30 مخفيًا ... ديرك جرينفيلد وجيسي دودج وكايل لو
- Olmo: تسريع نماذج علم اللغة: 2024
Groeneveld ، Dirk and Beltagy ، Iz and Walsh ، Pete ... 5 Hidden ... Magnusson ، Ian and Wang ، Yizhong and others
اختيار متخصص للنماذج متعددة اللغات
العودة إلى جدول المحتويات
- بلوم: نموذج لغة متعددة اللغات مفتوحة 176B المعلمة: 2022
ورشة العمل ، BigScience و Scao ، Teven Le and Fan ، Angela ... 5 Hidden ... Luccioni ، Alexandra Sasha and Yvon ، Franccois وغيرها
- الجودة في لمحة: مراجعة لمجموعات البيانات متعددة اللغات المتجول على شبكة الإنترنت: 2022
Kreutzer و Julia و Caswell و Isaac و Wang و Lisa ...
- مجموعة BigScience Roots: مجموعة بيانات متعددة اللغات مركبة 1.6 تيرابايت: 2022
لورينكونون ، هوغو وسولنييه ، لوسيل ووانغ ، توماس ... 48 مخفيًا ... ميتشل ، مارغريت ولوكوني ، ساشا ألكسندرا وجيرنيت ، ياسين
- ما هو نموذج اللغة للتدريب إذا كان لديك مليون ساعة GPU ؟: 2022
Scao ، Teven Le and Wang ، Thomas and Hesslow ، Daniel ... 5 Hidden ... Muennighoff ، Niklas and Phang ، Jason and others
- MADLAD-400: مجموعة بيانات مراجعة كبيرة متعددة اللغات ومستوى كبير: 2023
Kudugunta و Sneha و Caswell و Isaac and Zhang و Biao ... 5 Hidden ... Stella و Romi و Bapna و Ankur وغيرها
- تحجيم نماذج اللغة متعددة اللغات ضمن البيانات المقيدة: 2023
SCAO ، TEVEN LE
- AYA Dataset: مجموعة مفتوحة الوصول لضبط التعليمات متعددة اللغات: 2024
شيفالكا سينغ وفريدي فارغوس ودانييل ديسوزا ... 27 مخفيًا ... أحمد أوستون ومارزيه فادا وسارة هوكر
خلط البيانات
العودة إلى جدول المحتويات
- مشكلة اللصوص المتعددة غير المستقرة: 2002
Auer و Peter و Cesa-Bianchi و Nicol`o و Freund و Yoav و Schapire ، Robert E.
- نمذجة اللغة القوية التوزيعي: 2019
أورين ويوناتان وساجاوا ، شيوري وهاشيموتو ، تاتسونوري ب. وليانغ ، بيرسي
- شبكات عصبية قوية توزيعيًا: 2020
شيوري ساجاوا وبانغ وي كوه وتاتسونوري ب. هيشيموتو وبيرسي ليانغ
- استكشاف حدود التعلم النقل باستخدام محول نص إلى نص موحد: 2020
رافيل ، كولين وشازير ، نام وروبرتس ، آدم ... 3 مخفي ... تشو ، يانكي ولي ، وي وليو ، بيتر ج.
- الوبر: مجموعة بيانات 800 جيجابايت من النص المتنوع لنمذجة اللغة: 2020
ليو جاو وستيلا بايدرمان وسيد بلاك ... 6 مخفي ... نوا نابشيما وشون بريسر وكونور ليهي
- نماذج لغة التحجيم: الأساليب والتحليل والرؤى من تدريب Gopher: 2022
جاك دبليو راي وسيباستيان بورجيود وتريفور كاي ... 74 مخفيًا ... ديميس هاسابيس وكوراي كافوكوغلو وجيفري إيرفينغ
- glam: تحجيم فعال لنماذج اللغة مع الخبراء الخليط: 2022
Du ، Nan and Huang ، Yanping and Dai ، Andrew M ... 21 Hidden ... Wu ، Yonghui and Chen ، Zhifeng and Cui ، Claire
- الإشراف عبر اللغات يحسن نماذج اللغة الكبيرة قبل التدريب: 2023
أندريا شيوبا وكزافييه جارسيا وأورهان فيرات
- [DOGE: إعادة وزن المجال مع تقدير التعميم] (https://arxiv.org/abs/arxiv preprint): 2023
Simin Fan و Matteo Pagliardini و Martin Jaggi
- Doremi: تحسين خلائط البيانات يسرع نموذج اللغة ما قبل التنفيذ: 2023
سانج مايكل شيه وهيو فام وشوكاني دونغ ... 4 مخفي ... Quoc v le و Tengyu Ma و Adams Wei Yu
- خلط البيانات الفعال عبر الإنترنت لنموذج اللغة قبل التدريب: 2023
ألون ألبالاك وليانغمينغ بان وكولين رافيل وويليام يانغ وانغ
- لاما: نماذج لغة الأساس المفتوحة والفعالة: 2023
Hugo Touvron و Thibaut Lavril و Gautier Izacard ... 8 Hidden ... Armand Joulin و Edouard Grave و Guillaume Lample
- Pythia: جناح لتحليل نماذج اللغة الكبيرة عبر التدريب والتوسيع: 2023
Biderman ، Stella and Schoelkopf ، Hailey and Anthony ، Quentin Gregory ... 7 Hidden ... Skowron ، Aviya and Sutawika ، Lintang and Van Der Wal
- تحجيم نماذج اللغة المقيدة للبيانات: 2023
نيكلاس موينغوف وألكساندر م راش وبعز باراك ... 3 مخفي ... سامبو بيزالو وتوماس وولف وكولين رافيل
- Llama القص: تسريع نموذج اللغة قبل التدريب عبر التقليم منظم: 2023
Mengzhou Xia و Tianyu Gao و Zhiyuan Zeng و Danqi Chen
- مهارة! إطار مهارات تعتمد على البيانات لفهم وتدريب نماذج لغة: 2023
Mayee F. Chen و Nicholas Roberts and Kush Bhatia ... 1 Hidden ... Ce Zhang and Frederic Sala and Christopher Ré
اختيار البيانات لتدريب التعليمات والتدريب متعدد المهام
العودة إلى جدول المحتويات
- العشاري اللغوي الطبيعي: التعلم متعدد المهام كأسئلة الإجابة: 2018
ماكان ، برايان وكيسكار ، نيتيش شيريش وشيونغ ، كايمينغ وسيتشر ، ريتشارد
- توحيد الإجابة على الأسئلة ، وتصنيف النص ، والانحدار عبر استخراج الممتدة: 2019
كيسكار ، نيتيش شيريش وماكان ، برايان وشيونج ، كايمينغ وسيتشر ، ريتشارد
- شبكات عصبية عميقة متعددة المهام لفهم اللغة الطبيعية: 2019
Liu و Xiaodong و He و Pengcheng و Chen و Weizhu و Gao ، Jianfeng
- UnifiedQA: حدود التنسيق مع نظام QA واحد: 2020
Khashabi ، Daniel and Min ، Sewon and Khot ، Tushar ... 1 Hidden ... Tafjord ، Oyvind and Clark ، Peter and Hajishirzi ، Hannaneh
- استكشاف حدود التعلم النقل باستخدام محول نص إلى نص موحد: 2020
رافيل ، كولين وشازير ، نام وروبرتس ، آدم ... 3 مخفي ... تشو ، يانكي ولي ، وي وليو ، بيتر ج.
- Muppet: تمثيلات ضخمة متعددة المهام مع التمثيل المسبق: 2021
Aghajanyan و Armen و Gupta و Anchit و Shrivastava و Akshat و Chen و Xilun و Zettlemoyer و Luke و Gupta ، Sonal
- نماذج اللغة المبتذلة هي متعلمين صفري: 2021
Wei و Jason و Bosma و Maarten and Zhao و Vincent Y .... 3 Hidden ... Du ، Nan and Dai ، Andrew M. and Le ، Quoc V.
- التعميم عبر المهام عبر تعليمات التعهيد الجماعي للغة الطبيعية: 2021
ميشرا ، سواروب وخشابي ، دانيال وبارال ، تشيتا وهاجشييرزي ، هانانه
- NL-AUGMENTER: إطار لزيادة اللغة الطبيعية الحساسة للمهمة: 2021
Dhole و Kaustubh D و Gangal و Varun و Gehrmann و Sebastian ... 5 Hidden ... Shrivastava و Ashish and Tan و Samson وغيرها
- Ext5: نحو التحجيم المتطرف متعدد المهام للتعلم النقل: 2021
Aribandi ، Vamsi and Tay ، Yi and Schuster ، Tal ... 5 Hidden ... Bahri ، Dara and Ni ، Jianmo and others
- super-naturalinstructions: التعميم عبر التعليمات التعريفية على 1600+ NLP: 2022
وانغ ، يزهونغ وميشرا ، سواروب وأليبورمولاباشي ، بيجاه ... 29 مخفيًا ... باتو ، سومانتا وديكسيت ، تاناي وشين ، Xudong
- نماذج لغة التعليمات المليئة بالتعليمات: 2022
Chung ، Hyung Won و Hou ، Le and Longpre ، Shayne ... 5 Hidden ... Dehghani ، Mostafa و Brahma ، Siddhartha and others
- Bloom+ 1: إضافة دعم اللغة إلى Bloom for Zero-Shot Prompting: 2022
Yong و Zheng-xin و Schoelkopf و Hailey و Muennighoff و Niklas ... 5 Hidden ... Kasai و Jungo و Baruwa ، أحمد وغيرها
- OPT-IML: تعليم نموذج لغة التحجيم التعليمية التعليمية من خلال عدسة التعميم: 2022
Srinivasan Iyer و Xi Victoria Lin و Ramakanth Pasunuru ... 12 Hidden ... Asli Celikyilmaz و Luke Zettlemoyer و Ves Stoyanov
- metaicl: تعلم التعلم في السياق: 2022
Min ، Sewon و Lewis ، Mike and Zettlemoyer ، Luke and Hajishirzi ، Hannaneh
- تعليمات غير طبيعية: نماذج لغة ضبط مع (تقريبا) لا عمل بشري: 2022
Honovich ، أو Scialom ، Thomas و Levy ، Omer و Schick ، Timo
- التعميم المتقاطع من خلال تعدد المهام Finetuning: 2022
Muennighoff ، Niklas and Wang ، Thomas و Sutawika ، Lintang ... 5 Hidden ... Yong ، Zheng-Xin and Schoelkopf ، Hailey and others
- تمكين المهام المتعددة التي تمكن التدريب من التعميم على المهمة: 2022
فيكتور سانه وألبرت ويبسون وكولين رافيل ... 34 مخفيًا ... ليو جاو وتوماس وولف وألكساندر م.
- بروميثيوس: تحفيز قدرة التقييم الدقيقة في نماذج اللغة: 2023
كيم ، سونغون وشين ، جامين وشو ، ياجين ... 5 مخبأة ... كيم ، سونغدونغ وشورن ، جيمس وآخرون
- Slimorca: مجموعة بيانات مفتوحة من آثار التفكير الفلان المعزز GPT-4 ، مع التحقق: 2023
Wing Lian and Guan Wang and Bleys Goodson ... 1 Hidden ... Austin Cook and Chanvichet Vong و "Teknium"
- هل يسرق فن الذكاء الاصطناعي من الفنانين ؟: 2023
تشايكا ، كايل
- Paul Tremblay ، Mona Awad vs. Openai ، Inc. ، et al.: 2023
Saveri ، Joseph R. and Zirpoli ، Cadio and Young ، Christopher KL and McMahon ، Kathleen J.
- جعل نماذج اللغة الكبيرة أفضل منشئي البيانات: 2023
لي ، دونغ هو وبوجارا ، جاي وسوباك ، موهيت وايت ، راين وجوهر ، سوجي
- مجموعة Flan: تصميم البيانات وطرق لضبط التعليمات الفعالة: 2023
شاين لونجبر ولو هو وتو فو ... 5 مخفي ... باريت زوف وجيسون وي وآدم روبرتس
- WizardLM: تمكين نماذج اللغة الكبيرة لمتابعة التعليمات المعقدة: 2023
Xu ، Can and Sun ، Qingfeng and Zheng ، Kai ... 2 Hidden ... Feng ، Jiazhan and Tao ، Chongyang and Jiang ، Daxin
- ليما: أقل من ذلك بالنسبة للمحاذاة: 2023
Chunting Zhou و Pengfei Liu و Puxin Xu ... 9 Hidden ... Mike Lewis و Luke Zettlemoyer و Omer Levy
- الجمال في مناخ متغير: تعزيز تكيف LM مع Tulu 2: 2023
هاميش إيفسون ويزهونغ وانغ وفالنتينا بياتكين ... 5 مخفي ... نوح أ.
- البنية الذاتية: محاذاة نماذج اللغة مع التعليمات التي يتم إنشاؤها ذاتيا: 2023
وانغ ، يزهونغ وكوردي ، يوجانه وميشرا ، سواروب ... 1 مخفي ... سميث ، نوح أ.
- ما الذي يجعل البيانات الجيدة للمحاذاة؟ دراسة شاملة لاختيار البيانات التلقائي في ضبط التعليمات: 2023
ليو ووي وزينج ، ويهاو وهو ، كينغ وجيانغ ، يونغ ، هو ، جونكسيان
- ضبط التعليمات لنماذج اللغة الكبيرة: استطلاع: 2023
Shengyu Zhang و Linfeng Dong و Xiaoya Li ... 5 Hidden ... Tianwei Zhang و Fei Wu و Guoyin Wang
- ستانفورد الألباكا: نموذج لاما يتبع التعليمات: 2023
روهان تاوري وإيشان جولراجاني وتيانيي تشانغ ... 2 مخفي ... كارلوس غوسترين وبيرسي ليانغ وتاتسونوري ب.
- إلى أي مدى يمكن أن تذهب الجمال؟ استكشاف حالة تعليمات توليف الموارد المفتوحة: 2023
Yizhong Wang و Hamish Ivison and Pradeep Dasigi ... 5 Hidden ... Noah A. Smith and Iz Beltagy and Hannaneh Hajishirzi
- محادثات OpenAssistant--إتخوضية نموذج اللغة الديموقراطية المحاذاة: 2023
K "OPF ، Andreas and Kilcher ، Yannic and Von R" Utte ، Dimitri ... 5 Hidden ... Stanley ، Oliver and Nagyfi ، Rich'ard and others
- Octopack: رمز توليف التعليمات نماذج لغة كبيرة: 2023
نيكلاس موينغوف وتشيان ليو وأرميل زيباز ... 4 مخفي ... شيانجرو تانغ وليندرو فون ويرا وشاين لونجبير
- الذات: التطور الذاتي الذي يحركه اللغة لنموذج اللغة الكبيرة: 2023
Lu و Jianqiao و Zhong و Wanjun و Huang و Wenyong ... 3 Hidden ... Wang ، Weicha و Shang ، Lifeng و Liu ، Qun
- مجموعة Flan: تصميم البيانات وطرق لضبط التعليمات الفعالة: 2023
Longpre ، Shayne and Hou ، Le and Vu ، Tu ... 5 Hidden ... Zoph ، Barret and Wei ، Jason and Roberts ، Adam
- #Instag: علامات التعليمات لتحليل النماذج اللغوية الخاضعة للإشراف: 2023
Keming Lu و Hongyi Yuan and Zheng Yuan ... 2 Hidden ... Chuanqi Tan and Chang Zhou and Jingren Zhou
- تعليمات التعليمات: عندما يلبي استخراج البيانات نموذج اللغة الكبيرة: 2023
Yihan Cao و Yanbin Kang و Chi Wang و Lichao Sun
- ضبط التعليمات النشطة: تحسين التعميم عبر المهام عن طريق التدريب على المهام الحساسة السريعة: 2023
Po-Nien Kung and Fan Yin and Di Wu و Kai-Wei Chang و Nanyun Peng
- مبادرة مصدر البيانات: تدقيق واسع النطاق لترخيص مجموعة البيانات وإسناده في الذكاء الاصطناعي: 2023
Longpre ، Shayne و Mahari ، Robert and Chen ، Anthony ... 5 Hidden ... Kabbara ، Jad and Perisetla ، Kartik and others
- AYA Dataset: مجموعة مفتوحة الوصول لضبط التعليمات متعددة اللغات: 2024
شيفالكا سينغ وفريدي فارغوس ودانييل ديسوزا ... 27 مخفيًا ... أحمد أوستون ومارزيه فادا وسارة هوكر
- Astraios: رمز توليف التعليمات الموفرة للمعلمة نماذج لغة كبيرة: 2024
Zhuo و Terry Yue و Zebaze و Armel and Suppattarachai و Nitchakarn ... 1 Hidden ... de Vries و Harm and Liu و Qian and Muennighf ، Niklas
- AYA Model: نموذج لغة متعددة اللغات من تعليمات التعليمات: 2024
"ust" un ، ahmet و aryabumi ، viraat and yong ، Zheng-xin ... 5 Hidden ... ooi ، hui-lee and kayid ، amr and others
- نماذج لغة أصغر قادرة على اختيار بيانات تدريب تعليمات لضرب النماذج اللغوية الأكبر: 2024
Dheeraj Mekala و Alex Nguyen و Jingbo Shang
- تنشيط البيانات الآلية لنموذج اللغة القوية النمو: 2024
جيهاي تشن وجوناس مولر
اختيار البيانات لضبط التفضيل: المحاذاة
العودة إلى جدول المحتويات
- WebGPT: إجابة أسئلة بمساعدة المتصفح مع ردود الفعل البشرية: 2021
Nakano ، Reiichiro و Hilton ، Jacob and Balaji ، Suchir ... 5 Hidden ... Kosaraju ، Vineet and Saunders ، William and others
- تدريب مساعد مفيد وغير ضار مع التعلم التعزيز من ردود الفعل البشرية: 2022
باي ، يونتاو وجونز ، آندي و ندوس ، كمال ... 5 مخبأة ... جانجولي ، عميق وهنغان ، توم وغيرها
- فهم مجموعة البيانات مع $ mathcalv $-معلومات قابلة للاستخدام: 2022
Ethayarajh ، Kawin and Choi ، Yejin و Swayamdipta ، Swabha
- منظمة العفو الدولية الدستورية: إلحاق الضرر من منظمة العفو الدولية: 2022
باي ، يونتاو وكادافاث ، سوراف وكوندو ، سانديبان ... 5 مخفي ... ميرهسيني ، أزاليا وماكينون ، كاميرون وآخرون
- بروميثيوس: تحفيز قدرة التقييم الدقيقة في نماذج اللغة: 2023
كيم ، سونغون وشين ، جامين وشو ، ياجين ... 5 مخبأة ... كيم ، سونغدونغ وشورن ، جيمس وآخرون
- Notus: 2023
ألفارو بارتولوم وجابرييل مارتن ودانييل فيلا
- الترافعة الفائقة: تعزيز نماذج اللغة مع ردود الفعل عالية الجودة: 2023
Ganqu Cui and Lifan Yuan and Ning Ding... 3 hidden ... Guotong Xie and Zhiyuan Liu and Maosong Sun
- Exploration with Principles for Diverse AI Supervision: 2023
Liu, Hao and Zaharia, Matei and Abbeel, Pieter
- Wizardlm: Empowering large language models to follow complex instructions: 2023
Xu, Can and Sun, Qingfeng and Zheng, Kai... 2 hidden ... Feng, Jiazhan and Tao, Chongyang and Jiang, Daxin
- LIMA: Less Is More for Alignment: 2023
Chunting Zhou and Pengfei Liu and Puxin Xu... 9 hidden ... Mike Lewis and Luke Zettlemoyer and Omer Levy
- Shepherd: A Critic for Language Model Generation: 2023
Tianlu Wang and Ping Yu and Xiaoqing Ellen Tan... 4 hidden ... Luke Zettlemoyer and Maryam Fazel-Zarandi and Asli Celikyilmaz
- No Robots: 2023
Nazneen Rajani and Lewis Tunstall and Edward Beeching and Nathan Lambert and Alexander M. Rush and Thomas Wolf
- Starling-7B: Improving LLM Helpfulness & Harmlessness with RLAIF: 2023
Zhu, Banghua and Frick, Evan and Wu, Tianhao and Zhu, Hanlin and Jiao, Jiantao
- Scaling laws for reward model overoptimization: 2023
Gao, Leo and Schulman, John and Hilton, Jacob
- SALMON: Self-Alignment with Principle-Following Reward Models: 2023
Zhiqing Sun and Yikang Shen and Hongxin Zhang... 2 hidden ... David Cox and Yiming Yang and Chuang Gan
- Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback: 2023
Stephen Casper and Xander Davies and Claudia Shi... 26 hidden ... David Krueger and Dorsa Sadigh and Dylan Hadfield-Menell
- Camels in a Changing Climate: Enhancing LM Adaptation with Tulu 2: 2023
Hamish Ivison and Yizhong Wang and Valentina Pyatkin... 5 hidden ... Noah A. Smith and Iz Beltagy and Hannaneh Hajishirzi
- Llama 2: Open Foundation and Fine-Tuned Chat Models: 2023
Hugo Touvron and Louis Martin and Kevin Stone... 62 hidden ... Robert Stojnic and Sergey Edunov and Thomas Scialom
- What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning: 2023
Liu, Wei and Zeng, Weihao and He, Keqing and Jiang, Yong and He, Junxian
- HuggingFace H4 Stack Exchange Preference Dataset: 2023
Lambert, Nathan and Tunstall, Lewis and Rajani, Nazneen and Thrush, Tristan
- Textbooks Are All You Need: 2023
Gunasekar, Suriya and Zhang, Yi and Aneja, Jyoti... 5 hidden ... de Rosa, Gustavo and Saarikivi, Olli and others
- Quality-Diversity through AI Feedback: 2023
Herbie Bradley and Andrew Dai and Hannah Teufel... 4 hidden ... Kenneth Stanley and Grégory Schott and Joel Lehman
- Direct preference optimization: Your language model is secretly a reward model: 2023
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Ermon, Stefano and Manning, Christopher D and Finn, Chelsea
- Scaling relationship on learning mathematical reasoning with large language models: 2023
Yuan, Zheng and Yuan, Hongyi and Li, Chengpeng and Dong, Guanting and Tan, Chuanqi and Zhou, Chang
- The History and Risks of Reinforcement Learning and Human Feedback: 2023
Lambert, Nathan and Gilbert, Thomas Krendl and Zick, Tom
- Zephyr: Direct distillation of lm alignment: 2023
Tunstall, Lewis and Beeching, Edward and Lambert, Nathan... 5 hidden ... Fourrier, Cl'ementine and Habib, Nathan and others
- Perils of Self-Feedback: Self-Bias Amplifies in Large Language Models: 2024
Wenda Xu and Guanglei Zhu and Xuandong Zhao and Liangming Pan and Lei Li and William Yang Wang
- Suppressing Pink Elephants with Direct Principle Feedback: 2024
Louis Castricato and Nathan Lile and Suraj Anand and Hailey Schoelkopf and Siddharth Verma and Stella Biderman
- West-of-N: Synthetic Preference Generation for Improved Reward Modeling: 2024
Alizée Pace and Jonathan Mallinson and Eric Malmi and Sebastian Krause and Aliaksei Severyn
- Statistical Rejection Sampling Improves Preference Optimization: 2024
Liu, Tianqi and Zhao, Yao and Joshi, Rishabh... 1 hidden ... Saleh, Mohammad and Liu, Peter J and Liu, Jialu
- Self-play fine-tuning converts weak language models to strong language models: 2024
Chen, Zixiang and Deng, Yihe and Yuan, Huizhuo and Ji, Kaixuan and Gu, Quanquan
- Self-Rewarding Language Models: 2024
Weizhe Yuan and Richard Yuanzhe Pang and Kyunghyun Cho and Sainbayar Sukhbaatar and Jing Xu and Jason Weston
- Theoretical guarantees on the best-of-n alignment policy: 2024
Beirami, Ahmad and Agarwal, Alekh and Berant, Jonathan... 1 hidden ... Eisenstein, Jacob and Nagpal, Chirag and Suresh, Ananda Theertha
- KTO: Model Alignment as Prospect Theoretic Optimization: 2024
Ethayarajh, Kawin and Xu, Winnie and Muennighoff, Niklas and Jurafsky, Dan and Kiela, Douwe
Data Selection for In-Context Learning
Back to Table of Contents
- Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks: 2019
Reimers, Nils and Gurevych, Iryna
- Language Models are Few-Shot Learners: 2020
Brown, Tom and Mann, Benjamin and Ryder, Nick... 25 hidden ... Radford, Alec and Sutskever, Ilya and Amodei, Dario
- True Few-Shot Learning with Language Models: 2021
Ethan Perez and Douwe Kiela and Kyunghyun Cho
- Active Example Selection for In-Context Learning: 2022
Zhang, Yiming and Feng, Shi and Tan, Chenhao
- Careful Data Curation Stabilizes In-context Learning: 2022
Chang, Ting-Yun and Jia, Robin
- Learning To Retrieve Prompts for In-Context Learning: 2022
Rubin, Ohad and Herzig, Jonathan and Berant, Jonathan
- Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity: 2022
Lu, Yao and Bartolo, Max and Moore, Alastair and Riedel, Sebastian and Stenetorp, Pontus
- What Makes Good In-Context Examples for GPT-3?: 2022
Liu, Jiachang and Shen, Dinghan and Zhang, Yizhe and Dolan, Bill and Carin, Lawrence and Chen, Weizhu
- MetaICL: Learning to Learn In Context: 2022
Min, Sewon and Lewis, Mike and Zettlemoyer, Luke and Hajishirzi, Hannaneh
- Unified Demonstration Retriever for In-Context Learning: 2023
Li, Xiaonan and Lv, Kai and Yan, Hang... 3 hidden ... Xie, Guotong and Wang, Xiaoling and Qiu, Xipeng
- Which Examples to Annotate for In-Context Learning? Towards Effective and Efficient Selection: 2023
Mavromatis, Costas and Srinivasan, Balasubramaniam and Shen, Zhengyuan... 1 hidden ... Rangwala, Huzefa and Faloutsos, Christos and Karypis, George
- Large Language Models Are Latent Variable Models: Explaining and Finding Good Demonstrations for In-Context Learning: 2023
Xinyi Wang and Wanrong Zhu and Michael Saxon and Mark Steyvers and William Yang Wang
- Selective Annotation Makes Language Models Better Few-Shot Learners: 2023
Hongjin SU and Jungo Kasai and Chen Henry Wu... 5 hidden ... Luke Zettlemoyer and Noah A. Smith and Tao Yu
- In-context Example Selection with Influences: 2023
Nguyen, Tai and Wong, Eric
- Coverage-based Example Selection for In-Context Learning: 2023
Gupta, Shivanshu and Singh, Sameer and Gardner, Matt
- Compositional exemplars for in-context learning: 2023
Ye, Jiacheng and Wu, Zhiyong and Feng, Jiangtao and Yu, Tao and Kong, Lingpeng
- Take one step at a time to know incremental utility of demonstration: An analysis on reranking for few-shot in-context learning: 2023
Hashimoto, Kazuma and Raman, Karthik and Bendersky, Michael
- Ambiguity-aware in-context learning with large language models: 2023
Gao, Lingyu and Chaudhary, Aditi and Srinivasan, Krishna and Hashimoto, Kazuma and Raman, Karthik and Bendersky, Michael
- IDEAL: Influence-Driven Selective Annotations Empower In-Context Learners in Large Language Models: 2023
Zhang, Shaokun and Xia, Xiaobo and Wang, Zhaoqing... 1 hidden ... Liu, Jiale and Wu, Qingyun and Liu, Tongliang
- ScatterShot: Interactive In-context Example Curation for Text Transformation: 2023
Wu, Sherry and Shen, Hua and Weld, Daniel S and Heer, Jeffrey and Ribeiro, Marco Tulio
- Diverse Demonstrations Improve In-context Compositional Generalization: 2023
Levy, Itay and Bogin, Ben and Berant, Jonathan
- Finding supporting examples for in-context learning: 2023
Li, Xiaonan and Qiu, Xipeng
- Misconfidence-based Demonstration Selection for LLM In-Context Learning: 2024
Xu, Shangqing and Zhang, Chao
- In-context Learning with Retrieved Demonstrations for Language Models: A Survey: 2024
Xu, Xin and Liu, Yue and Pasupat, Panupong and Kazemi, Mehran and others
Data Selection for Task-specific Fine-tuning
Back to Table of Contents
- A large annotated corpus for learning natural language inference: 2015
Bowman, Samuel R. and Angeli, Gabor and Potts, Christopher and Manning, Christopher D.
- GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding: 2018
Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel
- A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference: 2018
Williams, Adina and Nangia, Nikita and Bowman, Samuel
- Sentence Encoders on STILTs: Supplementary Training on Intermediate Labeled-data Tasks: 2019
Jason Phang and Thibault Févry and Samuel R. Bowman
- Distributionally Robust Neural Networks: 2020
Shiori Sagawa and Pang Wei Koh and Tatsunori B. Hashimoto and Percy Liang
- Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics: 2020
Swayamdipta, Swabha and Schwartz, Roy and Lourie, Nicholas... 1 hidden ... Hajishirzi, Hannaneh and Smith, Noah A. and Choi, Yejin
- Intermediate-Task Transfer Learning with Pretrained Language Models: When and Why Does It Work?: 2020
Pruksachatkun, Yada and Phang, Jason and Liu, Haokun... 3 hidden ... Vania, Clara and Kann, Katharina and Bowman, Samuel R.
- On the Complementarity of Data Selection and Fine Tuning for Domain Adaptation: 2021
Dan Iter and David Grangier
- FETA: A Benchmark for Few-Sample Task Transfer in Open-Domain Dialogue: 2022
Albalak, Alon and Tuan, Yi-Lin and Jandaghi, Pegah... 3 hidden ... Getoor, Lise and Pujara, Jay and Wang, William Yang
- LoRA: Low-Rank Adaptation of Large Language Models: 2022
Edward J Hu and yelong shen and Phillip Wallis... 2 hidden ... Shean Wang and Lu Wang and Weizhu Chen
- Training Subset Selection for Weak Supervision: 2022
Lang, Hunter and Vijayaraghavan, Aravindan and Sontag, David
- On-Demand Sampling: Learning Optimally from Multiple Distributions: 2022
Haghtalab, Nika and Jordan, Michael and Zhao, Eric
- The Trade-offs of Domain Adaptation for Neural Language Models: 2022
Grangier, David and Iter, Dan
- Data Pruning for Efficient Model Pruning in Neural Machine Translation: 2023
Azeemi, Abdul and Qazi, Ihsan and Raza, Agha
- Skill-it! A Data-Driven Skills Framework for Understanding and Training Language Models: 2023
Mayee F. Chen and Nicholas Roberts and Kush Bhatia... 1 hidden ... Ce Zhang and Frederic Sala and Christopher Ré
- D2 Pruning: Message Passing for Balancing Diversity and Difficulty in Data Pruning: 2023
Adyasha Maharana and Prateek Yadav and Mohit Bansal
- Improving Few-Shot Generalization by Exploring and Exploiting Auxiliary Data: 2023
Alon Albalak and Colin Raffel and William Yang Wang
- Efficient Online Data Mixing For Language Model Pre-Training: 2023
Alon Albalak and Liangming Pan and Colin Raffel and William Yang Wang
- Data-Efficient Finetuning Using Cross-Task Nearest Neighbors: 2023
Ivison, Hamish and Smith, Noah A. and Hajishirzi, Hannaneh and Dasigi, Pradeep
- Make Every Example Count: On the Stability and Utility of Self-Influence for Learning from Noisy NLP Datasets: 2023
Bejan, Irina and Sokolov, Artem and Filippova, Katja
- LESS: Selecting Influential Data for Targeted Instruction Tuning: 2024
Mengzhou Xia and Sadhika Malladi and Suchin Gururangan and Sanjeev Arora and Danqi Chen
مساهمة
There are likely some amazing works in the field that we missed, so please contribute to the repo.
Feel free to open a pull request with new papers or create an issue and we can add them for you. Thank you in advance for your efforts!
اقتباس
We hope this work serves as inspiration for many impactful future works. If you found our work useful, please cite this paper as:
@article{albalak2024survey,
title={A Survey on Data Selection for Language Models},
author={Alon Albalak and Yanai Elazar and Sang Michael Xie and Shayne Longpre and Nathan Lambert and Xinyi Wang and Niklas Muennighoff and Bairu Hou and Liangming Pan and Haewon Jeong and Colin Raffel and Shiyu Chang and Tatsunori Hashimoto and William Yang Wang},
year={2024},
journal={arXiv preprint arXiv:2402.16827},
note={url{https://arxiv.org/abs/2402.16827}}
}


