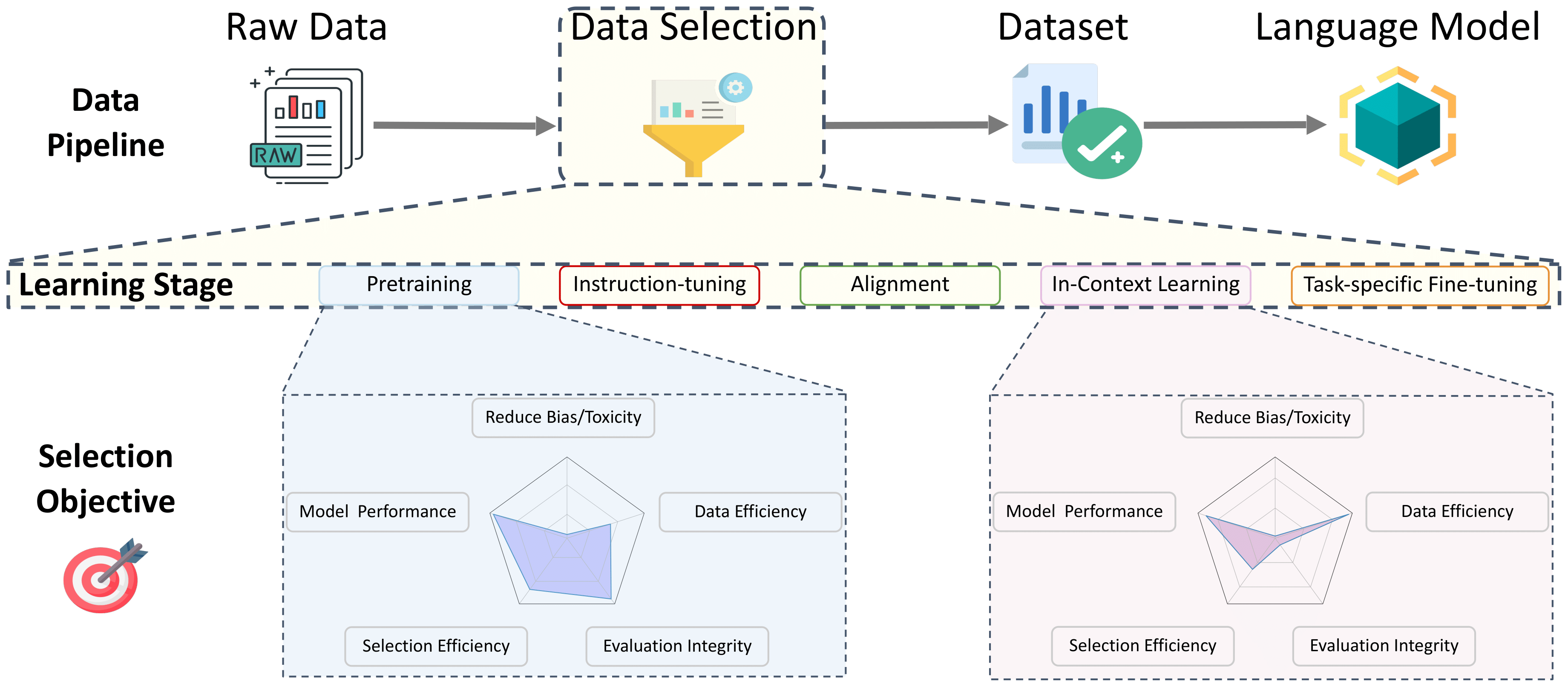
语言模型数据选择的调查
此存储库是在培训的所有阶段中与语言模型数据选择相关的论文列表。这是为了成为社区的资源,因此,如果您看到任何缺失的东西,请做出贡献!
有关这些作品的更多详细信息,以及更多信息,请参阅我们的调查论文:有关语言模型数据选择的调查。 By this incredible team: Alon Albalak, Yanai Elazar, Sang Michael Xie, Shayne Longpre, Nathan Lambert, Xinyi Wang, Niklas Muennighoff, Bairu Hou, Liangming Pan, Haewon Jeong, Colin Raffel, Shiyu Chang, Tatsunori Hashimoto, William Yang Wang
目录
- 预处理的数据选择
- 语言过滤
- 启发式方法
- 数据质量
- 特定于域的选择
- 数据删除
- 过滤有毒和明确的内容
- 多语言模型的专业选择
- 数据混合
- 指导调查和多任务培训的数据选择
- 偏好微调对齐的数据选择
- 对秘密学习的数据选择
- 针对特定任务的微调数据选择
预处理的数据选择
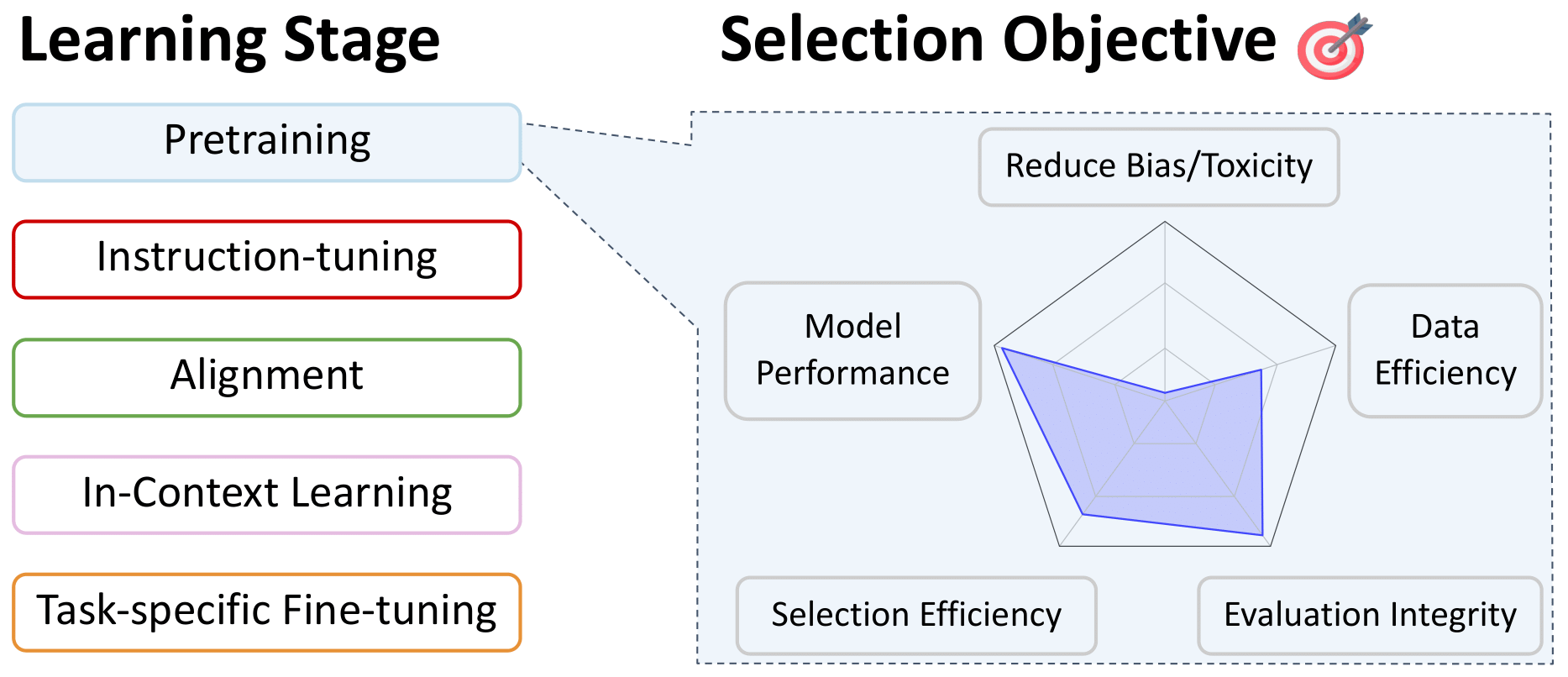
语言过滤
返回目录
- fastText.zip:压缩文本分类模型:2016
Armand Joulin和Edouard Grave和Piotr Bojanowski和Matthijs Douze和HérveJégou和Tomas Mikolov
- 157种语言的学习单词向量:2018
Grave,Edouard和Bojanowski,Piotr和Gupta,Prakhar和Joulin,Armand和Mikolov,Tomas
- 跨语性语言模型预读:2019年
康纳,亚历克西斯和莱姆,纪念
- 通过统一的文本到文本变压器探索转移学习的限制:2020
拉斐尔,科林和谢瑟,诺阿姆和罗伯茨,亚当... 3隐藏... Zhou,Yanqi和Li,Wei和Liu,Peter J.
- 野外语言ID:一千个语言网络文本语料库的意外挑战:2020
Caswell,Isaac和Breiner,Theresa和Van Esch,Daan和Bapna,Ankur
- 无监督的跨语性表示学习:2020
Conneau,Alexis和Khandelwal,Kartikay和Goyal,Naman ... 4 Hidden ... Ott,Myle和Zettlemoyer,Luke和Stoyanov,Veselin
- CCNET:从Web爬网提取高质量的单语数据集:2020
Wenzek,Guillaume和Lachaux,Marie-Anne和Conneau,Alexis ... 1隐藏... Guzm'an,Francisco和Joulin,Armand and Grave,Edouard
- 苹果双向LSTM模型的复制在短字符串中:2021
Toftrup,Mads和Asger Sorensen,Soren和Ciosici,Manuel R.和Assent,IRA
- 评估经过代码培训的大型语言模型:2021
Mark Chen和Jerry Tworek和Heewoo Jun ... 52 Hidden ... Sam McCandlish和Ilya Sutskever和Wojciech Zaremba
- MT5:大规模多语言预训练的文本到文本变压器:2021
Xue,linting and Constant,Noah and Roberts,Adam ... 2隐藏... Siddhant,Aditya和Barua,Aditya和Raffel,Colin
- 竞争级代码生成字母:2022
Li,Yujia和Choi,David和Chung,Junyoung ... 20 Hidden ... De Freitas,Nando和Kavukcuoglu,Koray和Vinyals,Oriol
- 棕榈:用途径缩放语言建模:2022
Aakanksha Chowdhery和Sharan Narang和Jacob Devlin ... 61 Hissed ... Jeff Dean和Slav Petrov和Noah Fiedel
- Bigscience根源语料库:1.6TB复合多语言数据集:2022
Laurenccon,Hugo和Saulnier,Lucile和Wang,Thomas ... 48 Hidden ... Mitchell,Margaret和Luccioni,Sasha Alexandra和Jernite,Yacine,Yacine
- 2800多种语言品种的写作系统和发言人元数据:2022
Van Esch,Daan和Lucassen,Tamar和Ruder,Sebastian和Caswell,Isaac和Rivera,Clara
- 指点:小语言的大型生成模型:2023
Luukkonen,Risto和Komulainen,Ville和Luoma,Jouni ... 5隐藏... Muennighoff,Niklas和Piktus,Aleksandra等
- MC^ 2:中国的多语言少数语言:2023
Zhang,Chen和Tao,Mingxu和Huang,Quzhe和Lin,Jiuheng and Chen,Zhibin和Feng,Yansong
- MADLAD-400:多语言和文档级的大型审计数据集:2023
Kudugunta,Sneha和Caswell,Isaac和Zhang,Biao ... 5隐藏... Stella,Romi和Bapna,Ankur等
- Falcon LLM的精制网络数据集:胜过Web数据的策划Corpora,仅Web数据:2023
Guilherme Penedo和Quentin Malartic和Daniel Hesslow ... 3隐藏... Baptiste Pannier和Ebtesam Almazrouei和Julien Launay
- Dolma:用于语言模型预处理研究的三亿代币的开放语料库:2024
卢卡·索尔纳尼(Luca Soldaini)和罗德尼·金尼(Rodney Kinney)和阿克希塔·巴吉亚(Akshita Bhagia)... 30隐藏... Dirk Groeneveld和Jesse Dodge和Kyle Lo
启发式方法
返回目录
- 通过统一的文本到文本变压器探索转移学习的限制:2020
拉斐尔,科林和谢瑟,诺阿姆和罗伯茨,亚当... 3隐藏... Zhou,Yanqi和Li,Wei和Liu,Peter J.
- 语言模型是很少的学习者:2020
布朗,汤姆和曼恩,本杰明和莱德,尼克... 25隐藏...拉德福德,亚历克和萨斯克弗,伊利亚和阿莫迪,达里奥
- 堆:语言建模的800GB数据集:2020
Leo Gao和Stella Biderman和Sid Black ... 6隐藏... Noa Nabeshima和Shawn Presser和Connor Leahy
- 评估经过代码培训的大型语言模型:2021
Mark Chen和Jerry Tworek和Heewoo Jun ... 52 Hidden ... Sam McCandlish和Ilya Sutskever和Wojciech Zaremba
- MT5:大规模多语言预训练的文本到文本变压器:2021
Xue,linting and Constant,Noah and Roberts,Adam ... 2隐藏... Siddhant,Aditya和Barua,Aditya和Raffel,Colin
- 缩放语言模型:训练Gopher的方法,分析和见解:2022
杰克·W·雷(Jack W.
- Bigscience根源语料库:1.6TB复合多语言数据集:2022
Laurenccon,Hugo和Saulnier,Lucile和Wang,Thomas ... 48 Hidden ... Mitchell,Margaret和Luccioni,Sasha Alexandra和Jernite,Yacine,Yacine
- HTLM:语言模型的超文本预培训和提示:2022
Armen Aghajanyan和Dmytro Okhonko和Mike Lewis ... 1隐藏... Hu Xu和Gargi Ghosh和Luke Zettlemoyer
- 骆驼:开放有效的基础语言模型:2023
Hugo Touvron和Thibaut Lavril和Gautier Izacard ... 8隐藏... Armand Joulin和Edouard Grave和Guillaume Lample
- Falcon LLM的精制网络数据集:胜过Web数据的策划Corpora,仅Web数据:2023
Guilherme Penedo和Quentin Malartic和Daniel Hesslow ... 3隐藏... Baptiste Pannier和Ebtesam Almazrouei和Julien Launay
- 基础模型透明度指数:2023
Bommasani,Rishi和Klyman,Kevin和Longpre,Shayne ... 2 Hidden ... Xiong,Betty和Zhang,Daniel和Liang,Percy
- Dolma:用于语言模型预处理研究的三亿代币的开放语料库:2024
卢卡·索尔纳尼(Luca Soldaini)和罗德尼·金尼(Rodney Kinney)和阿克希塔·巴吉亚(Akshita Bhagia)... 30隐藏... Dirk Groeneveld和Jesse Dodge和Kyle Lo
数据质量
返回目录
- Kenlm:更快,较小的语言模型查询:2011年
肯尼斯Heafiel
- fastText.zip:压缩文本分类模型:2016
Armand Joulin和Edouard Grave和Piotr Bojanowski和Matthijs Douze和HérveJégou和Tomas Mikolov
- 157种语言的学习单词向量:2018
Grave,Edouard和Bojanowski,Piotr和Gupta,Prakhar和Joulin,Armand和Mikolov,Tomas
- 语言模型是无监督的多任务学习者:2019年
亚历克·拉德福德(Alec Radford)和杰夫·吴(Jeff Wu)和雷沃(Rewon)的孩子,大卫·卢恩(David Luan)和达里奥·阿莫迪(Dario Amodei)
- 语言模型是很少的学习者:2020
布朗,汤姆和曼恩,本杰明和莱德,尼克... 25隐藏...拉德福德,亚历克和萨斯克弗,伊利亚和阿莫迪,达里奥
- 堆:语言建模的800GB数据集:2020
Leo Gao和Stella Biderman和Sid Black ... 6隐藏... Noa Nabeshima和Shawn Presser和Connor Leahy
- CCNET:从Web爬网提取高质量的单语数据集:2020
Wenzek,Guillaume和Lachaux,Marie-Anne和Conneau,Alexis ... 1隐藏... Guzm'an,Francisco和Joulin,Armand and Grave,Edouard
- 排毒的语言模型风险将少数民族的声音边缘化:2021
Xu,Albert和Pathak,Eshaan和Wallace,Eric和Gururangan,Suchin和Sap,Maarten和Klein,Dan
- 棕榈:用途径缩放语言建模:2022
Aakanksha Chowdhery和Sharan Narang和Jacob Devlin ... 61 Hissed ... Jeff Dean和Slav Petrov和Noah Fiedel
- 缩放语言模型:训练Gopher的方法,分析和见解:2022
杰克·W·雷(Jack W.
- 谁的语言算作高质量?衡量文本数据选择中的语言意识形态:2022
古尔兰加(Gururangan),Suchin and Card,Dallas和Dreier,Sarah ... 2隐藏... Wang,Zeyu和Zettlemoyer,Luke和Smith,Noah A.
- Glam:具有专家混合物的语言模型的有效缩放:2022
du,nan and huang,yanping和dai,安德鲁·M ... 21隐藏...
- 训练数据预处理指南:测量数据年龄,域覆盖范围,质量和毒性的影响:2023
Shayne Longpre和Gregory Yauney和Emily Reif ... 5隐藏... Kevin Robinson和David Mimno和Daphne Ippolito
- 通过重要性重采样的语言模型数据选择:2023
唱歌迈克尔·西(Michael Xie)和志巴尼·桑特卡(Shibani Santurkar)和坦古(Tengyu)
- Falcon LLM的精制网络数据集:胜过Web数据的策划Corpora,仅Web数据:2023
Guilherme Penedo和Quentin Malartic和Daniel Hesslow ... 3隐藏... Baptiste Pannier和Ebtesam Almazrouei和Julien Launay
- Dolma:用于语言模型预处理研究的三亿代币的开放语料库:2024
卢卡·索尔纳尼(Luca Soldaini)和罗德尼·金尼(Rodney Kinney)和阿克希塔·巴吉亚(Akshita Bhagia)... 30隐藏... Dirk Groeneveld和Jesse Dodge和Kyle Lo
- 编程每个示例:提升预培训的数据质量,例如专家,规模:2024
Fan Zhou和Zengzhi Wang和Qian Liu和Junlong Li和Pengfei Liu
特定于域的选择
返回目录
- 特定领域的语言模型的文本数据采集:2006
Sethy,Abhinav和Georgiou,Panayiotis G.和Narayanan,Shrikanth
- 语言模型培训的智能选择数据:2010年
摩尔,罗伯特·C和刘易斯,威廉
- 语言模型培训的愤世嫉俗选择数据:2017
Amittai Axelrod
- 自动文档选择有效编码器预审计:2022
Feng,Yukun和Xia,Patrick和Van Durme,Benjamin和Sedoc,Jo〜Ao
- 通过重要性重采样的语言模型数据选择:2023
唱歌迈克尔·西(Michael Xie)和志巴尼·桑特卡(Shibani Santurkar)和坦古(Tengyu)
- DSDM:使用DataModels选择模型吸引数据集:2024
Logan Engstrom和Axel Feldmann和Aleksander Madry
数据删除
返回目录
- 带有允许错误的哈希编码中的空间/时间权衡:1970
布卢姆,伯顿H.
- 后缀阵列:一种用于在线字符串搜索的新方法:1993
Manber,Udi和Myers,Gene
- 关于文件的相似和遏制:1997
布罗德,亚利桑那州
- 圆形算法的相似性估计技术:2002
Charikar,MosesS。
- 网站删除网页的URL归一化:2009年
Agarwal,Amit和Koppula,Hema Swetha和Leela,Krishna P .... 3 Hidden ... Haty,Chittaranjan和Roy,Anirban和Sasturkar,Amit
- 在中等至低资源基础设施上处理大量语料库的异步管道:2019年
Pedro Javier Ortiz Su'arez和Beno^IT Sagot和Laurent Romary
- 语言模型是很少的学习者:2020
布朗,汤姆和曼恩,本杰明和莱德,尼克... 25隐藏...拉德福德,亚历克和萨斯克弗,伊利亚和阿莫迪,达里奥
- 堆:语言建模的800GB数据集:2020
Leo Gao和Stella Biderman和Sid Black ... 6隐藏... Noa Nabeshima和Shawn Presser和Connor Leahy
- CCNET:从Web爬网提取高质量的单语数据集:2020
Wenzek,Guillaume和Lachaux,Marie-Anne和Conneau,Alexis ... 1隐藏... Guzm'an,Francisco和Joulin,Armand and Grave,Edouard
- 超越神经缩放法律:通过数据修剪来击败功率定律缩放:2022
Ben Sorscher和Robert Geirhos和Shashank Shekhar和Surya Ganguli和Ari S. Morcos
- 重复培训数据使语言模型更好:2022
Lee,Katherine和Ippolito,Daphne和Nystrom,Andrew ... 1 Hidden ... Eck,Douglas和Callison-Burch,Chris和Carlini,Nicholas
- MTEB:大量文本嵌入基准:2022
Muennighoff,Niklas和Tazi,Nouamane和Magne,Lo“ IC和Reimers,Nils
- 棕榈:用途径缩放语言建模:2022
Aakanksha Chowdhery和Sharan Narang和Jacob Devlin ... 61 Hissed ... Jeff Dean和Slav Petrov和Noah Fiedel
- 缩放语言模型:训练Gopher的方法,分析和见解:2022
杰克·W·雷(Jack W.
- SGPT:语义搜索的GPT句子嵌入:2022
Muennighoff,Niklas
- Bigscience根源语料库:1.6TB复合多语言数据集:2022
Laurenccon,Hugo和Saulnier,Lucile和Wang,Thomas ... 48 Hidden ... Mitchell,Margaret和Luccioni,Sasha Alexandra和Jernite,Yacine,Yacine
- C包:包装资源以推进一般中国嵌入:2023
Xiao,Shitao和Liu,Zheng和Zhang,Peitian和Muennighoff,Niklas
- D4:通过文档删除和多元化改进LLM训练:2023
Kushal Tirumala和Daniel Simig和Armen Aghajanyan和Ari S. Morcos
- 大规模大规模近二次大规模的大规模码头:2023
谅解备忘录
- Paloma:评估语言模型拟合的基准:2023
Ian Magnusson和Akshita Bhagia和Valentin Hofmann ... 10隐藏... Noah A. Smith和Kyle Richardson和Jesse Dodge
- 跨神经语言模型量化记忆:2023
Nicholas Carlini和Daphne Ippolito和Matthew Jagielski和Katherine Lee以及Florian Tramer和Chiyuan Zhang
- SEMDEDUP:通过语义重复数据删除在网络尺度上的数据效率学习:2023
Abbas,Amro和Tirumala,Kushal和Simig,D'Aniel和Ganguli,Surya和Morcos,Ari S
- Falcon LLM的精制网络数据集:胜过Web数据的策划Corpora,仅Web数据:2023
Guilherme Penedo和Quentin Malartic和Daniel Hesslow ... 3隐藏... Baptiste Pannier和Ebtesam Almazrouei和Julien Launay
- 我的大数据是什么?:2023
Elazar,Yanai和Bhagia,Akshita和Magnusson,Ian ... 5隐藏... Soldaini,Luca和Singh,Sameer等
- Dolma:用于语言模型预处理研究的三亿代币的开放语料库:2024
卢卡·索尔纳尼(Luca Soldaini)和罗德尼·金尼(Rodney Kinney)和阿克希塔·巴吉亚(Akshita Bhagia)... 30隐藏... Dirk Groeneveld和Jesse Dodge和Kyle Lo
- 生成代表性指令调整:2024
Muennighoff,Niklas和Su,Hongjin和Wang,Liang ... 2 Hidden ... Yu,Tao和Singh,Amanpreet和Kiela,Douwe
过滤有毒和明确的内容
返回目录
- 通过统一的文本到文本变压器探索转移学习的限制:2020
拉斐尔,科林和谢瑟,诺阿姆和罗伯茨,亚当... 3隐藏... Zhou,Yanqi和Li,Wei和Liu,Peter J.
- MT5:大规模多语言预训练的文本到文本变压器:2021
Xue,linting and Constant,Noah and Roberts,Adam ... 2隐藏... Siddhant,Aditya和Barua,Aditya和Raffel,Colin
- 受到质量的困惑:一种基于困惑的成人和有害内容检测的方法,在多语言异构网络数据中:2022
蒂姆·詹森(Tim Jansen)和扬(Yangling Tong)和维多利亚·泽瓦洛斯(Victoria Zevallos)和佩德罗·奥尔蒂斯(Pedro Ortiz Suarez)
- 缩放语言模型:训练Gopher的方法,分析和见解:2022
杰克·W·雷(Jack W.
- Bigscience根源语料库:1.6TB复合多语言数据集:2022
Laurenccon,Hugo和Saulnier,Lucile和Wang,Thomas ... 48 Hidden ... Mitchell,Margaret和Luccioni,Sasha Alexandra和Jernite,Yacine,Yacine
- 谁的语言算作高质量?衡量文本数据选择中的语言意识形态:2022
古尔兰加(Gururangan),Suchin and Card,Dallas和Dreier,Sarah ... 2隐藏... Wang,Zeyu和Zettlemoyer,Luke和Smith,Noah A.
- 训练数据预处理指南:测量数据年龄,域覆盖范围,质量和毒性的影响:2023
Shayne Longpre和Gregory Yauney和Emily Reif ... 5隐藏... Kevin Robinson和David Mimno和Daphne Ippolito
- AI图像培训数据集发现包括儿童性虐待图像:2023
大卫,艾米莉亚
- 检测培训语料库中的个人信息:分析:2023
Subramani,Nishant和Luccioni,Sasha和Dodge,Jesse和Mitchell,Margaret
- GPT-4技术报告:2023
Openai和:还有Josh Achiam ... 276 Hidden ... Juntang Zhuang和William Zhuk和Barret Zoph
- Santacoder:不要伸手去拿星星!:2023
Allal,Loubna Ben和Li,Raymond和Kocetkov,Denis ... 5隐藏... Gu,Alex和Dey,Manan等
- Falcon LLM的精制网络数据集:胜过Web数据的策划Corpora,仅Web数据:2023
Guilherme Penedo和Quentin Malartic和Daniel Hesslow ... 3隐藏... Baptiste Pannier和Ebtesam Almazrouei和Julien Launay
- 基础模型透明度指数:2023
Bommasani,Rishi和Klyman,Kevin和Longpre,Shayne ... 2 Hidden ... Xiong,Betty和Zhang,Daniel和Liang,Percy
- 我的大数据是什么?:2023
Elazar,Yanai和Bhagia,Akshita和Magnusson,Ian ... 5隐藏... Soldaini,Luca和Singh,Sameer等
- Dolma:用于语言模型预处理研究的三亿代币的开放语料库:2024
卢卡·索尔纳尼(Luca Soldaini)和罗德尼·金尼(Rodney Kinney)和阿克希塔·巴吉亚(Akshita Bhagia)... 30隐藏... Dirk Groeneveld和Jesse Dodge和Kyle Lo
- Olmo:加速语言模型的科学:2024
Groeneveld,Dirk和Beltagy,Iz和Walsh,Pete ... 5隐藏... Magnusson,Ian和Wang,Yizhong等人
多语言模型的专业选择
返回目录
- Bloom:176B参数开放式访问多语言模型:2022
车间,Bigscience和Scao,Teven Le和Fan,Angela ... 5隐藏... Luccioni,Alexandra Sasha和Yvon,Franccois等
- 一目了然的质量:对网络爬行的多语言数据集的审核:2022
Kreutzer,Julia和Caswell,Isaac和Wang,Lisa ... 46 Hidden ... Ahia,Oghenefego和Agrawal,Sweta和Adeyemi,Mofetoluwa
- Bigscience根源语料库:1.6TB复合多语言数据集:2022
Laurenccon,Hugo和Saulnier,Lucile和Wang,Thomas ... 48 Hidden ... Mitchell,Margaret和Luccioni,Sasha Alexandra和Jernite,Yacine,Yacine
- 如果您有100万个GPU小时,可以训练哪种语言模型?:2022
Scao,Teven Le和Wang,Thomas和Hesslow,Daniel ... 5隐藏... Muennighoff,Niklas和Phang,Jason等人
- MADLAD-400:多语言和文档级的大型审计数据集:2023
Kudugunta,Sneha和Caswell,Isaac和Zhang,Biao ... 5隐藏... Stella,Romi和Bapna,Ankur等
- 在受限数据下缩放多语言模型:2023
Scao,Teven Le
- AYA数据集:用于多语言指令调整的开放访问集合:2024
Shivalika Singh和Freddie Vargus和Daniel Dsouza ... 27隐藏... Ahmetüstün和Marzieh Fadaee和Sara Hooker
数据混合
返回目录
- 非策略多型强盗问题:2002
Auer,Peter和Cesa-Bianchi,Nicol`o和Freund,Yoav和Schapire,Robert E.
- 分配强大的语言建模:2019年
Oren,Yonatan和Sagawa,Shiori和Hashimoto,Tatsunori B.和Liang,Percy
- 分布强大的神经网络:2020
Shiori Sagawa和Pang Wei Koh和Tatsunori B. Hashimoto和Percy Liang
- 通过统一的文本到文本变压器探索转移学习的限制:2020
拉斐尔,科林和谢瑟,诺阿姆和罗伯茨,亚当... 3隐藏... Zhou,Yanqi和Li,Wei和Liu,Peter J.
- 堆:语言建模的800GB数据集:2020
Leo Gao和Stella Biderman和Sid Black ... 6隐藏... Noa Nabeshima和Shawn Presser和Connor Leahy
- 缩放语言模型:训练Gopher的方法,分析和见解:2022
杰克·W·雷(Jack W.
- Glam:具有专家混合物的语言模型的有效缩放:2022
du,nan and huang,yanping和dai,安德鲁·M ... 21隐藏...
- 跨语言监督改善了大型语言模型预培训:2023
Andrea Schioppa和Xavier Garcia和Orhan Firat
- [DOGE:域重新加权估计](https://arxiv.org/abs/arxiv Preprint):2023
Simin Fan和Matteo Pagliardini和Martin Jaggi
- doremi:优化数据混合物加快语言模型预测:2023
唱歌迈克尔·西(Michael Xie)和hieu pham和xuanyi dong ... 4隐藏...
- 语言模型预培训的有效在线数据混合:2023
阿隆·阿尔巴克(Alon Albalak)和liangming pan和Colin Raffel和William Yang Wang
- 骆驼:开放有效的基础语言模型:2023
Hugo Touvron和Thibaut Lavril和Gautier Izacard ... 8隐藏... Armand Joulin和Edouard Grave和Guillaume Lample
- 腓热:用于分析跨培训和缩放的大型语言模型的套件:2023
Biderman,Stella和Schoelkopf,Hailey和Anthony,Quentin Gregory ... 7 Hidden ... Skowron,Aviya和Sutawika,Lintang和Van der Wal,Oskar
- 扩展数据受限的语言模型:2023
Niklas Muennighoff和Alexander M Rush和Boaz Barak ... 3隐藏... Sampo Pyysalo和Thomas Wolf和Colin Raffel
- 剪切骆驼:通过结构化修剪预训练的加速语言模型:2023
Mengzhou Xia和Tianyu Gao和Zhiyuan Zeng和Danqi Chen
- 技巧!数据驱动的理解和培训语言模型的技能框架:2023
Mayee F. Chen和Nicholas Roberts和Kush Bhatia ... 1隐藏... Ce Zhang和Frederic Sala和ChristopherRé
指导调查和多任务培训的数据选择
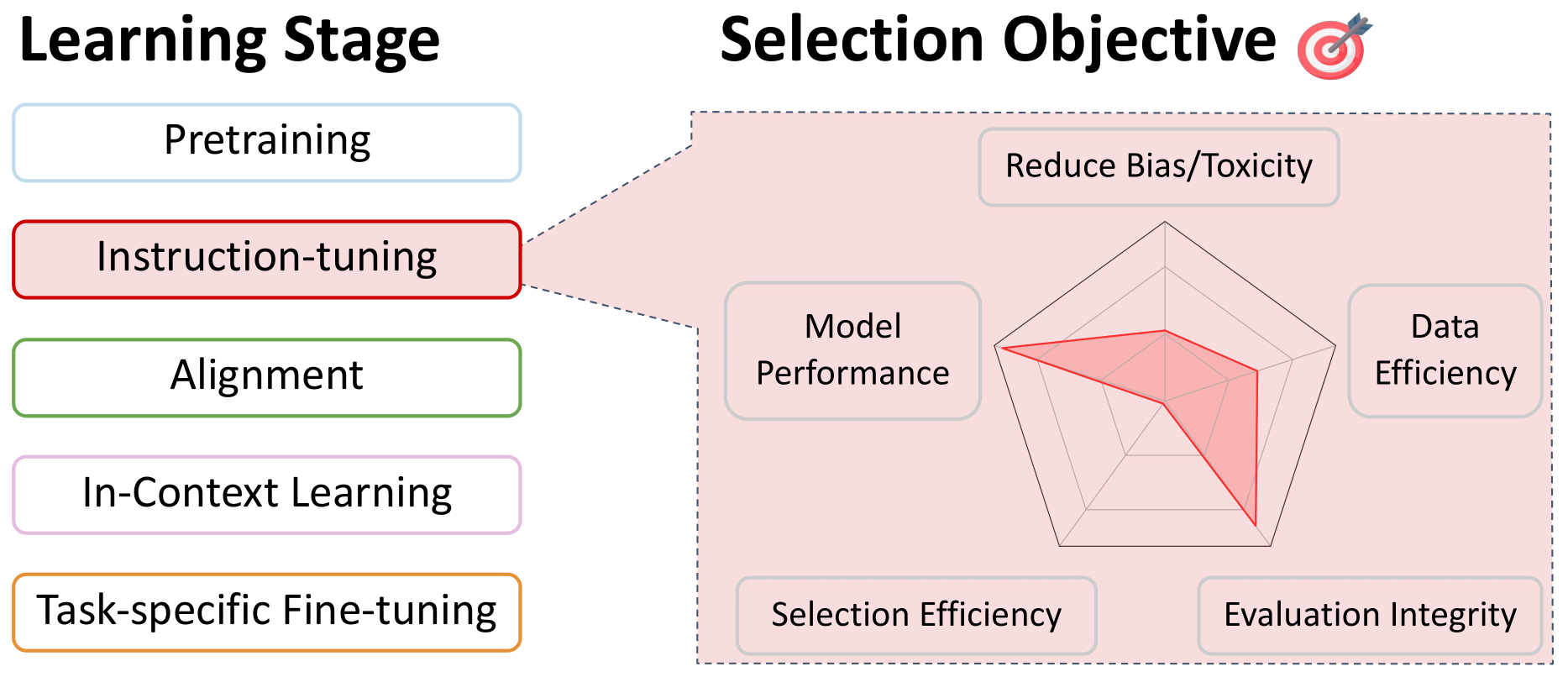
返回目录
- 自然语言十项全能:多任务学习作为问题回答:2018
McCann,Bryan和Keskar,Nitish Shirish和Xiong,Caiming and Socher,Richard
- 通过跨度提取:2019
Keskar,Nitish Shirish和McCann,Bryan和Xiong,Caiming and Socher,Richard
- 自然语言理解的多任务深度神经网络:2019
Liu,Xiaodong和他,Pengcheng和Chen,Weizhu和Gao,Jianfeng
- UNIFIEDQA:与单个质量检查系统的交叉格式边界:2020
卡沙比(Khashabi),丹尼尔(Daniel)和敏(Min),塞顿(Sewon)和霍特(Khot)
- 通过统一的文本到文本变压器探索转移学习的限制:2020
拉斐尔,科林和谢瑟,诺阿姆和罗伯茨,亚当... 3隐藏... Zhou,Yanqi和Li,Wei和Liu,Peter J.
- Muppet:大量的多任务表示,预注:2021
Aghajanyan,Armen和Gupta,Anchit和Shrivastava,Akshat和Chen,Xilun和Zettlemoyer,Luke和Gupta,Sonal
- 填充语言模型是零拍的学习者:2021
Wei,Jason和Bosma,Maarten和Zhao,Vincent Y .... 3 Hidden ... Du,Nan和Dai,Andrew M.和Le,Quoc V.
- 通过自然语言众包指令的跨任务概括:2021
Mishra,Swaroop和Khashabi,Daniel和Baral,Chitta和Hajishirzi,Hannaneh
- NL-Aigmenter:任务敏感的自然语言增强框架:2021
Dhole,Kaustubh D和Gangal,Varun和Gehrmann,Sebastian ... 5隐藏... Shrivastava,Ashish and Tan,Samson等
- EXT5:迈向转移学习的极端多任务缩放:2021
Aribandi,Vamsi和Tay,Yi和Schuster,Tal ... 5隐藏... Bahri,Dara和Ni,Jianmo等
- 超天然结构:1600+ NLP任务的声明说明的概括:2022
王,Yizhong和Mishra,Swaroop和Alipoormolabashi,Pegah ... 29 Hidden ... Patro,Sumanta和Dixit,Tanay and Shen,Xudong
- 缩放指令 - 限制语言模型:2022
Chung,Hyung Won和Hou,Le和Longpre,Shayne ... 5隐藏... Dehghani,Mostafa和Brahma,Siddhartha等
- bloom+ 1:为零射击提示添加语言支持:2022
Yong,Zheng-Xin和Schoelkopf,Hailey和Muennighoff,Niklas ... 5隐藏... Kasai,Jungo和Baruwa,Ahmed等人
- OPT-IML:缩放语言模型指令通过概括的镜头学习元学习:2022
Srinivasan Iyer和XI Victoria Lin和Ramakanth Pasunuru ... 12 Hissed ... Asli Celikyilmaz和Luke Zettlemoyer和Ves Stoyanov
- metaicl:学习在上下文中学习:2022
Min,Sewon和Lewis,Mike和Zettlemoyer,Luke和Hajishirzi,Hannaneh
- 不自然的说明:使用(几乎)没有人工劳动的调整语言模型:2022
Honovich,或Scialom,Thomas和Levy,Omer和Schick,Timo
- 通过多任务登录的跨语言概括:2022
Muennighoff,Niklas和Wang,Thomas和Sutawika,Lintang ... 5隐藏... Yong,Zheng-Xin和Schoelkopf,Hailey等
- 多任务提示培训启用零射击任务概括:2022
Victor Sanh和Albert Webson和Colin Raffel ... 34 Hidden ... Leo Gao和Thomas Wolf和Alexander M Rush
- Prometheus:在语言模型中诱导细粒度的评估能力:2023
Kim,Seungone和Shin,Jamin和Cho,Yejin ... 5隐藏... Kim,Sungdong和Thorne,James等人
- Slimorca:GPT-4增强Flan推理痕迹的开放数据集,并进行验证:2023
Wing Lian和Guan Wang和Bleys Goodson ... 1隐藏... Austin Cook和Chanvichet Vong和“ Teknium”
- AI艺术是从艺术家那里窃取的吗?:2023
Chayka,凯尔
- Paul Tremblay,Mona Awad vs. Openai,Inc。等:2023
Saveri,Joseph R.和Zirpoli,Cadio和Young,Christopher KL和McMahon,Kathleen J.
- 使大型语言模型更好地数据创建者:2023
Lee,Dong-Ho和Pujara,Jay和Sewak,Mohit和White,Ryen和Jauhar,Sujay
- Flan Collection:设计有效指令调整的数据和方法:2023
Shayne Longpre和Le Hou和Tu Vu ... 5隐藏... Barret Zoph和Jason Wei和Adam Roberts
- wizardlm:授权大语言模型遵循复杂说明:2023
XU,Can和Sun,Qingfeng和Zheng,Kai ... 2隐藏... Feng,Jiazhan和Tao,Chongyang和Jiang,Daxin
- 利马:更少的对齐方式:2023
Chunting Zhou和Pengfei Liu和Puxin Xu ... 9隐藏... Mike Lewis和Luke Zettlemoyer和Omer Levy
- 骆驼在变化的气候下:用图卢2:2023增强LM适应
Hamish Ivison和Yizhong Wang和Valentina Pyatkin ... 5隐藏... Noah A. Smith和Iz Beltagy和Hannaneh Hajishirzi
- 自我建造:与自我生成的说明结合语言模型:2023
Wang,Yizhong和Kordi,Yeganeh和Mishra,Swaroop ... 1隐藏... Smith,Noah A.和Khashabi,Daniel和Hajishirzi,Hannaneh
- 是什么使良好的数据保持对齐?对教学调整中自动数据选择的全面研究:2023
Liu,Wei和Zeng,Weihao和他,Keqing和Jiang,Yong和他,Junxian
- 大型语言模型的说明调整:调查:2023
Shengyu Zhang和Linfeng Dong和Xiaoya Li ... 5隐藏... Tianwei Zhang和Fei Wu和Guoyin Wang
- 斯坦福羊驼:遵循的指导骆驼模型:2023
Rohan Taori和Ishaan Gulrajani和Tianyi Zhang ... 2隐藏... Carlos Guestrin和Percy Liang和Tatsunori B. Hashimoto
- 骆驼可以走多远?在开放资源上探索教学状态调整:2023
Yizhong Wang和Hamish Ivison和Pradeep Dasigi ... 5隐藏... Noah A. Smith和Iz Beltagy和Hannaneh Hajishirzi
- 开放式对话 - 大众化大语言模型对准:2023
K“ OPF,Andreas和Kilcher,Yannic和Von R” Utte,Dimitri ... 5隐藏... Stanley,Oliver和Nagyfi,Rich'ard等人
- 章鱼:指令调整代码大语言模型:2023
Niklas Muennighoff和Qian Liu和Armel Zebaze ... 4隐藏... Xiangru Tang和Leandro von Werra和Shayne Longpre
- 自我:大语模型的语言驱动自我进化:2023
Lu,Jianqiao和Zhong,Wanjun和Huang,Wenyong ... 3隐藏... Wang,Weichao and Shang,Lifeng and Liu,Qun
- Flan Collection:设计有效指令调整的数据和方法:2023
Longpre,Shayne和Hou,Le和Vu,Tu ... 5隐藏... Zoph,Barret和Wei,Jason和Roberts,Adam
- #Instag:用于分析大语模型监督微调的指令标签:2023
Keming Lu和Hongyi Yuan和Zheng Yuan ... 2隐藏... Chuanqi Tan和Chang Zhou和Jingren Zhou
- 指令挖掘:当数据挖掘符合大语言模型列表时:2023
Yihan Cao和Yanbin Kang和Chi Wang和Lichao Sun
- 主动说明调整:通过迅速敏感任务进行培训改善交叉任务概括:2023
Po-nien功夫和范元,Di Wu和Kai-Wei Chang和Nanyun Peng
- 数据出处倡议:AI:2023中的数据集许可和归因的大规模审核
Longpre,Shayne和Mahari,Robert和Chen,Anthony ... 5隐藏... Kabbara,Jad和Perisetla,Kartik等人
- AYA数据集:用于多语言指令调整的开放访问集合:2024
Shivalika Singh和Freddie Vargus和Daniel Dsouza ... 27隐藏... Ahmetüstün和Marzieh Fadaee和Sara Hooker
- Astraios:参数效率指令调谐代码大语言模型:2024
Zhuo,Terry Yue和Zebaze,Armel和Suppattarachai,Nitchakarn ... 1隐藏... De Vries,Harm and Liu,Qian和Muennighoff,Niklas
- AYA模型:指令固定的开放访问多语言模型:2024
“ ust” Un,Ahmet和Aryabumi,Viraat和Yong,Zheng-Xin ... 5隐藏... ooi,Hui-Lee和Kayid,AMR,AMR等
- 较小的语言模型能够为较大语言模型选择指令调整培训数据:2024
Dheeraj Mekala和Alex Nguyen和Jingbo Shang
- 可靠语言模型微调的自动数据策划:2024
圣战和乔纳斯·穆勒
偏好微调的数据选择:对齐
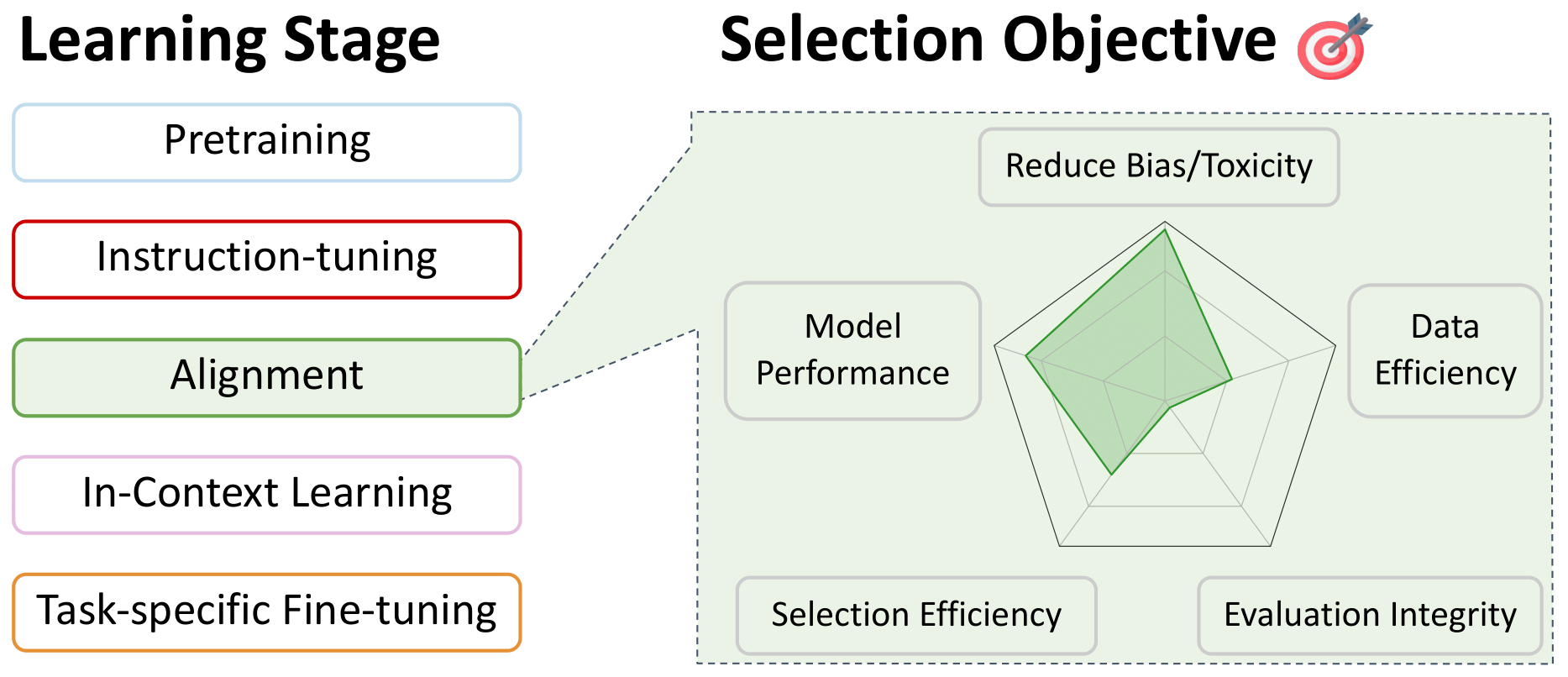
返回目录
- Webgpt:通过人类反馈的浏览器协助提问:2021
中ano,瑞奇罗和希尔顿,雅各布和巴拉吉
- 通过从人类反馈中学习的有用且无害的助手培训一位有益而无害的助手:2022
Bai,Yuntao和Jones,Andy and Ndousse,Kamal ... 5隐藏... Ganguli,Deep和Henighan,Tom和其他人
- 了解数据集难度使用$ Mathcalv $ - 可使用的信息:2022
Ethayarajh,Kawin和Choi,Yejin和Swayamdipta,Swabha
- 宪法AI:AI反馈的无害性:2022
Bai,Yuntao和Kadavath,Saurav和Kundu,Sandipan ... 5隐藏... Mirhoseini,Azalia和McKinnon,Cameron等
- Prometheus:在语言模型中诱导细粒度的评估能力:2023
Kim,Seungone和Shin,Jamin和Cho,Yejin ... 5隐藏... Kim,Sungdong和Thorne,James等人
- Notus:2023
Alvaro Bartolome和Gabriel Martin和Daniel Vila
- Ultrefeppback:具有高质量反馈的增强语言模型:2023
Ganqu Cui and Lifan Yuan and Ning Ding... 3 hidden ... Guotong Xie and Zhiyuan Liu and Maosong Sun
- Exploration with Principles for Diverse AI Supervision: 2023
Liu, Hao and Zaharia, Matei and Abbeel, Pieter
- Wizardlm: Empowering large language models to follow complex instructions: 2023
Xu, Can and Sun, Qingfeng and Zheng, Kai... 2 hidden ... Feng, Jiazhan and Tao, Chongyang and Jiang, Daxin
- LIMA: Less Is More for Alignment: 2023
Chunting Zhou and Pengfei Liu and Puxin Xu... 9 hidden ... Mike Lewis and Luke Zettlemoyer and Omer Levy
- Shepherd: A Critic for Language Model Generation: 2023
Tianlu Wang and Ping Yu and Xiaoqing Ellen Tan... 4 hidden ... Luke Zettlemoyer and Maryam Fazel-Zarandi and Asli Celikyilmaz
- No Robots: 2023
Nazneen Rajani and Lewis Tunstall and Edward Beeching and Nathan Lambert and Alexander M. Rush and Thomas Wolf
- Starling-7B: Improving LLM Helpfulness & Harmlessness with RLAIF: 2023
Zhu, Banghua and Frick, Evan and Wu, Tianhao and Zhu, Hanlin and Jiao, Jiantao
- Scaling laws for reward model overoptimization: 2023
Gao, Leo and Schulman, John and Hilton, Jacob
- SALMON: Self-Alignment with Principle-Following Reward Models: 2023
Zhiqing Sun and Yikang Shen and Hongxin Zhang... 2 hidden ... David Cox and Yiming Yang and Chuang Gan
- Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback: 2023
Stephen Casper and Xander Davies and Claudia Shi... 26 hidden ... David Krueger and Dorsa Sadigh and Dylan Hadfield-Menell
- Camels in a Changing Climate: Enhancing LM Adaptation with Tulu 2: 2023
Hamish Ivison and Yizhong Wang and Valentina Pyatkin... 5 hidden ... Noah A. Smith and Iz Beltagy and Hannaneh Hajishirzi
- Llama 2: Open Foundation and Fine-Tuned Chat Models: 2023
Hugo Touvron and Louis Martin and Kevin Stone... 62 hidden ... Robert Stojnic and Sergey Edunov and Thomas Scialom
- What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning: 2023
Liu, Wei and Zeng, Weihao and He, Keqing and Jiang, Yong and He, Junxian
- HuggingFace H4 Stack Exchange Preference Dataset: 2023
Lambert, Nathan and Tunstall, Lewis and Rajani, Nazneen and Thrush, Tristan
- Textbooks Are All You Need: 2023
Gunasekar, Suriya and Zhang, Yi and Aneja, Jyoti... 5 hidden ... de Rosa, Gustavo and Saarikivi, Olli and others
- Quality-Diversity through AI Feedback: 2023
Herbie Bradley and Andrew Dai and Hannah Teufel... 4 hidden ... Kenneth Stanley and Grégory Schott and Joel Lehman
- Direct preference optimization: Your language model is secretly a reward model: 2023
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Ermon, Stefano and Manning, Christopher D and Finn, Chelsea
- Scaling relationship on learning mathematical reasoning with large language models: 2023
Yuan, Zheng and Yuan, Hongyi and Li, Chengpeng and Dong, Guanting and Tan, Chuanqi and Zhou, Chang
- The History and Risks of Reinforcement Learning and Human Feedback: 2023
Lambert, Nathan and Gilbert, Thomas Krendl and Zick, Tom
- Zephyr: Direct distillation of lm alignment: 2023
Tunstall, Lewis and Beeching, Edward and Lambert, Nathan... 5 hidden ... Fourrier, Cl'ementine and Habib, Nathan and others
- Perils of Self-Feedback: Self-Bias Amplifies in Large Language Models: 2024
Wenda Xu and Guanglei Zhu and Xuandong Zhao and Liangming Pan and Lei Li and William Yang Wang
- Suppressing Pink Elephants with Direct Principle Feedback: 2024
Louis Castricato and Nathan Lile and Suraj Anand and Hailey Schoelkopf and Siddharth Verma and Stella Biderman
- West-of-N: Synthetic Preference Generation for Improved Reward Modeling: 2024
Alizée Pace and Jonathan Mallinson and Eric Malmi and Sebastian Krause and Aliaksei Severyn
- Statistical Rejection Sampling Improves Preference Optimization: 2024
Liu, Tianqi and Zhao, Yao and Joshi, Rishabh... 1 hidden ... Saleh, Mohammad and Liu, Peter J and Liu, Jialu
- Self-play fine-tuning converts weak language models to strong language models: 2024
Chen, Zixiang and Deng, Yihe and Yuan, Huizhuo and Ji, Kaixuan and Gu, Quanquan
- Self-Rewarding Language Models: 2024
Weizhe Yuan and Richard Yuanzhe Pang and Kyunghyun Cho and Sainbayar Sukhbaatar and Jing Xu and Jason Weston
- Theoretical guarantees on the best-of-n alignment policy: 2024
Beirami, Ahmad and Agarwal, Alekh and Berant, Jonathan... 1 hidden ... Eisenstein, Jacob and Nagpal, Chirag and Suresh, Ananda Theertha
- KTO: Model Alignment as Prospect Theoretic Optimization: 2024
Ethayarajh, Kawin and Xu, Winnie and Muennighoff, Niklas and Jurafsky, Dan and Kiela, Douwe
Data Selection for In-Context Learning
Back to Table of Contents
- Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks: 2019
Reimers, Nils and Gurevych, Iryna
- Language Models are Few-Shot Learners: 2020
Brown, Tom and Mann, Benjamin and Ryder, Nick... 25 hidden ... Radford, Alec and Sutskever, Ilya and Amodei, Dario
- True Few-Shot Learning with Language Models: 2021
Ethan Perez and Douwe Kiela and Kyunghyun Cho
- Active Example Selection for In-Context Learning: 2022
Zhang, Yiming and Feng, Shi and Tan, Chenhao
- Careful Data Curation Stabilizes In-context Learning: 2022
Chang, Ting-Yun and Jia, Robin
- Learning To Retrieve Prompts for In-Context Learning: 2022
Rubin, Ohad and Herzig, Jonathan and Berant, Jonathan
- Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity: 2022
Lu, Yao and Bartolo, Max and Moore, Alastair and Riedel, Sebastian and Stenetorp, Pontus
- What Makes Good In-Context Examples for GPT-3?: 2022
Liu, Jiachang and Shen, Dinghan and Zhang, Yizhe and Dolan, Bill and Carin, Lawrence and Chen, Weizhu
- MetaICL: Learning to Learn In Context: 2022
Min, Sewon and Lewis, Mike and Zettlemoyer, Luke and Hajishirzi, Hannaneh
- Unified Demonstration Retriever for In-Context Learning: 2023
Li, Xiaonan and Lv, Kai and Yan, Hang... 3 hidden ... Xie, Guotong and Wang, Xiaoling and Qiu, Xipeng
- Which Examples to Annotate for In-Context Learning? Towards Effective and Efficient Selection: 2023
Mavromatis, Costas and Srinivasan, Balasubramaniam and Shen, Zhengyuan... 1 hidden ... Rangwala, Huzefa and Faloutsos, Christos and Karypis, George
- Large Language Models Are Latent Variable Models: Explaining and Finding Good Demonstrations for In-Context Learning: 2023
Xinyi Wang and Wanrong Zhu and Michael Saxon and Mark Steyvers and William Yang Wang
- Selective Annotation Makes Language Models Better Few-Shot Learners: 2023
Hongjin SU and Jungo Kasai and Chen Henry Wu... 5 hidden ... Luke Zettlemoyer and Noah A. Smith and Tao Yu
- In-context Example Selection with Influences: 2023
Nguyen, Tai and Wong, Eric
- Coverage-based Example Selection for In-Context Learning: 2023
Gupta, Shivanshu and Singh, Sameer and Gardner, Matt
- Compositional exemplars for in-context learning: 2023
Ye, Jiacheng and Wu, Zhiyong and Feng, Jiangtao and Yu, Tao and Kong, Lingpeng
- Take one step at a time to know incremental utility of demonstration: An analysis on reranking for few-shot in-context learning: 2023
Hashimoto, Kazuma and Raman, Karthik and Bendersky, Michael
- Ambiguity-aware in-context learning with large language models: 2023
Gao, Lingyu and Chaudhary, Aditi and Srinivasan, Krishna and Hashimoto, Kazuma and Raman, Karthik and Bendersky, Michael
- IDEAL: Influence-Driven Selective Annotations Empower In-Context Learners in Large Language Models: 2023
Zhang, Shaokun and Xia, Xiaobo and Wang, Zhaoqing... 1 hidden ... Liu, Jiale and Wu, Qingyun and Liu, Tongliang
- ScatterShot: Interactive In-context Example Curation for Text Transformation: 2023
Wu, Sherry and Shen, Hua and Weld, Daniel S and Heer, Jeffrey and Ribeiro, Marco Tulio
- Diverse Demonstrations Improve In-context Compositional Generalization: 2023
Levy, Itay and Bogin, Ben and Berant, Jonathan
- Finding supporting examples for in-context learning: 2023
Li, Xiaonan and Qiu, Xipeng
- Misconfidence-based Demonstration Selection for LLM In-Context Learning: 2024
Xu, Shangqing and Zhang, Chao
- In-context Learning with Retrieved Demonstrations for Language Models: A Survey: 2024
Xu, Xin and Liu, Yue and Pasupat, Panupong and Kazemi, Mehran and others
Data Selection for Task-specific Fine-tuning
Back to Table of Contents
- A large annotated corpus for learning natural language inference: 2015
Bowman, Samuel R. and Angeli, Gabor and Potts, Christopher and Manning, Christopher D.
- GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding: 2018
Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel
- A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference: 2018
Williams, Adina and Nangia, Nikita and Bowman, Samuel
- Sentence Encoders on STILTs: Supplementary Training on Intermediate Labeled-data Tasks: 2019
Jason Phang and Thibault Févry and Samuel R. Bowman
- Distributionally Robust Neural Networks: 2020
Shiori Sagawa and Pang Wei Koh and Tatsunori B. Hashimoto and Percy Liang
- Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics: 2020
Swayamdipta, Swabha and Schwartz, Roy and Lourie, Nicholas... 1 hidden ... Hajishirzi, Hannaneh and Smith, Noah A. and Choi, Yejin
- Intermediate-Task Transfer Learning with Pretrained Language Models: When and Why Does It Work?: 2020
Pruksachatkun, Yada and Phang, Jason and Liu, Haokun... 3 hidden ... Vania, Clara and Kann, Katharina and Bowman, Samuel R.
- On the Complementarity of Data Selection and Fine Tuning for Domain Adaptation: 2021
Dan Iter and David Grangier
- FETA: A Benchmark for Few-Sample Task Transfer in Open-Domain Dialogue: 2022
Albalak, Alon and Tuan, Yi-Lin and Jandaghi, Pegah... 3 hidden ... Getoor, Lise and Pujara, Jay and Wang, William Yang
- LoRA: Low-Rank Adaptation of Large Language Models: 2022
Edward J Hu and yelong shen and Phillip Wallis... 2 hidden ... Shean Wang and Lu Wang and Weizhu Chen
- Training Subset Selection for Weak Supervision: 2022
Lang, Hunter and Vijayaraghavan, Aravindan and Sontag, David
- On-Demand Sampling: Learning Optimally from Multiple Distributions: 2022
Haghtalab, Nika and Jordan, Michael and Zhao, Eric
- The Trade-offs of Domain Adaptation for Neural Language Models: 2022
Grangier, David and Iter, Dan
- Data Pruning for Efficient Model Pruning in Neural Machine Translation: 2023
Azeemi, Abdul and Qazi, Ihsan and Raza, Agha
- Skill-it! A Data-Driven Skills Framework for Understanding and Training Language Models: 2023
Mayee F. Chen and Nicholas Roberts and Kush Bhatia... 1 hidden ... Ce Zhang and Frederic Sala and Christopher Ré
- D2 Pruning: Message Passing for Balancing Diversity and Difficulty in Data Pruning: 2023
Adyasha Maharana and Prateek Yadav and Mohit Bansal
- Improving Few-Shot Generalization by Exploring and Exploiting Auxiliary Data: 2023
Alon Albalak and Colin Raffel and William Yang Wang
- Efficient Online Data Mixing For Language Model Pre-Training: 2023
Alon Albalak and Liangming Pan and Colin Raffel and William Yang Wang
- Data-Efficient Finetuning Using Cross-Task Nearest Neighbors: 2023
Ivison, Hamish and Smith, Noah A. and Hajishirzi, Hannaneh and Dasigi, Pradeep
- Make Every Example Count: On the Stability and Utility of Self-Influence for Learning from Noisy NLP Datasets: 2023
Bejan, Irina and Sokolov, Artem and Filippova, Katja
- LESS: Selecting Influential Data for Targeted Instruction Tuning: 2024
Mengzhou Xia and Sadhika Malladi and Suchin Gururangan and Sanjeev Arora and Danqi Chen
贡献
There are likely some amazing works in the field that we missed, so please contribute to the repo.
Feel free to open a pull request with new papers or create an issue and we can add them for you. Thank you in advance for your efforts!
引用
We hope this work serves as inspiration for many impactful future works. If you found our work useful, please cite this paper as:
@article{albalak2024survey,
title={A Survey on Data Selection for Language Models},
author={Alon Albalak and Yanai Elazar and Sang Michael Xie and Shayne Longpre and Nathan Lambert and Xinyi Wang and Niklas Muennighoff and Bairu Hou and Liangming Pan and Haewon Jeong and Colin Raffel and Shiyu Chang and Tatsunori Hashimoto and William Yang Wang},
year={2024},
journal={arXiv preprint arXiv:2402.16827},
note={url{https://arxiv.org/abs/2402.16827}}
}


